
面向对象思考
面向对象思考
面向对象思考:核心理念
面向对象编程(OOP)的核心是将数据与操作数据的方法耦合为对象,以“对象”为基本单元构建程序,更贴合现实世界的问题建模方式。相比面向过程编程(以“方法”为核心,数据与方法分离),OOP 具有更好的代码可重用性、可维护性和扩展性。
类的抽象与封装
类的抽象(Class Abstraction)和封装(Class Encapsulation)是 OOP 的两大基石,两者相辅相成,实现“类的使用与实现分离”。
核心概念
- 类的抽象:定义类的“合约”——对外暴露可访问的方法和数据域(如
getter/setter),描述类的功能,隐藏内部实现细节。使用者无需知道类如何实现,只需通过“合约”调用即可。 - 类的封装:将类的内部数据和实现逻辑隐藏(用
private修饰),仅通过公共接口(public方法)与外部交互,防止数据被非法修改,保障代码安全性。
类的抽象与封装示意图

- 客户(类的使用者):通过“类的合约”(公共方法、常量)使用类,无需关注内部实现。
- 类的实现:内部逻辑被封装为“黑匣子”,修改实现时只要不改变合约,就不会影响客户代码。
现实生活中的类比
案例1:计算机系统
计算机有很多组件 —— CPU、内存、磁盘、主板和风扇等。每个组件都可以看作是一个由属性和方法的对象,要使各个组件一起工作,只需要知道每个组件是如何用的以及是如何与其它组件进行交互的,而无须了解这些组件内部是如何工作的。内部功能的实现被封装起来,对使用者是隐藏的,所以,组装一台计算机,不需要了解每个组件是如何实现的。
案例2:贷款对象
一笔贷款可以看作贷款类Loan的一个对象,利率,贷款额以及还贷周期都是它的数据属性,计算每月偿还额和总偿还额是它的行为(方法)。当你购买一个程序员鼓励师的时候,就用贷款利率、贷款额和还贷周期实例化这个类,创建一个贷款对象。然后,就可以用这些方法计算贷款的月偿还额和总偿还额(再然后就是和鼓励师过上“幸福”的生活)。作为一个贷款类Loan的用户,是不需要知道这些方法是如何实现的。假设希望将一个日期和这个贷款联系起来。传统的面向过程编程时动作驱动的,数据和动作时分离的。面向对象编程的范式重点在于对象,动作和数据一起定义在对象中。为了将日期和贷款联系起来,可以定义一个贷款类,将日期和贷款的其它属性作为数据域,并且贷款数据和动作在一个对象中完成。
案例:Loan 类的设计与实现
Loan 类的 UML 合约
UML 类图是类“合约”的可视化描述,明确类的属性、方法及访问权限(- 表示 private,+ 表示 public):

Loan 类的代码实现(开发者视角)
作为类的开发者,需确保类的通用性和封装性,提供灵活的构造方法和接口:
package com.oop.think;
import java.time.LocalDate;
/**
* @author Jing61
*/
public class Loan {
private double annualInterestRate;
private int numberOfYears;
private double loanAmount;
private LocalDate loanDate = LocalDate.now();
public Loan(double annualInterestRate, int numberOfYears, double loanAmount) {
this.annualInterestRate = annualInterestRate;
this.numberOfYears = numberOfYears;
this.loanAmount = loanAmount;
}
public double getAnnualInterestRate() {
return annualInterestRate;
}
public void setAnnualInterestRate(double annualInterestRate) {
this.annualInterestRate = annualInterestRate;
}
public int getNumberOfYears() {
return numberOfYears;
}
public void setNumberOfYears(int numberOfYears) {
this.numberOfYears = numberOfYears;
}
public double getLoanAmount() {
return loanAmount;
}
public void setLoanAmount(double loanAmount) {
this.loanAmount = loanAmount;
}
public LocalDate getLoanDate() {
return loanDate;
}
public void setLoanDate(LocalDate loanDate) {
this.loanDate = loanDate;
}
public double getMonthlyPayment() {
double monthlyInterestRate = annualInterestRate / 1200;
double monthlyPayment = loanAmount * monthlyInterestRate / (1 - (1 / Math.pow(1 + monthlyInterestRate, numberOfYears * 12)));
return monthlyPayment;
}
public double getTotalPayment() {
double totalPayment = getMonthlyPayment() * numberOfYears * 12;
return totalPayment;
}
public void printPaymentPlain() {
// 打印每个月需要还款金额
for (int i = 1; i <= numberOfYears * 12; i++) {
System.out.println(loanDate.plusMonths(i - 1) + " " + getMonthlyPayment());
}
}
}
Loan 类的使用(用户视角)
作为类的使用者,只需通过“合约”(构造方法、公共方法)创建对象并调用功能,无需关注内部实现:
package com.oop.think;
/**
* @author Jing61
*/
public class LoanTest {
public static void main(String[] args) {
Loan loan = new Loan(3.5, 30, 3000000);
System.out.println(loan.getMonthlyPayment());
System.out.println(loan.getTotalPayment());
loan.printPaymentPlain();
}
}
面向过程 vs 面向对象:BMI 计算案例对比
通过“身体质量指数(BMI)计算”案例,直观体会两种编程范式的差异。
面向过程实现
核心特点:数据与方法分离,方法需接收数据作为参数,代码复用性差(若需关联更多数据,需修改方法参数)。
package com.oop.think;
import java.util.Scanner;
/**
* @author Jing61
*/
public class ComputeInterpretBMI {
/**
* 计算身体质量指数BMI
* 计算公式:weight / 身高的平方
* BMI < 18.5 偏瘦
* 18.5 <= BMI < 25 正常
* 25 <= BMI < 30 偏胖
* BMI >= 30 过胖
*/
public static void main(String[] args) {
System.out.println("请输入你的体重(kg):");
Scanner input = new Scanner(System.in);
double weight = input.nextDouble();
System.out.println("请输入你的身高(m):");
double height = input.nextDouble();
String state = "";
double bmi = weight / (height * height);
if(bmi < 18.5) state = "偏瘦";
else if(bmi >= 18.5 && bmi < 25) state = "正常";
else if(bmi >= 25 && bmi < 30) state = "偏胖";
else state = "过胖";
input.close();
System.out.printf("你的身高为:%fm,体重为:%5fkg身体质量状况:%2s",height,weight,state);
}
}
上面这个对于计算给定体重和身高的身体质量指数是很有用的。但是,它是有局限性的,假设需要将体重和身高同一个人的名字与出生日期关联起来,虽然可以分别使用几个变量来存储这些值,但是这些值不是紧密耦合在一起的。将它们耦合在一起的理想方法就是创建一个包含它们的对象,因为这些值被绑定到单独的对象上,所以它们应该存储在实例数据域中。
面向对象实现
核心特点:将“个人信息(数据)”与“BMI 计算(方法)”封装为 BMI 类,形成独立对象,可直接关联更多属性,代码可重用性强。
BMI 类实现
package com.oop.think;
/**
* @author Jing61
*/
public class BMI {
private String name;
private double height;
private double weight;
private int age;
/**
* 初始化年龄默认为20岁
*/
public BMI(String name, double height, double weight) {
//this在构造方法中可以调用其他构造方法,只能在开始的地方(第一句进行调用)
this(name,height,weight,20);
}
public BMI(String name, double height, double weight, int age) {
this.name = name;
this.height = height;
this.weight = weight;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getBMI() {
return weight / (height * height);
}
public String getState() {
double bmi = getBMI();
if(bmi < 18.5) return "偏瘦";
else if(bmi >= 18.5 && bmi < 25) return "正常";
else if(bmi >= 25 && bmi < 30) return "偏胖";
else return "过胖";
}
}
BMI 类测试
package com.oop.think;
/**
* @author Jing61
*/
public class BMITest {
public static void main(String[] args) {
BMI bmi = new BMI("Tom", 18.5, 80);
System.out.println("BMI: " + bmi.getBMI() + " " + bmi.getState());
}
}
案例总结
这个例子演示了面向对象范式比面向过程有优势的地方。面向过程的范式重点在于设计方法。面向对象的范式将数据和方法耦合在一起构成对象。使用面向对象程序设计的重点在对象和对象的操作。面向对象方法结合了面向过程范式的功能以及将数据和操作集成在对象中的特性。在面向过程程序设计中,数据和数据上的操作是分离的,而且这种做法要求传递数据给方法。面向对象程序设计将数据和对它们的操作都放在一个对象中。这种方法解决了很多面向过程程序设计的固有问题。面向对象程序设计以一种反映真实世界的方式组织程序,在真实世界中,所有的对象和属性及动作都相关联。使用对象提高了软件的可重用性,并且使程序更易于开发和维护。
| 对比维度 | 面向过程编程 | 面向对象编程 |
|---|---|---|
| 核心单元 | 方法(函数) | 对象(数据+方法) |
| 数据与方法关系 | 分离,方法需接收数据作为参数 | 耦合,方法直接操作对象内部数据 |
| 代码复用性 | 差(需重复编写相似逻辑) | 好(通过类实例化对象,或继承复用) |
| 扩展性 | 差(新增数据需修改方法参数和逻辑) | 好(新增属性/方法不影响原有逻辑) |
| 维护成本 | 高(数据与方法分散,修改易引发连锁反应) | 低(封装隔离,修改内部实现不影响外部) |
类的关系:关联、聚集与组合
在面向对象设计中,类之间并非孤立存在,常见关系包括关联(Association)、聚集(Aggregation)、组合(Composition) 和继承(泛化)。本文重点讲解前三种关联关系。
关联(Association)
定义
关联是类之间最常见的关系,描述两个类之间的“互动行为”(如“学生选课”“教师授课”),通常表现为“多对多”“一对多”或“一对一”的依赖。
示例:学员选课系统的关联关系

UML 图解析:
- 关系标签:
Take(学生选课)、Teach(教师授课); - 多重性(对象数量限制):
Student与Course:*(学生可选任意数量课程)、5..60(每门课程有5~60个学生);Faculty与Course:0..3(教师最多授3门课)、1(每门课仅1位教师);
- 角色名:
Teacher是Faculty在“授课”关系中的角色名。
关联关系的代码实现
关联在java代码中如何体现呢?可以通过使用数据域以及方法来实现关联:

实现类之间的关系可以有很多种可能的方法。例如,Course中的学生和教师信息可以省略(单向关联),因为它们已经在Student和Faculty中了。同样的,如果不需要知道一个学生选取的课程或者教师教授的课程,Student或者Faculty类中的数据域courseList和addCourse方法也可以省略。
示例:Student 类
package com.oop.relation;
/**
* @author Jing61
*/
public class Student {
private String ssn;
private String name;
private String major;
private String gender;
/**
* 关联关系(一(多)对多)
* 一个学生可以选取多门课程
*/
private Course[] courses;
// 学生选取的课程数
private int size;
public Student() {
courses = new Course[60];
size = 0;
}
public Student(String ssn, String name, String major, String gender) {
this.ssn = ssn;
this.name = name;
this.major = major;
this.gender = gender;
}
public String getSsn() {
return ssn;
}
public void setSsn(String ssn) {
this.ssn = ssn;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getMajor() {
return major;
}
public void setMajor(String major) {
this.major = major;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public Course[] getCourses() {
return courses;
}
public void setCourses(Course[] courses) {
this.courses = courses;
}
/**
* 关联关系
* 学生选取课程
* @param course
*/
public void selectCourse(Course course) {
if(size < 60) courses[size++] = course;
else System.out.println("该学生选课数已满");
}
}
示例:Course 类
package com.oop.relation;
/**
* @author Jing61
*/
public class Course {
private int id;
private static int nextId = 1;
private String name;
private int credit;
private String intro;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public static int getNextId() {
return nextId;
}
public static void setNextId(int nextId) {
Course.nextId = nextId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getCredit() {
return credit;
}
public void setCredit(int credit) {
this.credit = credit;
}
public String getIntro() {
return intro;
}
public void setIntro(String intro) {
this.intro = intro;
}
}
聚集(Aggregation)与组合(Composition)
聚集和组合是“关联的特殊形式”,均描述整体与部分的关系(has-a 关系),但部分与整体的依赖强度不同。
核心差异
| 关系类型 | 定义 | 部分与整体的依赖 | 示例 | UML 标识 |
|---|---|---|---|---|
| 聚集 | 整体包含部分,但部分可独立于整体存在 | 弱依赖(部分可被多个整体共享) | 学生与地址(一个地址可被多个学生共享) | 空心菱形(整体端) |
| 组合 | 整体包含部分,部分无法独立于整体存在 | 强依赖(部分随整体创建/销毁) | 学生与姓名(一个姓名仅属于一个学生) | 实心菱形(整体端) |
UML 示意图

Student与Name:组合关系(实心菱形),一个姓名仅属于一个学生;Student与Address:聚集关系(空心菱形),一个地址可被多个学生共享。
代码实现
聚集和组合均通过“整体类的属性引用部分类对象”实现,差异体现在“部分对象的生命周期”:

特殊场景:同一类的聚集关系
聚集关系可存在于“同一类的多个对象之间”,例如“员工与管理者”(管理者也是员工):
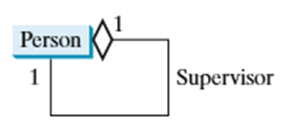
public class Person{
private Person supervisor;
}
泛化(Generalization)
泛化即“继承关系”,描述“父类与子类”的 is-a 关系(如“学生是人类”“教师是人类”),子类继承父类的属性和方法,并可扩展新功能。该部分在“继承与多态”中详细讲解。
示例学习:自定义栈类(MyStack)
栈(Stack)是一种“先进后出”(LIFO,Last-In-First-Out)的数据结构
栈的核心特性
- 数据存储:用数组存储元素;
- 核心操作:
- 压栈(
push):将元素添加到栈顶; - 弹栈(
pop):从栈顶移除并返回元素; - 查看栈顶(
peek):返回栈顶元素,不移除; - 判断空栈(
empty):判断栈是否无元素; - 获取大小(
size):返回栈中元素个数;
- 压栈(
- 扩容机制:当栈满时,自动将数组容量翻倍(或者其他方式,这儿以翻倍做示例),避免溢出。
栈的结构示意图

- 压栈顺序:
Data1 → Data2 → Data3; - 弹栈顺序:
Data3 → Data2 → Data1。
MyStack 类的 UML 设计

MyStack 类的代码实现
package com.oop.stack;
/**
* 自定义存储整型数据的栈
* 栈:先进后出的数据结构,不仅存储数据元素,且提供对数据元素操作的方法
* 1. 使用数据域存储数据元素 ==> 数组
* 2. 提供操作数据元素的行为
* 1. 压栈 push(data:int):void
* 2. 弹栈 pop():int
* 3. 获取栈顶元素 peek():int
* 4. 判断栈是否为空 isEmpty():boolean
* 5. 获取栈中元素个数 size():int
* @author Jing61
*/
public class MyStack {
/**
* 栈的默认容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 栈的元素
*/
private int[] elements;
/**
* 栈中元素个数
*/
private int size;
/**
* 构造方法
* 默认容量为10
*/
public MyStack() {
elements = new int[DEFAULT_CAPACITY];
size = 0;
}
/**
* 构造方法
* @param capacity 栈的容量
*/
public MyStack(int capacity) {
elements = new int[capacity];
size = 0;
}
/**
* 压栈
* @param data 要压栈的数据
*/
public void push(int data) {
if(size == elements.length) { // 栈已满
// 扩容
int[] newElements = new int[elements.length * 2];
// 拷贝
System.arraycopy(elements, 0, newElements, 0, elements.length);
// 将引用赋给elements,原来的会被垃圾回收机制自动回收
elements = newElements;
}
elements[size++] = data;
}
/**
* 弹栈
* @return 栈顶元素
*/
public int pop() {
if(empty()) throw new RuntimeException("栈已空");
else return elements[--size];
}
/**
* 获取栈顶元素,不删除
* @return 栈顶元素
*/
public int peek() {
if(empty()) throw new RuntimeException("栈已空");
else return elements[size - 1];
}
/**
* 获取栈中元素个数
* @return 栈中元素个数
*/
public int size() {
return size;
}
/**
* 判断栈是否为空
* @return true:栈为空,false:栈不为空
*/
public boolean empty() {
return size == 0;
}
}
MyStack 类的测试
package com.oop.stack;
/**
* @author Jing61
*/
public class MyStackTest {
public static void main(String[] args) {
MyStack stack = new MyStack();
System.out.println(stack.empty());
// 入栈
for (int i = 1; i <= 25 ; i++) stack.push(i);
System.out.println("栈中元素个数:" + stack.size());
System.out.println("栈顶元素:" + stack.peek());
// 出栈
while(!stack.empty()) System.out.println(stack.pop());
System.out.println("栈中元素个数:" + stack.size());
}
}
输出结果:

JDK 自带 Stack 类的使用
Java 官方在 java.util 包中提供了 Stack 类(泛型实现,支持任意数据类型),用法与自定义 MyStack 类似:
package com.oop.stack;
/**
* @author Jing61
*/
import java.util.Stack;
public class StackTest {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<Integer>();
System.out.println(stack.empty());
// 入栈
for (int i = 1; i <= 25 ; i++) stack.push(i);
System.out.println("栈中元素个数:" + stack.size());
System.out.println("栈顶元素:" + stack.peek());
// 出栈
while(!stack.empty()) System.out.println(stack.pop());
System.out.println("栈中元素个数:" + stack.size());
}
}
总结
- 面向对象核心:以“对象”为单元,封装数据与方法,实现“使用与实现分离”,提高代码复用性和可维护性。
- 类的设计:通过抽象定义“合约”(公共接口),通过封装隐藏内部细节(
private属性 +public方法)。 - 类间关系:
- 关联:类之间的互动(如学生选课),通过属性引用实现;
- 聚集/组合:整体与部分的关系,差异在于部分是否可独立于整体存在;
- 范化:继承关系;
- 自定义数据结构:如栈的设计,需明确核心操作(压栈、弹栈等),处理边界情况(空栈、扩容),确保逻辑严谨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号