编译原理小测知识点
第一次
- Haskell属于声明式语言。C、C++、JAVA都不是。
- Python不属于静态类型的程序设计语言。C、C++、JAVA都是。
- 对于动态类型的程序设计语言,最主要的特点是在程序运行时对数据类型进行相容性检查。
- 编写编译器的语言称为宿主语言。
- 宿主机的含义是运行编译程序的环境。
- 设计一个编译器时,非必需的阶段是代码优化。必需的阶段有语法分析,词法分析和语义处理。
- 通常情况下采用解释执行方式的是JavaScript。Fortran、C#和C/C++。
- 下列编译器的处理过程中,一遍处理能够完成的是从源代码到中间代码、从源代码到目标代码、从中间代码到中间代码和从中间代码到目标代码。
- 实现一个编译器,必须遵守的原则是等价。
- 经过编译处理的这些阶段,可完成C语言代码“a[index]=12*3;”等价转化为四元式代码“=,36, ,a[index]”,词法分析、语义处理以及中间代码生成、语法分析与代码优化。
第二次:
- 正规式可用于描述词法规则,正规式是正规集的一种表示方式,任何一正规集都可以用正规式表示,正规式与状态自动机可以相互转换。
- 任何一个NFA M都存在一个等价的DFA M’,任何一个正规式都可以转换为一个DFA,任何一个正规式都存在一个对应的NFA。
- ε-closure(I) 的含义是从状态集 I 出发,经过一条或多条 ε 弧所能够达到的状态集。
- 词法分析器的输出是按词法规则识别出的具有独立意义的各类单词。
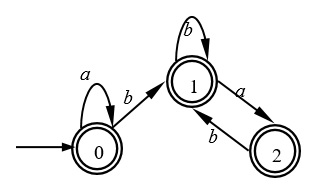
- 该 DFA 识别的语言一定可以用正规式表示,串bababababba被该DFA识别,串bbbbbbbbbaaaaaaaaaa被该DFA拒绝。
- DFA映射函数有唯一性、存在唯一一个初态、状态集合为有限集。DFA可以存在多个终态。
- 定义一个FA,需要给出唯一的开始状态, 有限非空的状态集合Q, 终态集合Z, 状态转换函数f,字母表Σ。
- 可以有多个不同的正规式对应一个正规集的情况,一个正规式对应唯一一个正规集。
- 子集法用于将NFA确定化,划分法用于将DFA最小化。
int main( )
{ printf("hello world.\n");
}
- 对以上程序段词法分析器能够识别出来的单词有main、printf和”hello world.\n”、}。\n与()不是单词。
第三次
- C语言程序预处理过程在词法分析之前完成。
- 词法分析中识别单词时的超前搜索是指识别出单词时,记录的扫描串的后面有不属于该单词的符号。
- C语言符号中分号 ";" 和花括号 "{" 或 "}"能够被词法分析识别为一个单词,而编辑程序用的回车制表符 [ENTER]、编辑程序时使用的制表符 [TAB]、单引号 ’、双引号 ”不能被识别为一个单词。
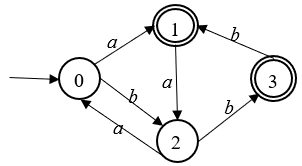
- 对于符号串"aabbababbb",规约机识别出的第一个单词是"aabbab"。
- 词法分析器的自动生成中包含的算法有正规式分解(转NFA)、NFA确定化的子集算法和DFA最小化的合并等价状态算法。DFA最小化的删除无关状态算法不是。
- Lex程序的结构组成部分包括模式宏定义、C语言的说明信息、转换规则和规则动作所需要的辅助过程的C代码。
- 对于C语言语句"a=b++-12.5;",词法分析会识别出7个单词。
- C语言预处理器完成的工作包括删除注释(块注释和行注释)、删除多余的空白符(空格、\t和\n)、进行宏替换和根据条件编译进行源代码裁剪。
- LEX/FLEX的功能是生成用于词法分析的词法分析器源程序。
- 在编译原理中,“单词”指语言中具有独立意义的最小语法单位。
第四次
对于文法 G(S) 的句型 \(\alpha\)(开始符号句型S除外),下列叙述中,正确的是
选择一项或多项:ABCD
A.\(\alpha\)中的直接短语是\(\alpha\)中某个短语的子串
B.\(\alpha\)一定有短语
C.\(\alpha\)中的短语一定是\(\alpha\)的子串
D.\(\alpha\)一定有直接短语
下列关于短语和直接短语的描述中,正确的是
选择一项或多项:ABCD
A.短语对应一个非终结符
B.短语可以归约为一个非终结符号
C.直接短语可以归约为一个非终结符号
D.直接短语对应一个非终结符
下列关于自下而上分析方法的描述中,正确的是
选择一项或多项:ABD
A.自下而上分析正确的结束是把分析的整个符号串归约到文法的开始符号
B.自下而上分析的关键是寻找可归约的子串
C.自下而上分析与自上而下分析构造的分析树不同
D.自下而上分析方法的主要动作是移进和归约
下列关于活前缀的描述中,正确的是
选择一项或多项:AC
A.空串是所有句型的活前缀
B.活前缀中一定包含有句柄
C.句柄一定是最长的活前缀(可归前缀)的一个后缀
D.句柄一定是最长的活前缀(可归前缀)的一个前缀
一文法是 LR(1) 文法而不是 LALR(1) 文法的原因是
选择一项:A
A.存在归约—归约冲突
B.文法是二义文法
C.存在移进—归约冲突
D.文法是左递归文法
A→\(\alpha \cdot\),B→\(\beta \cdot\)属于同一项目集,则有
选择一项:B
A.\(\alpha\)的后缀一定是\(\beta\)的后缀
B.\(\alpha\)是\(\beta\)的后缀,或者\(\beta\)是的\(\alpha\)后缀
C.\(\alpha\)与\(\beta\)一定相同
D.\(\alpha\)的前缀一定是\(\beta\)的前缀
下列关于 LR 分析表的描述中,正确的是
选择一项或多项:BD
A.LR(0) 分析表的 acc 动作可以不考虑向前搜索符
B.所有 LR 分析表的 acc 动作都考虑了向前搜索符
C.LR 分析表的错误处理在 GOTO 表中
D.LR 分析表的错误处理在 ACTION 表中
关于有效活前缀的描述中,正确的是
选择一项或多项:ABD
A.一个LR项目,可以对多个活前缀有效
B.多个LR项目,可以对同一个活前缀有效
C.不同的LR项目,对应不同的有效活前缀
D.有相同的有效活前缀的LR项目一定在同一个项目集中
下面描述中,正确的是
选择一项或多项:BCD
A.利用 LR(0) 分析器与 LR(1) 分析器对同一个语法错误句子进行分析,分析过程肯定一样
B.一文法是 LR(0) 文法,则该文法一定是 LR(1) 文法
C.利用 LR(0) 分析器与 LR(1) 分析器对同一个语法正确的句子进行分析,分析过程肯定一样
D.一文法是 LR(0) 文法,则该文法一定是 SLR(1) 文法
下列关于 LR 类分析器的描述中,正确的是
选择一项或多项:AC
A.LR 分析器是自下而上的语法分析器
B.LR 分析器只能分析 LR 类文法
C.只要没有多重定义的 LR 分析表,就可以使用 LR 分析器分析
D.LR 分析器的符号栈和状态栈缺一不可
第五次
下列关于逆波兰式描述中,错误的是 选择一项:
A. 逆波兰式是中间语言之一
B. 逆波兰式只能表示算术运算
C. 逆波兰式不需要括号
D. 逆波兰表示中不需要规定运算的优先级
B
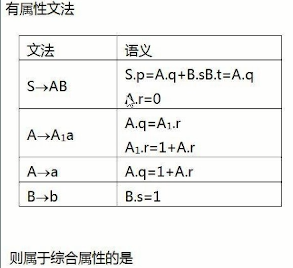
选择一项或多项:
A.A.r
B.B.t
C.B.s
D.S.p
E.A.q
SpBsAq
下列关于种中间语言形式的描述中,正确的是 选择一项或多项:
A. 三元式和四元式的区别是四元式中更适合于两地址机器
B. AST是最接近于语法分析结果的一种表示形式
C. 三元式和间接三元式的区别是间接三元式更适于做优化处理
D. 可用一种中间语言表示的,肯定可用另一种中间语言表示
BCD
下列选项叙述了语义处理过程中需要完成的任务,错误的是 选择一项:
A. 识别语法范畴
B. 产生中间代码
C. 查填符号表
D. 函数形参与实参的匹配检查
A
下列关于符号表的描述中,错误的是 选择一项或多项:
A. 符号表是代码生成时地址分配的依据之一
B. 符号表中记录的信息都是在语义分析阶段收集的
C. 符号表是语义检查的依据之一
D. 符号表中记录的是源程序中各种单词的属性信息
BD
下列说法中,错误的是 选择一项或多项:
A. 数组说明的翻译跟一般说明语句一样,不产生中间代码,只是处理符号表
B. 数组元素引用的语义处理就是计算出地址
C. 标号的使用和定义情况在标号表中没有区别
D. 拉链返填技术是在语句标号先定义后引用的情况下使用的一种技术
BCD

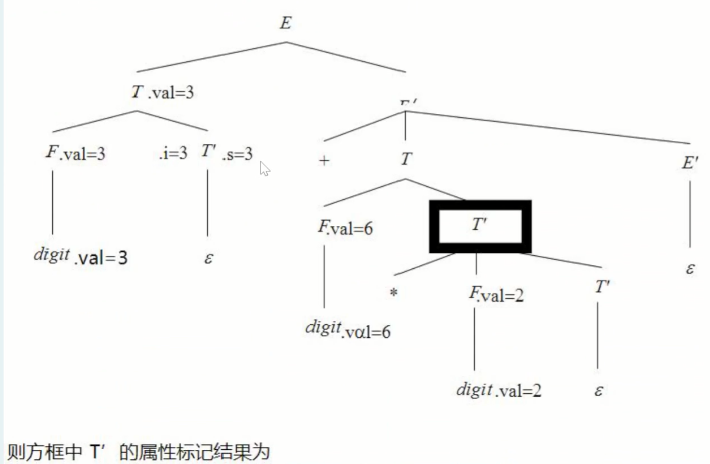
选择一项:
A. .i=6,.s=3
B. .s=12
C. .i=6
D. .i=6,.s=2
A
下列关于语法制导翻译的描述中,正确的是 选择一项或多项:
A. 所有的语法制导翻译方案都可以在语法分析的过程中实现
B. 语法制导定义就是根据语法结构定义语义
C. 所有的语法制导翻译方案都可以通过遍历已构造好的注释语法分析树来实现
D. 语法制导定义可以用属性文法来描述
BCD

CD
语句翻译设计的要点包括 选择一项或多项:
A. 根据目标结构和语义规则,构造合适的SDT或属性翻译文法
B. 根据语义确定语句的目标结构
C. 确定中间代码
D. 涉及的实现技术
ABCD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号