

NN Q&A
Q1: 手写数字识别为什么不用二进制而用向量表示结果?
A:图形的形状要素与二进制数值最高位很难建立联系。当然如果要求输出结果为二进制,只需要再加一层神经元即可,将向量表转换成二进制。
Q2:泛化?
A:机器学习的核心指标,表示模型对未见过的数据的适应与预测能力,可以类比人类的学习过程。
提升泛化能力的主要途径:1、选择适当的网络深度和神经元数量,2、数据增强、合理采样,3、动态调整学习率,采用正则化技术。
Q3:交叉熵
A: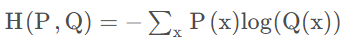
交叉熵损失函数适用于分类任务,概率分布优化,均方误差适用于回归,连续值预测。
Q4:正则化
模型训练阶段对权重参数进行约束
一、L1正则化(稀疏性约束)
函数名: L1 或 l1
语法示例:
点击查看代码
from tensorflow.keras import regularizers
#方式1:直接设置正则化系数(推荐)
model.add(tf.keras.layers.Dense(
units=64,
activation='relu',
kernel_regularizer=regularizers.L1(l1=0.01) # L1正则化,系数λ=0.01
))
#方式2:快捷函数(等效写法)
model.add(tf.keras.layers.Dense(
units=64,
activation='relu',
kernel_regularizer=regularizers.l1(0.01)
))
二、L2正则化(权重衰减)
函数名: L2 或 l2
语法示例:
点击查看代码
#方式1:显式指定正则化类型
model.add(tf.keras.layers.Conv2D(
filters=32,
kernel_size=(3,3),
kernel_regularizer=regularizers.L2(l2=0.001) # L2正则化,系数λ=0.001
))
#方式2:快捷函数
model.add(tf.keras.layers.Dense(
units=10,
activation='softmax',
kernel_regularizer=regularizers.l2(0.001)
))
点击查看代码
#同时应用L1和L2正则化(λ1=0.01, λ2=0.001)
model.add(tf.keras.layers.Dense(
units=128,
kernel_regularizer=regularizers.L1L2(l1=0.01, l2=0.001)
))
点击查看代码
import tensorflow as tf
from tensorflow.keras import layers, regularizers
#定义带正则化的模型
model = tf.keras.Sequential([
layers.Dense(64, activation='relu',
kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.005)), # 弹性网络正则化
layers.Dense(10, activation='softmax',
kernel_regularizer=regularizers.l2(0.001)) # 输出层L2正则化
])
#编译模型
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号