
Redis入门案例
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
单机搭建
linux编译安装redis
wget https://robinliu.3322.org:8888/download/Redis-x64-3.2.100.zip
tar -zxf redis-3.0.0.tar.gz
cd redis-3.0.0
mkdir /usr/local/redis-3.0.0
make PREFIX=/usr/local/redis-3.0.0 install
cp redis.conf /usr/local/redis-3.0.0
vim ~/.bash_profile # .bash_profile是隐藏文件, 在该文件中自定义环境变量
以下两行为.bash_profile最后两行内容:
PATH=$PATH:$HOME/bin:/opt/redis-3.2.9/src # 添加src目录路径到这里
export PATH
:wq
source ~/.bash_profile //使配置的环境立即生效
echo $PATH
which redis-server
redis-server & //后台运行
ps -ef|grep redis //查看启动
kill -9 进程id //关闭服务
单机搭建方式2:
伪分布式搭建
单节点的主从复制创建
首先进入redis安装目录,找到utils,下面会有一个初始化脚本redis_init_script,将其复制为redis+端口号
cp /home/redis-3.2.11/utils/redis_init_script redis-6380 //复制一份新的文件
vim redis-6380 //编辑文件
修改端口
:wq //保存并退出
cp /home/redis-3.2.11/redis.conf /usr/local/redis-3.2.11 //复制文件到指定位置
mv redis.conf redis-6380.conf //给文件重命名
vim redis-6380.conf //编辑文件
i //修改模式
自定义端口
:wq //保存并退回
修改端口为port:6380
redis-server /usr/local/redis-3.2.11/redis-6380.conf //启动测试
ps -ef|grep reids //检查是否启动
kill 进程名称 //自定义是否杀死
redis主从复制测试
以上修改端口重复两次,配置完毕,登录redis-cli -p 6379/redis-cli -p 6380/redis-cli -p 6381,
发现每个服务点都是主机点我们可以使用slaveof 127.0.0.1 6380/slaveof 127.0.0.1 6381,增加多个节点之间的联系,实现了一主二仆实现了数据同步
Redis的五大基本类型
String
5.判断当前key是否存在:exists key
6.移除指定数据库内的key:move key 1
7.设置key的过期时间,单位是秒:expire 查看当前key的剩余时间 :ttl key
8.查看当前key的类型:type key
9.set key 0 incr key #自增1
• decr key # 自减1
• incrby key 10 #加指定数量
• decrby key 10 #减指定数量
10.截取字符串指定地址:getrange key 0 3(-1,全部) 替换指定位置开始的字符串:setrange key 1 xx
11.设置key带有过期时间:setex(set with expire) setex key 30 “HELLO”
12.不存在再设置:setnx(set if not exist) setnx key “redis” —> 1 setnx key “MongoDB” —> 0
13.批量set与get mset k1 v1 k2 v2 k3 v3 mget k1 k2 k3 msetnx k1 v1 k2 v4 #原子性,要么全部成功,不然全部失败
14.存在值则获取原来的值,并设置新的值 getset key “redis”
<img src="C:\Users\liaoy\AppData\Local\Temp\Image.png" alt="Image" style="zoom: 67%;" />
redis数据结构string常用命令
賦值的命令:
set company imooc
获取值
get company
查询所有值
keys *
数值自增/自减
incr company +1
decr compny -1
incrby company 5 +n
decrby company 5 -n
删除
del company
字符串追加
append company xxx
redis数据结构hash常用命令
赋值
hset myhash username jack hset myhash age 18
赋值键值对
hmset myhash2 username rose age 21
获取单个属性/多个属性/所有属性
/单个属性 hget myhash username /多个属性 hmget myhash2 username age /所有属性 hgetall myhash/myhash2
删除某个key/values
hdel myhash2 username age
增加数字
hincrby myhash age 5
判断某个key属性是否存在
hexists myhash username/password
获取所有的key/vlues,以及长度
hkeys myhash hvals myhash hlen myhash
redis数据结构list常用命令
向头部添加元素/尾部添加元素
lpush mylist a b c d rpush mylist 1 2 3
查询列表
lrange key start end:获取链表中从start到end的元素的值,start、end从0开始计数;也可以为负数,若为-1则表示链表尾部的元素,-2表示倒数第二个,依次类推....
lrange mylist 0 -1
两端弹出,类似于出栈
头部弹出,默认第一个元素 lpop mylist 尾部弹出,默认第一个元素 rpop mylsit
获取长度
llen mylist
lrem key count value:删除count个值为value的元素,如果count大于0,从头到尾遍历并删除count个值为value的元素,如果count小于0,则从尾到头遍历并删除,如果count等于0,则删除链表中所有等于value的元素。
从头删除两个b lrem mylist 2 b 从尾部删除两个b lrem mylist -2 a 删除所有a lrem mylist 0 a
lset key index value:设置链表中的index的脚标的元素值,0代表的头元素,-1代表链表的微元素,操作链表的脚标不存在则抛异常。
lset mylist 0 ee
指定位置插入元素
linsert mylist after b a
redis数据结构set常用命令
set不允许出现重复元素
sadd:往set中添加值,无序,不可重复(只存储数字时,数字会升序存储)
sadd set01 2 2 3 3 4 4 1 1 5 5
查询结果/查询总数量
smembers set01 smembers set01 1 ..'1' 查询数量 scard set01 ..'5'
srem key value:删除集合中的元素
srem set01 5
srandmember key n:随机从key中查询n个数
srabdmember set01 2
spop key:随机出栈
spop set01 ..3 spop set01 ..1
smove source_set objective_set value:将源集合中的value存入目标集合中:
smove set01 ste02 1
数学集合类: sdiff / sinter / sunion: sdiff:取差集,存在第一个set而不存在于后面的任何 一个set sinter:取交集 sunion:取并集
sadd set01 1 2 3 4 5 sadd set02 1 2 3 x y sdiff set01 set02 '4','5' sinter set01 set02 '1,','2','3' sunion set01 set02 'x','2','y','1','3','5','4'
redis数据结构sorted-set常用命令
如果key已经存在,再次添加一个key相同的,但是分部不同,会将分数改成最新的分数,然后返回的数字是0;如果是添加一个新的key值,就是返回添加进去的个数。
zadd mysort 60 zs 70 ls 80 ww
查看filed个数/倒序
zcard mysort 个数 zrange mysort 0 -1 结果
删除
zrem mysort ww
根据分数排序
一直是从小到大,一种是从大到小
zrange mysort 0 -1 withscores 结果+分数 zrevrange mysort 0 -1 withscores
范围删除
zremrangebyrank mysort 0 1 全部删除 zremrnagebyrankscore mysort 50 60 条件删除
分数排序后查看
zrangebyscore mysort 100 withscores limit 0 3
常用命令
连续删除
del a1 a2 a3
查询是否存在
exists a1
修改名字
rename a1 newa1
设
Spring整合Redis
-
maven依赖配置项
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>
-
properties配置项
spring: redis: host: 127.0.0.1 port: 6379 password: jedis: pool: max-active: 8 max-wait: -1 max-idle: 500 min-idle: 0 lettuce: shutdown-timeout: 0 -
Spring配置项
@Configuration public class RedisConfig { @Bean public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); // 设置key的序列化方式 template.setKeySerializer(RedisSerializer.string()); // 设置value的序列化方式 template.setValueSerializer(RedisSerializer.json()); // 设置hash的key的序列化方式 template.setHashKeySerializer(RedisSerializer.string()); // 设置hash的value的序列化方式 template.setHashValueSerializer(RedisSerializer.json()); template.afterPropertiesSet(); return template; } } -
测试单元
@RunWith(SpringRunner.class) @SpringBootTest @ContextConfiguration(classes = CommunityApplication.class) public class RedisTest { @Autowired private RedisTemplate redisTemplate; @Autowired private LikeService likeService; @Test public void redisTest(){ String key = "age"; redisTemplate.opsForValue().set(key,20); redisTemplate.opsForValue().get(key); System.out.println(redisTemplate.opsForValue().get(key)); } }
RedisAPI使用
Jedis
导入依赖
<!--redis的客户端依赖jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
代码测试
package cn.tedu.redis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
/**
* 1 单个对象连接redis
* 2 数据分片计算逻辑
* hash取余算法
* 数据分片对象ShardedJedis--一致性hash
* 3 jedis的连接池pool的使用
*/
public class JedisTest {
//创建jedis对象,提供参数ip port 连接到10.9.160.137:9000的redis服务端
@Test
public void test01(){
Jedis jedis=new Jedis("10.9.160.137",9000);
jedis.set("name","王老师");//name=wanglaoshi 写入到redis
System.out.println(jedis.get("name"));//读取redis 的key为name的数据
//hash类型
jedis.hset("user","name","王翠花");
jedis.hset("user","age","18");
jedis.hget("user","nage");
//list类型
jedis.lpush("students","张三","李四","张三","王五");
jedis.rpop("students");
//set类型
jedis.sadd("favor","math","english");
jedis.sismember("favor","math");
//zset类型
jedis.zadd("results",100,"朴乾");
jedis.zadd("results",99,"陈哲");
}
}
package cn.tedu.redis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
/**
* 1 单个对象连接redis
* 2 数据分片计算逻辑
* hash取余算法
* 数据分片对象ShardedJedis--一致性hash
* 3 jedis的连接池pool的使用
*/
public class JedisTest {
//创建jedis对象,提供参数ip port 连接到10.9.160.137:9000的redis服务端
@Test
public void test01(){
Jedis jedis=new Jedis("10.9.160.137",9000);
jedis.set("name","王老师");//name=wanglaoshi 写入到redis
System.out.println(jedis.get("name"));//读取redis 的key为name的数据
//hash类型
jedis.hset("user","name","王翠花");
jedis.hset("user","age","18");
jedis.hget("user","nage");
//list类型
jedis.lpush("students","张三","李四","张三","王五");
jedis.rpop("students");
//set类型
jedis.sadd("favor","math","english");
jedis.sismember("favor","math");
//zset类型
jedis.zadd("results",100,"朴乾");
jedis.zadd("results",99,"陈哲");
}
}
JedisPool连接池
代码实现
/*
JedisPool
*/
@Test
public void test05(){
JedisPool pool=new JedisPool("10.9.118.11",6380);
//获取连接资源
Jedis jedis1 = pool.getResource();
jedis1.set("name","王翠花");
pool.returnResource(jedis1);
Jedis jedis2 = pool.getResource();
System.out.println(jedis2.get("name"));
pool.returnResource(jedis2);
}
Redis分布式
分布式概念
单机节点存在意外故障导致宕机现象,在redis中我们可以引用redis分布式来保证可用性,分布式通俗的讲就是将一个人干的活交给多个人做
分布式需要考虑的问题
-
-
数据的分配--数据分片计算
-
-
单节点时,无需考虑数据的分配问题,因为所有数据都必须在这个节点实现读写,但是一旦引入分布式的集群,必须考虑数据整体怎么样分配给不同的节点,而且保证---单调性.整体一批数据被切分成了若干分,称之为数据分片
-
单调性:哪存的,在哪取.
hash取余
-
一旦涉及到单调性,最先考虑到的计算逻辑就是hash散列.hash取余是一种分布式结构中非常经典的计算方法.
-
hash取余对数据key-value的key值做hash取余计算,得到结果只要key值不变(字符串相等) 取余结果在[0,1,2,3,…,n-1] n=分片个数(节点个数),计算公式
-
(key.hashCode()&Integer.MAX_VALUE)%N 其中**N为分片(节点)个数**
-
key.hashCode(): 对key做hash散列计算,只要key值不变,得到一个不变可正可负的整数.只要散列计算,能够做到key不变,整数结果不变,不一定非得使用hashCode 最终任意一个key值都会对应[-21亿,21亿]区间的一个整数
-
key.hashCode()&Integer.MAX_VALUE: 31**位二进制保真运算**,目的是将前面的整数保真后31位二进制,保证他是一个正整数.& 位的与运算.目的是取得一个正整数
-
-
结论**1**:当key值不变时,可以得到一个不变的正整数
-
(key.hashCode()&Integer.MAX_VALUE)%N
-
N=5,取余结果 [0,1,2,3,4]
-
N=4,取余结果 [0,1,2,3]
-
N=3,取余结果 [0,1,2]
-
对N取余 结果[0,1,2,3,4,5…,N-1]
-
-
结论**2**:当key值不变时,可以通过hash取余得到 [0,1,2,..,N-1] 一个不变的取余结果
-
hash取余就可以应用在redis分布式数据分片计算逻辑中
-
当有key-value出现时,先对key做hash取余 n是节点个数(现在是3)
-
所有节点jedis排序(list) 0 1 2 … n-1 使用到取余结果对应到一个固定的jedis对象,最终连接固定的redis节点
-
代码实现
-
//hash取余数据分片计算 @Test public void test02(){ //先来封装3个redis的节点jedis对象的list List<Jedis> jedisList=new ArrayList<>(); jedisList.add(new Jedis("10.9.160.137",6379)); jedisList.add(new Jedis("10.9.160.137",6380)); jedisList.add(new Jedis("10.9.160.137",6381)); //系统生成了海量数据 int rand=55; String keyS=""; for(int i=0;i<100;i++){ String key= UUID.randomUUID().toString(); String value="value_"+i; //写入redis的节点 6379 6380 6381--hash取余计算方法 //得到取余结果 int index = (key.hashCode() & Integer.MAX_VALUE) % jedisList.size(); //根据取余结果 从jedisList获取对应节点 Jedis jedis = jedisList.get(index); jedis.set(key,value); if(i==rand){ keyS=key; } } //hash取余,获取keyS的对应节点,读数据如果读到了,说hash散列取余计算能保证单调性的 int index = (keyS.hashCode() & Integer.MAX_VALUE) % jedisList.size(); //根据取余结果 从jedisList获取对应节点 Jedis jedis = jedisList.get(index); System.out.println(jedis.get(keyS)); } -
-
hash取余不适用于redis的分布式集群
-
-
只要是hash必定数据倾斜; 可以通过key值的设计解决数据倾斜,key越规律(hashCode),数据倾斜越小.
-
-
-
由于redis集群有动态线性扩展的特点.3个变5个,5个变12个,很频繁发生.hash取余无法保证扩容,缩容时的单调性.(单调性造成严重破坏)
-
-
一致性hash
原理
-
-
基础:麻省理工大学97年创建的一个数学模型,后被应用到分布式领域.实现了一个hash映射计算,可以将任意的内存数据对象,通过hash散列映射到[0,2^32-1]
由于结果是32位二进制,0减一变成2^32-1 最大数加一变成0,这个取值区间称谓hash环
-
redis如何被使用(redis结构变化)
不是增加服务器个数就一定能解决问题的。需要根据结构的变化处理新的问题
一旦引入分布式集群,需要解决 数据分片计算逻辑:数据切分,保证key-value单调性
两个计算方法目的:key-value找到对应节点写,并且key不变找到同一个节点读
hash取余:hash保证单调性,取余获取key与节点对应关系
hash取余算法,适用于n不变的环境,否则n经常变化,会破坏数据单调性
一致性hash:什么是一致性hash 描述一下。
基础:hash环,0-43亿整数区间做映射
数据映射:redis数据 节点数据,key值
对应关系: key整数顺时针寻找最近节点整数
平衡性:引入了计算的中间结果,虚拟节点,可以将数据映射关系做的更平均,160*weight,可以根据比例分配权重值。实现权重逻辑。
数据倾斜问题,靠调整key的取值结构,缓解 倾斜。key和节点是强耦合
Redis哨兵
介绍
1.redis中存在一个高可用结构的重要进程,sentinel哨兵,可以实现监听主从控制主从,完成主从复制基础之上的故障替换转移,主节点宕机,从节点顶替.哨兵也是redis-server进程,比较特殊,不处理数据增删查改,只负责监听主从
2.主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。

哨兵执行逻辑
-
哨兵启动会连接主节点
-
调用info replication 获取到主从集群的所有节点信息
-
开启每秒钟的心跳检测(rpc远程通信协议),判断节点是否存活
-
从节点宕机,哨兵进程只会做记录 down
-
主节点宕机,哨兵开始发起投票选举,在多个从节点中选择其中一个顶替成为新的主节点,其他从节点哨兵重新挂接到新的主节点,宕机的主节点,哨兵会记录他为从节点(暂时无法到这个宕机执行命令) .当主节点恢复之后,哨兵到这个主节点执行挂接命令,挂接到新的主节点
-
-
投票需要过半机制
-
如果3个哨兵进程,2个以上选择同一个从节点,这个从节点才能顶替原有主节点提供功能
-
不过半的投票结果是作废的,将会隔一段时间重新投票
-
搭建测试环境
redis哨兵创建 cd /home/redis-3.2.11 //操作文件位置地址 cp sentinel.conf sentinel-6380.conf //复制 vim sentinel-6380.conf //编辑 i 修改端口 :wq /home/redis-3.2.11/src/redis-sentinel /home/redis-3.2.11/sentinel-6380.conf //启动哨兵 ps -ef|grep redis //查看是否启动 redis哨兵测试 以下代码为添加三个哨兵 修改redis根路径中的sentinel.conf为多个sentinel-6380.conf/sentinel-6381.conf,并修改里面的配置文件修改, sentinel monitor mymaster 127.0.0.1 6379 2 sentinel monitor mymaster 127.0.0.1 6380 2 sentinel monitor mymaster 127.0.0.1 6381 2 ,修改配置文件中的端口 port 26379 port 26380 port 26381 可以宕机主节点,查看哨兵配置日志文件发现执行流程
Redis持久化策略
持久化的目的
redis是一个内存数据库(非关系型数据库),当redis服务器重启,或电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
持久化思想
redis操作时,首先操作的都是内存中的数据。redis根据自身的配置选择不同的持久化方式,定期将内存中的数据保存到本地磁盘中,当redis重启服务时,首先会根据配置文件中指定的持久化文件恢复内存数据。
RDB

工作方式
当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
1.Redis 调用forks。同时拥有父进程和子进程。
2.子进程将数据集写入到一个临时 RDB 文件中。
3.子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文 件。这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
触发方式
自动触发:
触发条件可以通过redis.conf 配置文件中的 SNAPSHOTTING 下配置
手动触发:
save:阻塞命令,客户端无法进行命令操作 。bgsave:(非阻塞,子进程执行保存操作)
优势
1). 一旦采用该方式,那么你的整个Redis数据库将只包含一个文件,这对于文件备份而言是非常完美的。比 如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的 备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 对于灾难恢复而言,RDB是非常不错的选择。因为我们可以非常轻松的将一个单独的文件压缩后再转移到 其它存储介质上。
3). 性能最大化。对于Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork出子进程,之后再由 子进程完成这些持久化的工作,这样就可以极大的避免服务进程执行IO操作了。
4). 相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
劣势
1). 如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统 一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
2). 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时,可能会导致整 个服务器停止服务几百毫秒,甚至是1秒钟
AOF
概念
快照功能(RDB)并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将 丢失最近写入、且仍未保存到快照中的那些数据。 从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方 式: AOF 持久化。
触发方式:
将 redis.conf 的 appendonly 配置改为 yes 即可。
AOF 保存文件的位置和 RDB 保存文件的位置一样,都是通过 redis.conf 配置文件的 dir 配置
创建原理
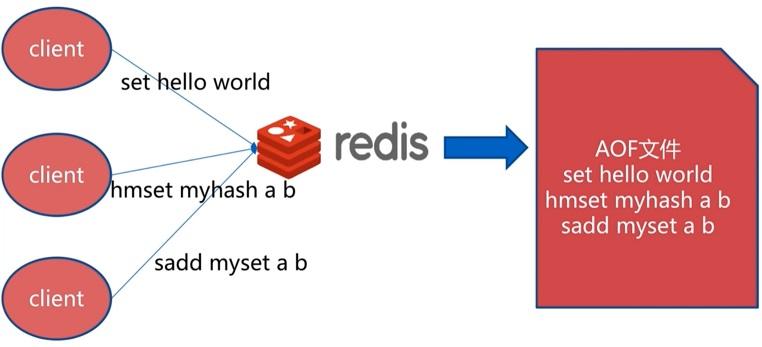
恢复原理
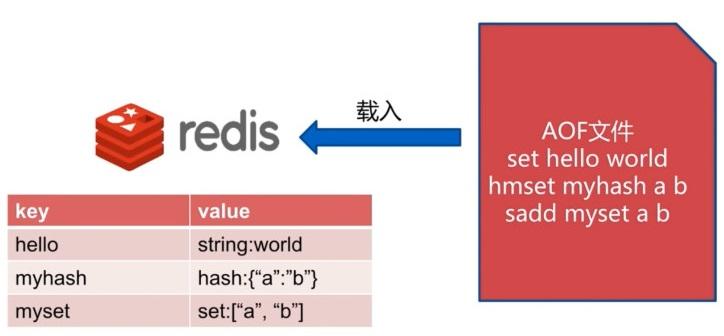
重启 Redis 之后就会进行 AOF 文件的载入。
异常修复命令:redis-check-aof --fix 进行修复
AOF三种持久化策略:
在配置文件中,aof提供了三种持久化策略。可以通过对appendfsync字段配置:aof持久化策略的配置
1.Always
服务器每次写入一个命令,就调用一次fdatasync,将缓冲区命令写入到磁盘中,这种模式下,服务器即使 遭遇危机意外停机,也不会丢失任何成功执行的命令数据
2.Everrysec
每秒调用用一次fdatasync,将缓冲区命令写入磁盘,在这种模式写,服务器即使遭遇意外停机时,最多只丢失 一秒钟内执行的命令数据
3.No
服务器不主动调用fdatasync,由操作系统决定任何将缓冲区里面的命令写入磁盘里面,在这种模式写,服务器 遭遇意外停机时,丢失命令的数据是不确定的
4.always的速度慢,everysec和no都很快,默认值:everysec
AOF重写
因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积 也会变得越来越大。举个例子, 如果你对一个计数器调用了 100 次 INCR , 那么仅仅是为了保存这个计数器 的当前值, AOF 文件就需要使用 100 条记录(entry)。然而在实际上, 只使用一条 SET 命令已经足以保存 计数器的当前值了, 其余 99 条记录实际上都是多余的。为了处理这种情况, Redis 支持一种有趣的特性: 可以在不打断服务客户端的情况下, 对 AOF 文件进行重建(rebuild)。执行 bgrewriteaof 命令, Redis 将 生成一个新的 AOF 文件, 这个文件包含重建当前数据集所需的最少命令。Redis 2.2 需要自己手动执行 grewriteaof 命令; Redis 2.4 则可以通过配置自动触发 AOF 重写。
二者的区别
1.RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
2.AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
Redis事务
Redis事务的概念:
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
Redis事务没有隔离级别的概念:
批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行,也就不存在事务内的查询要看到事务里的更新,事务外查询不能看到。
Redis不保证原子性:
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
Redis事务的三个阶段:
-
开始事务
-
命令入队
-
执行事务
Redis事务相关命令:
watch key1 key2 ... : 监视一或多个key,如果在事务执行之前,被监视的key被其他命令改动,则事务被打断 ( 类似乐观锁 )
multi : 标记一个事务块的开始( queued )
exec : 执行所有事务块的命令 ( 一旦执行exec后,之前加的监控锁都会被取消掉 )
discard : 取消事务,放弃事务块中的所有命令
unwatch : 取消watch对所有key的监控
Redis-Cluster集群
槽道原理
Redis穿透、击穿、雪崩
缓存穿透
现象:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的, 并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存 储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过 大。
解决方案:
1.从DB中查询出来数据为空,也进行空数据的缓存,避免DB数据为空也每次都进行数据库查询; 2.使用布隆过滤器,但是会增加一定的复杂度及存在一定的误判率;
缓存雪崩
现象:大量key同一时间点失效,同时又有大量请求打进来,导致流量直接打在DB上,造成DB不可用。
解决方案:
1.设置key永不失效(热点数据); 2.设置key缓存失效时候尽可能错开; 3.使用多级缓存机制,比如同时使用redsi和memcache缓存,请求->redis->memcache->db; 4.购买第三方可靠性高的Redis云服务器;
缓存击穿
现象: 缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
1.设置热点数据永远不过期。
2.接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接 口中的某些 服务 不可用时候,进行熔断,失败快速返回机制。
3.布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应 用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算 法和容器大小,
4.加互斥锁
Redis-session共享实战
概念
Redis最常见的用途是会话存储。与其他会话存储(如Memcache)不同,Redis可以保留数据,以便在缓存停止的情况下,在重新启动时,所有数据仍然存在。即便不是需要严格持续的任务,此功能仍可以为你的用户省去大量的麻烦。没有人会乐于见到他们的会话被无缘无故随机删掉。
代码测试
package cn.tedu.user.controller;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.jt.common.pojo.User;
import org.junit.jupiter.api.DynamicTest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.ListOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Date;
import java.util.concurrent.TimeUnit;
@RestController
public class RedisController {
@Autowired
private StringRedisTemplate redisTemplate;
//请求到该节点 /cluster 传递参数 key value
//方法中将key写入到redis集群中
@RequestMapping("/cluster")
public String setAndGet(String key, String value, HttpServletRequest request, HttpServletResponse response){
/* Cookie cookie=new Cookie("name","王翠花");
response.addCookie
response.setPath
response.setMaxAge
*/ //redisTemplate封装底层client jedis lettuce
//redisTemplate直接操作基础方法命令expire pexpire ttl pttl
redisTemplate.expire(key,2, TimeUnit.HOURS);//设置超时时长
Long ttl = redisTemplate.getExpire(key, TimeUnit.MINUTES);
System.out.println("超时时间,还剩"+ttl+"分钟");
Boolean exist= redisTemplate.hasKey(key);//exists
System.out.println(key+(exist?"存在":"不存在"));
redisTemplate.delete(key);
//redisTemplate.expireAt("name",new Date("时间"));设置超时时间点
//五种数据类型 封装了对应的操作对象
//String 从template获取 opsForValue的对象
ValueOperations<String, String> opsForString
= redisTemplate.opsForValue();
opsForString.increment("num",100);//incr incrby
opsForString.set(key,value);
//Hash 从template获取opsForHash
HashOperations<String, Object, Object> opsForHash
= redisTemplate.opsForHash();
opsForHash.put("user","age","18");
opsForHash.get("user","age");
//List 从template获取opsForList
ListOperations<String, String> opsForList
= redisTemplate.opsForList();
opsForList.leftPush("list01","100");
opsForList.rightPop("list01");
opsForList.size("list01");//llen
opsForList.set("list01",0,"200");
//SET opsForSet
//ZSET opsForZSet
return opsForString.get(key);
}
//执行续约逻辑
/*
判断 集群中,一个叫做"user" 的key值,剩余超时时间
是否超过1小时,超过一小返回"剩余时间充足"
如果不超过一小时,将其设置超时时间为2小时;返回"重置超时时间"
getExpire TimeUnit
expire
*/
@RequestMapping("/lease")
public String lease(){
Long leftTime =
redisTemplate.getExpire("user", TimeUnit.SECONDS);
if(leftTime<60*60){
//重置2小时超时
redisTemplate.expire("user",2,TimeUnit.HOURS);
return "当前user的数据重置2小时超时";
}
return "当前user数据剩余时间充足";
}
/* public static void main(String[] args) throws JsonProcessingException {
User user=new User();
user.setUserName("wangcuihua");
user.setUserPassword("123456");
//{"userName":"wangcuihua","passowrd":"123456",null,null}
ObjectMapper objectMapper=new ObjectMapper();
String userJson=objectMapper.writeValueAsString(user);
System.out.println(userJson);
}*/
}
Redis分布式锁与JDK锁实战
Rdis高级数据类型
HyperLogLog
-
采用一种基数算法,用于完成独立总数的统计。
-
占据空间小,无论统计多少个数据,只占12K的内存空间。-不精确的统计算法,标准误差为081%。
Bitmap
-
不是一种独立的数据结构,实际上就是字符串。-支持按位存取数据,可以将其看成是byte数组。-适合存储索大量的连续的数据的布尔值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号