Python-正则表达式
1、正则表达式:
概述:
正则表达式:RegularExpression,缩写regex,regexp,RE等。是处理文本极为重要的技术,用它可以对字符串按照某种规则进行检索,替换。
分类:
1、BRE
基本正则表达式,grep, sed,vi,等软件支持,vim有扩展
2、ERE
扩展正则比倒是是,ergep(grep -E),sed -r等
3、PCRE
几乎所有高级语言都是PCRE的方言Python从1.6开始使用正则表达式引擎。
2、基本语法:
元字符:(匹配一位)
. 匹配除换行符外的任意一个字符
[abc]:字符集合,只能表示一个字符位置
[^abc]
[a-z]
[^a-z]
\b:匹配单词的边间, \bb 找b开头, \b[abc] :a或b或c开头,适合英文
\B:不匹配单词的边界 t\B 含t,但不以t结尾, \Bb 不以b开头,但含有b
\d:[0-9]匹配一位数字
\D:[^0-9]一位非数字
\s:[ \f\r\n\t\v]匹配1位空白字符---空格,分页,回车,换行,制表,在win中注意\r\n
\S:一位非空白字符
\w:匹配[a-zA-Z0-9_],包括中文,,注意还有个下划线
\W:之外的字符,win中可能是\r会被匹配(查一下)
转义:
凡是在正则表达式中有特殊意义的符号,如果想使用它本意,请使用 \ 转 义.
反斜杆自身,得使用 \\
\r , \n 还是转义后代表回车,换行
重复:(贪婪模式)
*:任意次
+:至少一次
?:0,1次
{n}:n次
{n,}
{n,m}
x | y: 匹配x 或者y
捕获:
(pattern):使用小括号指定一个子表达式,也叫分组捕获后会自动分配组号,从1 开始,可以改变优先级
\数字:匹配对应的分组 如:(very)\1 ----> veryvery
(?:pattern):仅仅改变优先级,并不分组(或者取消分组)
(?P<name>exp) (?P'name'exp) 分组捕获,但是可以通过name访问分组
零宽断言:
(?=exp):如:f(?=oo) f后面一定有oo出现,但是不显示oo,只显示f
(?<=exp):如:(?<=f)ood ood之前一定有f,但是不显示f,只显示ood
负向零宽断言:
(?!exp):如:\d{3}(?!\d)匹配三位数字,断言3位数字后一定不能是数字
(?<!exp):如: (?<!f)ood ood的左边一定不是f
注释:
(?#comment) : f(?=oo)(?#.....)
注:
断言不会被捕获,不会占用分组,因为本身并不是分组,不会match,所以更不会分组
分组和捕获是同一个意思!
贪婪与非贪婪:
默认是贪婪模式,也就是说尽量匹配更长的字符串
非贪婪模式很简单,尽量少的匹配
*?: 匹配任意次,但是尽可能少重复
+?:匹配至少一次,但是尽可能少重复
??:匹配0次,或1次,但是尽可能少重复
{n,}?:至少匹配n次,但是尽可能少重复
{n,m}:至少匹配n次,之多m次,但是尽可能少重复
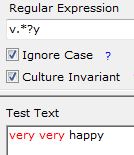
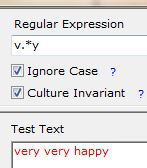
可以看出左图:使用了非贪婪模式,也就是第二个verry 匹配到y就不往后走了,否则还会往后走,如右图
引擎:
IgnoreCase:忽略大小写 re.I
Singleline:单行模式,可以匹配所有的字符,包括\n re.S
Multiline:多行模式,^ 行首,$行尾 re.M
IgonrePatternWhitespace:忽略表达式中的空白字符,否则需要转义 re.X
单行模式:
. 可以匹配所有的字符,包括换行符
^ 表示整个字符串的开头,$整个字符串的结尾
多行模式:
. 可以匹配除换行符外所有的字符,包括换行符
^ 表示行的开头,$整个行的结尾
开头:\n后紧接着下一个字符,
结尾:\n前的一个字符
注:注意字符串中看不见的换行符,\r\n 会影响 $测试,appe$ 只能匹配 appe\n
单行、多行一起用:
如果是 点 看单行模式
如果是 ^ 看多行模式
如果都不选 , 点是冲不破 换行符的,$就是文件末尾
默认模式:可以看做待匹配的文本是一行,不能看做多行,点号不能匹配换行符, ^ 和 $ 表示行首和行尾,而行行首行尾就是整个字符串的开头和结尾。
单行模式:基本和默认模式一样,只是 点号终于可以匹配任意一个字符,包括换换行符,这时所有文本就是一个长长的只有一行的字符串,^就是这一行字符串的行首,$ 就是这一行的行尾
多行模式:重新定义了行的概念,但不影响点号的行为, ^ 和 $ 还是行首行尾的意思,只不过因为多行模式可以识别换行符了,‘开始’指的是\n 后紧接着的下一个字符,,‘结束’指的是\n前的字符,注意最后一行结尾可以没有\n
简单讲:单行模式只影响点 号行为,多行模式重新定义行
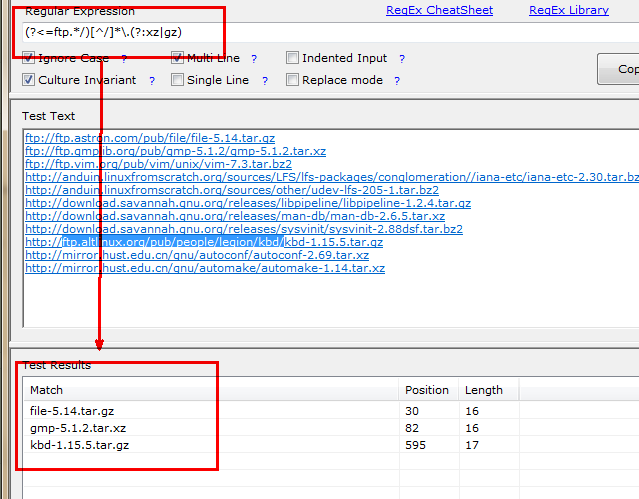
举例:选出含有ftp的链接,且文件类型是gz或者xz的文件,要求打印其文件名,文件名升序排列
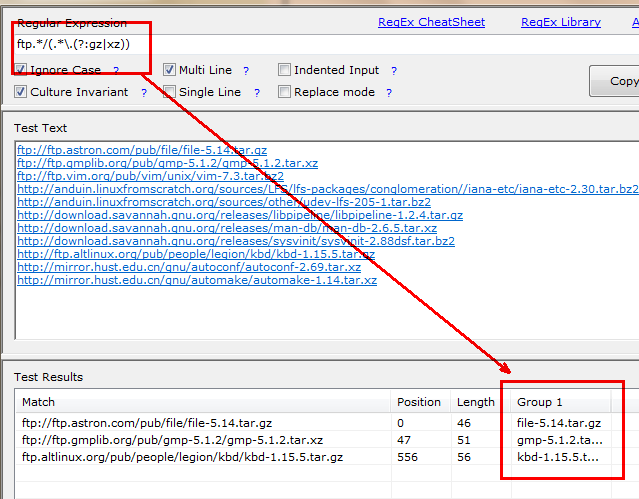
或者利用断言,直接取出来;
3、python的正则表达式:
python使用re模块提供正则表达式处理的能力
常量:
| 常量 | 说明 |
| re.M re.MULTILINE | 多行模式 |
| re.S re.DOTALL | 单行模式 |
| re.I re.IGNORECASE | 忽略大小写 |
| re.X re.VERBOSE | 忽略表达式中空白字符 |
使用 | 位或,开启多中模式
编译:
re.complie( pattern, flags = 0)
设定flags,编译模式,返回正则表达式对象regex
pattern就是正则表达式字符创,flags是选项,正则表达式需要被编译,为了提高效率,这些编译后的结果被保存,下次使同样的pattern的时候,就不需要再次编译。
re的其他方法为了提高效率都调用了编译方法,为了提高效率。
测试:


1 import re 2 3 s = '''bottle\nbag\nbig\napple''' 4 5 ''' 6 match 使用 7 match 不管多行还是单行,只从开头查找, 8 或,先编译,再指定的位置索引开始找,第一个字符匹配不上,就None,且只匹配一个''' 9 print('{:*^{}}'.format('macth', 30)) 10 ''' 编译的match 和 非编译的match不是同一个match''' 11 result = re.match('b', s) 12 print(result) # <re.Match object; span=(0, 1), match='b'> 返回一个match对象 13 result = re.match('a', s) 14 print(result) # None 15 result = re.match('^a', s, re.M) 16 print(result) # None 17 result = re.match('^a', s, re.S,) 18 print(result) # None 19 20 print('{:*^{}}'.format('macth-compile', 30)) 21 # 现编译,然后使用正则表达式对象 22 regex = re.compile('a') 23 # print(regex) # re.compile('a') 24 result = regex.match(s) 25 print(result) # None 26 result = regex.match(s, 15) # 把索引15 作为开始找 27 print(result) # <re.Match object; span=(15, 16), match='a'> 28 29 ''' 30 search 使用 31 search(),从当前位置往后找,匹配第一个,之后不匹配了 32 ''' 33 ''' 编译的serach和 非编译的search不是同一个search''' 34 35 print('{:*^{}}'.format('search', 30)) 36 37 result = re.search('a', s) 38 print(result) # <re.Match object; span=(8, 9), match='a'> 返回一个match 对象 39 40 regex = re.compile('b') 41 result = regex.search(s, 2) 42 print(result) # <re.Match object; span=(7, 8), match='b'> 43 44 regex = re.compile('^b', re.M) 45 result = regex.search(s) 46 print(1,result) # <re.Match object; span=(0, 1), match='b'>, 不管多少行,找到就返回 47 48 result = regex.search(s, 5) 49 print(2, result) # 2 <re.Match object; span=(7, 8), match='b'> 50 51 ''' 52 fullmatch 的使用 53 要完全匹配不能多, 不能少 54 # fullmatch 把整个字符串包括在内,多行模式,换行符也算 55 56 ''' 57 print('{:*^{}}'.format('fullmatch', 30)) 58 59 result = re.fullmatch('bag', s) 60 print(result) # None 61 62 regex = re.compile('bag') 63 result = regex.fullmatch(s) 64 print(result) # none 65 66 regex = re.compile('bag') 67 result = regex.fullmatch(s, 7) 68 print(result) # none 69 70 regex = re.compile('bag') 71 result = regex.fullmatch(s, 7, 10) 72 print(result) # <re.Match object; span=(7, 10), match='bag'> 73 74 75 76 ''' 全文搜索 ''' 77 78 79 s = '''bottle\nbag\nbig\nable''' 80 81 ''' 82 findall 的使用,立即返回,全是元素字符串 83 84 ''' 85 print('{:*^{}}'.format('findall', 30)) 86 87 result = re.findall('b', s) 88 print(result) # ['b', 'b', 'b', 'b'],所用的都找到,返回列表 89 90 regex = re.compile('^b') 91 print(regex) # re.compile('^b') 92 result = regex.findall(s) 93 print(result) # ['b'] 94 95 regex = re.compile('^b', re.M) 96 result = regex.findall(s, 7) 97 print(result) # ['b', 'b'] 98 99 regex = re.compile('b', re.S) 100 result = regex.findall(s) 101 print(result) # ['b', 'b', 'b', 'b'] 102 103 regex = re.compile('^b', re.S) 104 result = regex.findall(s) 105 print(result) # ['b'] 106 107 regex = re.compile('^b', re.M) 108 result = regex.findall(s, 7, 10) 109 print(result) # ['b'] 110 111 112 ''' 113 finditer 方法 114 115 ''' 116 print('{:*^{}}'.format('finditer', 30)) 117 118 regex = re.compile('^b', re.M) 119 result = regex.finditer(s) 120 for i in result: 121 print(1, i) # match 对象 122 # 1 <re.Match object; span=(0, 1), match='b'> 123 # 1 <re.Match object; span=(7, 8), match='b'> 124 # 1 <re.Match object; span=(11, 12), match='b'> 125 print(result) # <callable_iterator object at 0x00000000021CFCC0> 返回一个可迭代对象 126 print(type(result)) # <class 'callable_iterator'> 127 128 129 ''' 匹配替换 ''' 130 131 s = '''bottle\nbag\nbig\napple''' 132 133 print('------------------匹配替换------------------') 134 # 替换方法: 135 regex = re.compile('b\wg') 136 result = regex.sub('magedu', s) 137 print(result)# 打印如下 138 ''' 139 bottle 140 magedu 141 magedu 142 apple 143 ''' 144 result = regex.sub('magedu', s, 1) # 指定替换次数 145 print(result) 146 147 '''subn''' 148 regex = re.compile('\s+') 149 result = regex.subn('\t', s) 150 print(result) # ('bottle\tbag\tbig\tapple', 3) 替换了的次数,替换后的序列 151 152 153 154 ''' 分割方法 ''' 155 ''' 156 字符串 的 分割split,太难用,不能给指定多个字符进行分割 157 ''' 158 print('------re.spilt------------') 159 160 s = '''01 bottle 161 02 bag 162 03 big1 163 100 able''' 164 165 ''' 每行单词提取出来 ''' 166 # 是否需要保留 big1 后面的1 167 regex = re.compile('\s+\d+\s+') 168 result = regex.split(s) 169 print(type(result)) 170 print(result) 171 172 regex = re.compile('[\s\d]+') 173 result = regex.split(' ' + s) 174 print(result) 175 176 177 ''' 分组 ''' 178 ''' 179 使用小括号的pattern 捕获的数据被放到了组group中 180 match,search函数可以返回match对象,findall返回字符串,finditer返回一个个match对象 181 如果pattern中使用了分组,如果有匹配的结果,会在match对象中 182 1、使用group(n)方式返回对应分组,1到N 是对应的分组,0 返回 整个匹配的字符串 183 2、如果使用了命名分组,可以使用group('name')的方式取分组 184 4、使用groupdict()返回所有命名的分组 185 ''' 186 187 s = '''bottle\nbag\nbig\napple''' 188 print('------- 分组 -----------') 189 # 分组 190 regex = re.compile('(b\w+)') 191 result = regex.match(s) 192 print(type(result)) # <class 're.Match'> 193 print(1, 'match', result.groups()) # 1 match ('bottle',) 194 195 196 regex = re.compile('(b)(\w+)') 197 result = regex.match(s) 198 print(result) # <re.Match object; span=(0, 6), match='bottle'> 199 print(type(result)) # <class 're.Match'> 200 print(1, 'match', result.groups()) # 1 match ('b', 'ottle') 两个分组 201 202 203 result = regex.search(s, 1) 204 print(result,result.group()) 205 # <re.Match object; span=(7, 10), match='bag'> bag 206 207 s = '''bottle\nbag\nbig\napple''' 208 209 # 命名分组 210 print('----- 命名分组-------- ------------') 211 regex = re.compile('(b\w+)\n(?P<name2>b\w+)\n(?P<name3>b\w+)' ) 212 result = regex.match(s) 213 print(result,'+++++') 214 print(result.groups()) # ('bottle', 'bag', 'big')---- 215 print(result.group(0), '---',result.group(1),'---',result.group(2),'---',result.group(3)) 216 # 0 返回的是匹配到的整个字符串 217 print(result.group(0).encode()) # b'bottle\nbag\nbig' # 为了看到回车,用字节类型 218 219 print(result.group('name2')) 220 print(result.groupdict()) # {'name2': 'bag', 'name3': 'big'} 221 222 223 print('-------------------------------') 224 s = '''bottle\nbag\nbig\napple''' 225 # 1 226 print('-------------1------------------') 227 regex = re.compile('(b\w+)\n(?P<name2>b\w+)\n(?P<name3>b\w+)',re.I ) 228 result = regex.findall(s) 229 print(result, type(result)) 230 for x in result: 231 print(x,type(x), end='----') 232 print() 233 # 2 234 print('-------------2------------------') 235 regex = re.compile('(b\w+)\n(?P<name2>b\w+)' ,re.M) 236 result = regex.findall(s) 237 print(result) 238 for x in result: 239 print(x, end='----') 240 print() 241 # 3 242 print('--------------3-----------------') 243 regex = re.compile('(b\w+)\n' ) 244 result = regex.findall(s) 245 print(result) 246 for x in result: 247 print(x, end='----') 248 print() 249 250 # 4 251 print('--------------4-----------------') 252 regex = re.compile('(b\w+)' ) 253 result = regex.findall(s) 254 print(result) 255 for x in result: 256 print(x, end='----') 257 print() 258 259 260 261 regex = re.compile('(?P<head>b\w+)') 262 result = regex.finditer(s) 263 for i in result: 264 print(type(i), i, i.group(), i.group('head'))
1 ************macth************* 2 <re.Match object; span=(0, 1), match='b'> 3 None 4 None 5 None 6 ********macth-compile********* 7 None 8 <re.Match object; span=(15, 16), match='a'> 9 ************search************ 10 <re.Match object; span=(8, 9), match='a'> 11 <re.Match object; span=(7, 8), match='b'> 12 1 <re.Match object; span=(0, 1), match='b'> 13 2 <re.Match object; span=(7, 8), match='b'> 14 **********fullmatch*********** 15 None 16 None 17 None 18 <re.Match object; span=(7, 10), match='bag'> 19 ***********findall************ 20 ['b', 'b', 'b', 'b'] 21 re.compile('^b') 22 ['b'] 23 ['b', 'b'] 24 ['b', 'b', 'b', 'b'] 25 ['b'] 26 ['b'] 27 ***********finditer*********** 28 1 <re.Match object; span=(0, 1), match='b'> 29 1 <re.Match object; span=(7, 8), match='b'> 30 1 <re.Match object; span=(11, 12), match='b'> 31 <callable_iterator object at 0x0000000001DC2160> 32 <class 'callable_iterator'> 33 ------------------匹配替换------------------ 34 bottle 35 magedu 36 magedu 37 apple 38 bottle 39 magedu 40 big 41 apple 42 ('bottle\tbag\tbig\tapple', 3) 43 ------re.spilt------------ 44 <class 'list'> 45 ['01 bottle', 'bag', 'big1', 'able'] 46 ['', 'bottle', 'bag', 'big', 'able'] 47 ------- 分组 ----------- 48 <class 're.Match'> 49 1 match ('bottle',) 50 <re.Match object; span=(0, 6), match='bottle'> 51 <class 're.Match'> 52 1 match ('b', 'ottle') 53 <re.Match object; span=(7, 10), match='bag'> bag 54 ----- 命名分组-------- ------------ 55 <re.Match object; span=(0, 14), match='bottle\nbag\nbig'> +++++ 56 ('bottle', 'bag', 'big') 57 bottle 58 bag 59 big --- bottle --- bag --- big 60 b'bottle\nbag\nbig' 61 bag 62 {'name2': 'bag', 'name3': 'big'} 63 ------------------------------- 64 -------------1------------------ 65 [('bottle', 'bag', 'big')] <class 'list'> 66 ('bottle', 'bag', 'big') <class 'tuple'>---- 67 -------------2------------------ 68 [('bottle', 'bag')] 69 ('bottle', 'bag')---- 70 --------------3----------------- 71 ['bottle', 'bag', 'big'] 72 bottle----bag----big---- 73 --------------4----------------- 74 ['bottle', 'bag', 'big'] 75 bottle----bag----big---- 76 <class 're.Match'> <re.Match object; span=(0, 6), match='bottle'> bottle bottle 77 <class 're.Match'> <re.Match object; span=(7, 10), match='bag'> bag bag 78 <class 're.Match'> <re.Match object; span=(11, 14), match='big'> big big
如果遇到这样的切割问题:
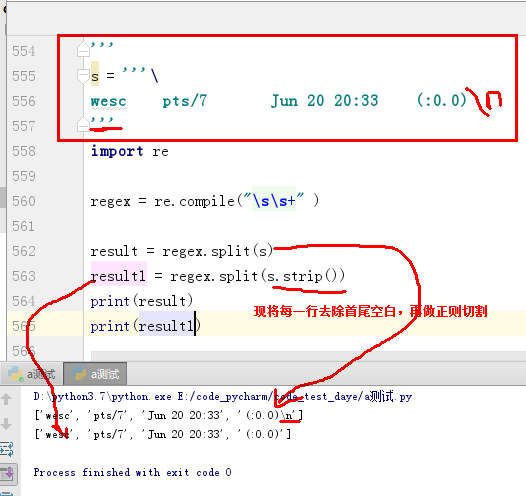
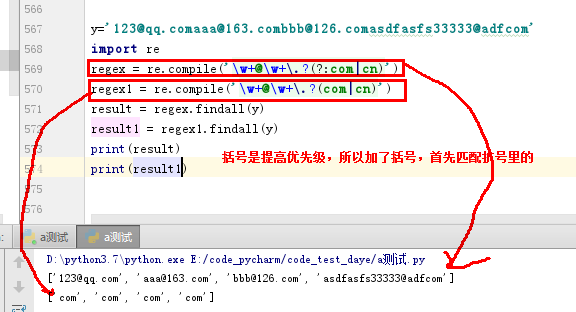
括号优先级的理解:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号