【高级数据结构】树状数组入门指南
 树状数组刨析
树状数组刨析
树状数组(Binary Indexed Tree)
一.前言
我猜你是因为在遇到某些区间问题费劲心思却始终TLE,一看题解原来有个叫树状数组的东西所以来到这的吧(喜)。树状数组是高级数据结构中 比较容易写() 编码量比较少的数据结构。但他能够高效的维护一些动态区间和问题。如果你有前缀和的基础,那么这篇文章能带你完美的入门树状数组,如果没有,我未来会出一篇专门讲前缀和与差分的文章,如果没出,那当我没说🌝()。
二.问题引入
当我们在处理一些静态区间加和问题时,假设对序列\(a\)有\(m\)次询问,序列长\(n\),如果我们对其进行暴力加和,我们将得到一个时间复杂度为\(\Theta(mn)\)的算法,这显然是不行的,你不会想\(n^2\)过百万吧(恼)。于是我们用到了前缀和这种手段对序列预处理得到原序列的前缀和序列\(F\)。
即前缀和序列\(F[i]=\sum_{j=1}^i{a[j]}\)
我们可以在\(\Theta(n)\)的时间内使用递推公式\(F[i]=a[i]+F[i-1]\)得到。
当我们需要查询区间\(L\rightarrow R\)的区间和时可以通过\(\Theta(1)\)的一次减法得到,结果显然就是\(F[R]-F[L-1]\)?什么你看不懂那就给你个简单推导一下吧🌝
\(\sum_{j=L}^R{a[j]}=\sum_{k=1}^R{a[k]}-\sum_{g=1}^{L-1}{a[g]}\)
正如上面所加粗的“静态”。当区间发生动态变化时,前缀和数组就会被打乱,我们需要重新处理前缀和数组。假设有\(m\)次修改,则需要\(\Theta(mn)\)的时间,这还不如不处理呢(doge)。所以我们需要一种高级的数据结构对区间和进行高效维护,我们这篇文章所要讨论的就是其中的一种:树状数组。
三.树状数组简介
既然我们需要对一个长度为\(n\)的大区间进行整体维护,毫无疑问我们不能对这么大的区间进行暴力修改,查询。我们必须要把这个大区间分成若干的小区间进行整体维护,通过若干个小区间的整体操作来维护这个巨大的区间。那么如何拆分这个区间呢。一种比较容易让我们想到的是分治法,类似归并排序把一个大区间不断一分为二,这个分治会需要消耗大量的空间我们把这个数据结构叫做线段树。 本文不展开,因为怕你们混淆了。 而与线段树不同的是,正如他的英文名,树状数组通过巧妙的二进制划分把大区间分解成了若干个小区间之和。仅用到\(n\)的空间便实现了区间的维护。
四.树状数组的构造
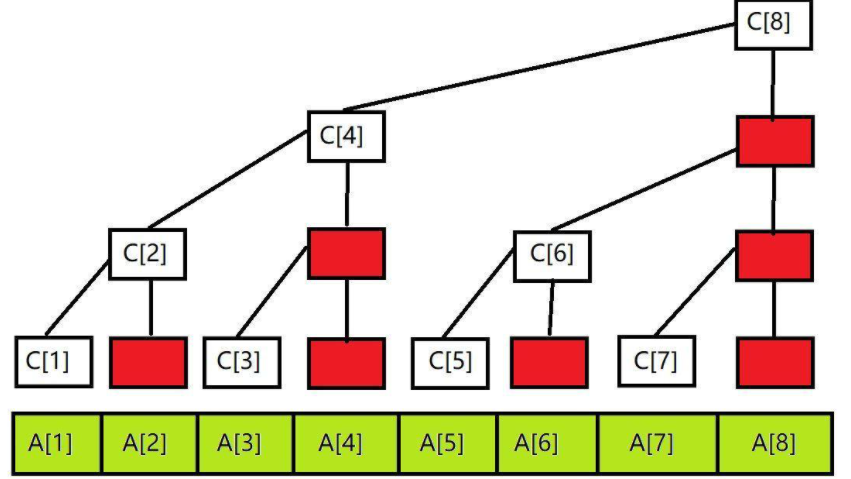
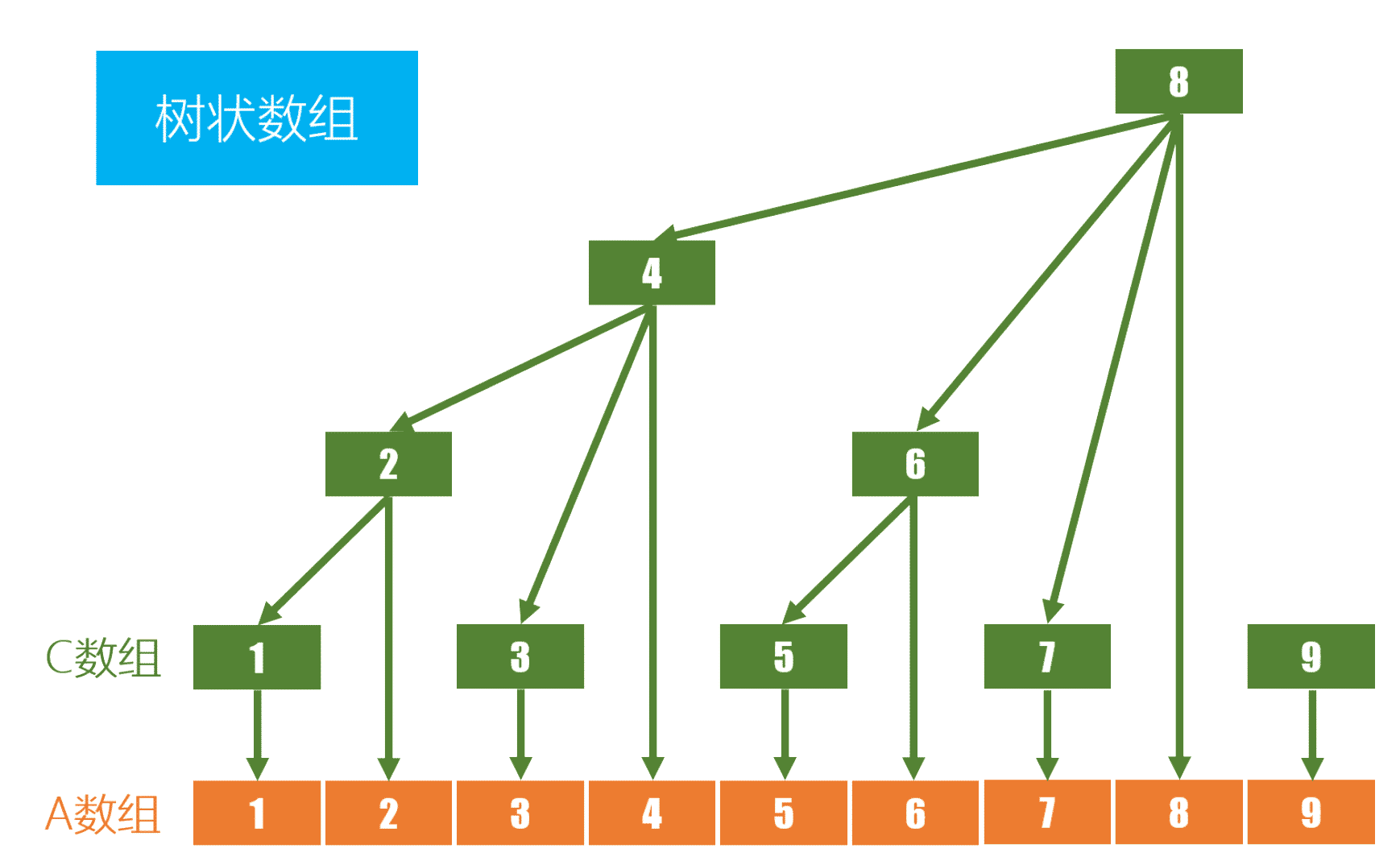
众所周知任何一个实数都能分解成若干个\(2^k\)次幂。例如\(7=2^2+2^1+2^0\),树状数组利用了这个性质把\([1,7]\)区间和分解成了\([1,4]\),\([5,6]\),\([7]\)。同理任何一个\([1,n]\)的区间都能按这个性质分解。我们令\(c[N]\)为树状数组,其中\(c[k]\)表示以k元素所在的小区间之和,例如\(c[6]=a[5]+a[6]\)。那么我们如何知道每一个\(c[k]\)所包含的区间是什么呢?先把k变成 二次元 说错了,是二进制。例如是6我们可以得到\(110\),通过二进制我们可以得到\(6=2^2+2^1\),观察末位的数,我们不难得出以\(6\)结尾的区间是\([6-2^1+1,6]\)。你发现规律了吗!假设\(x\)是\(k\)二进制下最后一个\(1\)与末位所有的\(0\)构成的数😆,那么\(c[k]\)储存的区间是\([k-x+1,k]\)! 通过此划分方式我们可以得到一个重要的性质\(c[k]\)的长度是\(lowbit(k)\)。
那么我们应该如何获取这个奇妙的\(x\)呢,这就设计到了一个更加巧妙(疯狂)的运算了,他叫做\(lowbit\)!我们可以通过下面的位运算得到\(lowbit(x)\)。
int lowbit(int x){
return x&-x;
}
为什么把\(x\)位与\(-x\)就能得到\(x\)二进制下最后一个1与剩余0构成的数呢?这个是网上大部分blog与书籍都没有解释的。 我浅浅抽象的解释一下 。众所周知在机器内部一个数的负数用补码表示法储存,即符号位不变,其他位取反,最后\(+1\)。我们把\(x\)取负数相当于在二进制下把x所有的\(0\)变成了\(1\),\(1\)变成了\(0\),我们再让得到的数+1,就能当取反状态下的最后一个\(0\)变为\(1\)(因为\(+1\)后取反得到\(1\)即原来的\(0\)都会向前进位)。因为进位的关系后面的\(1\)都变成了\(0\),那些变成\(0\)的\(1\),在原数下一定是\(0\)。 这不是废话吗,取反后变成1那原来肯定是0啊。 在经过\(+1\)后,取反状态下最后的\(0\)即原来的\(1\)发生了变化,同时取反状态下这个\(0\)后面的\(1\)即原来的\(0\)因为\(+1\)后的进位变成了\(0\)。再经过位与操作,我们不难发生只有取反状态下二进制最后中的\(0\)即原来的\(1\)发生了变化变为了\(1\)经过位与操作下变成了1,而这个位之前由于都被取反了位与后必定是0,而这位之后原状态与取反状态下均为\(0\)所以也都是\(0\)。那么我们就获得了一个数二进制下最后一个1与末位的0所构成的数。 好一个废话连篇的长篇大论啊😭😭😭。
按照上述划分规则,我们可以把树状数组虚拟一颗树(当\(n\)为\(2\)的整数次幂时)或一个森林。注意:树状数组并不是一种以父子结构储存的树形结构,他是基于二进制划分的,子节点所储存的区间包含于父节点。
该图片选自http://m.mamicode.com/info-detail-3030253.html
观察树状数组,我们可以发现4个性质,我尝逝一下证明()。
性质一
树状数组\(c[k]\)储存的信息是原数组\(a\)中\(a[k-lowbit(k)+1]\rightarrow a[k]\)中的整体区间信息,其长度为\(lowbit(k)\),这是树状数组的划分性质,属于公理。
性质二
数状数组每一个节点\(x\)的父节点都是\(x+lowbit(x)\),即\(x\)所储存的区间信息是\(x+lowbit(x)\)的子集,由 性质一 ,\(c[x]\)中储存\(a[x-lowbit(x)+1]\rightarrow a[x]\),而\(c[x+lowbit(x)]\)中储存了\(a[x+lowbit(x)-lowbit(x+lowbit(x))+1]\rightarrow a[x+lowbit(x)]\)。
接下来开始手写证明 ~~(因为网上根本没有详细证明都是一笔带过) ~~
因为是树状数组,索引即\(x\)不等于0,观察\(lowbit(x+lowbit(x))\)其中\(x+lowbit(x)\)可以看作将\(x\)二进制下的\(1\)向前推,又由于\(x\)二进制下最后一位被向前推了一位,所以再次对改变\(x\)取\(lowbit\)运算时,得到的结果至少比原来\(lowbit(x)\)增大了一倍,当推位时只有顶位为1时取等,这个可以当做引理证明当且仅当\(k\)为\(2\)的整数次幂时\(c[k]\)与\(c[k+lowbit(k)]\)左端点相同。回到推理,由于\(lowbit(x+lowbit(x))\)至少比\(lowbit(x)\)大一倍。所以\(x+lowbit(x)-lowbit(x+lowbit(x))<=x-lowbit(x)\),所以\(c[k+lowbit(k)]\)的左端点小于等于\(c[k]\)的左端点。显然易见\(x<x+lowbit(x)\),即\(c[k]\)的右端点小于\(c[k+lowbit(x)]\)。\(c[k]\)的左端点大于等于\(c[k+lowbit(k)]\)的左端点,\(c[k]\)的右端点小于\(c[k+lowbit(k)]\)的右端点,所以\(c[k]\)所表示的区间包含于\(c[k+lowbit(k)]\)的区间,即\(c[k]\)的父节点是\(c[k+lowbit(k)]\),性质得证。
性质三
数状数组每一个节点\(x\)的子节点是每一个满足\(k+lowbit(k)=x\)的节点\(k\),这可以通过性质一逆向证明。但无法通过\(\Theta(1)\)的时间获取,只能从\(k\)开始逐个减去0到\(2\)的整数次幂并检验其\(+lowbit\)自身是否等于\(x\)来查找\(x\)的子节点。
性质四
树状数组的深度是\(\log_2 n\)由 性质一 由于一个2的最高整数幂的\(lowbit\)是最大的,所以他包含的子区间是最多的。所以树的最高点为\(2^k,(k<\log_2 n)\)。深度即为\(\log_2 n\)。而其他点位置分布是呈二进制均匀分布的,这也能通过 性质一 得到,因为\(lowbit\)函数通过二进制下运算,当两者末位1位置相同时,得到结果是相同的。所以某一节点到树顶部的平均距离为\(\log_2 n\)。
五.树状数组的基本应用
1.单点修改,区间查询
既然我们上一个章节已经完整的介绍了数状数组的构造方式。那么我们该如何应用数状数组呢?我们先从修改讲起!当我们对单点增加\(k\)时,通过 性质二 ,我们可以发现对单点增加时会对他的父节点也就是\(x+lowbit(x)\)由于包含这个子节点,所以他也应该增加相同的数值,同理他的父节点的父节点也会产生影响。通过这一性质我们便可以循环增加\(x\)的父节点也就是\(x+lowbit(x)\)的值来实现动态的加和维护。
void add(int x, int k){
for(;x<=n;x+=lowbit(x)) c[x]+=k;
}
通过 性质三 我们可以得到该单点修改的时间复杂度为\(\Theta (\log_2 n)\)。
当我们需要查询前缀和时,由于树状数组将区间\([1,x]\)按\(x\)的二进制进行划分,我们只需要不断将\(x-lowbit(x)\)获取上一个小区间,最后将这些小区间和相加即可。例如\(7=2^2+2^1+2^0=(111)_2\)。\([1,7]\)被划分成\([1,2^2]\),\([2^2+1,2^2+2^1]\),\([2^2+2^1+1,2^2+2^1+2^0]\)。我们只需要每次减去\(lowbit(x)\)就能获得上一块区间的加和即\(c[x-lowbit(x)]\)。
int query(int x){
int ans=0;
for(;x;x-=lowbit(x)) ans+=c[x];
return ans;
}
这个函数可以实现查询前缀和功能,而对于\([L,R]\)的区间和,我们只需要\(query(r)-query(l-1)\)即可。通过 性质四 我们发现树状数组区间查询的时间复杂度也为\(\Theta(log_2 n)\)。对于树状数组的初始化也很简单,对每个节点都加上对应的a的值即可。
以下是树状数组最主要的应用—— 单点修改,区间查询 的模板代码(题目是洛谷P3374)。供参考。
#include<iostream>
using namespace std;
const int N = 5e6+10;
int c[N],a[N],n;
int lowbit(int x){
return x&-x;
}
void add(int x, int value){
for(;x<=n;x+=lowbit(x)) c[x]+=value;
}
int query(int x){
int ans=0;
for(;x;x-=lowbit(x)) ans+=c[x];
return ans;
}
int main()
{
int m;scanf("%d%d",&n,&m);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
for(int i=1;i<=n;++i) add(i,a[i]);
while(m--){
int c;scanf("%d",&c);
if(c-1){
int l,r;
scanf("%d%d",&l,&r);
printf("%d\n",query(r)-query(l-1));
}
else{
int x,k;scanf("%d%d",&x,&k);
add(x,k);
}
}
return 0;
}
2.区间修改,单点查询
树状数组最主要的用途是 单点修改,区间查询 ,但是我们仍能通过构造维护原数组的相对于原来状态的差分数组的方式实现数状数组的 区间修改,单点查询 。当我们需要对区间进行修改时,设左端点\(L\),右端点\(R\)。我们可以对差分数组开始影响的左端点\(add(L,1)\),右端点的后一个端点进行抵消影响\(add(R+1,-1)\)。如果需要查询单点的话,将单点值加上树状数组维护的差分数组前缀和即可。 这是差分数组的基本操作,不懂看我以后的差分文章了🌝 。模板代码(题目为洛谷P3368)。其实你也可以直接维护原数组的差分数组,他的前缀和就是原数组的单点值,效果都一样。
#include<iostream>
using namespace std;
const int N = 5e6+10;
int c[N],a[N],d[N],n;
int lowbit(int x){
return x&-x;
}
void add(int x, int value){
for(;x<=n;x+=lowbit(x)) c[x]+=value;
}
int query(int x){
int ans=0;
for(;x;x-=lowbit(x)) ans+=c[x];
return ans;
}
int main()
{
int m;scanf("%d%d",&n,&m);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
while(m--){
int opt;scanf("%d",&opt);
if(opt-1){
int x;
scanf("%d",&x);
printf("%d\n",a[x]+query(x));
}
else{
int l,r,k;scanf("%d%d%d",&l,&r,&k);
add(l,k);
add(r+1,-k);
}
}
return 0;
}
六.树状数组的局限性及拓展
树状数组通过巧妙的将区间进行二进制划分用极小的空间以及效率实现了动态区间维护。但他有两个明显的缺点。
1.不能直接支持区间修改
上个章节我们通过构造原数组差分数组方法实现了 区间修改,单点查询 。但有明显的缺点是我们无法直接通过差分数组在\(\Theta(\log_2 n)\)的时间内进行 区间查询 。这是由于差分数组体现的是前后元素差,这不能直接应用于查询区间和。
无法在\(\Theta(\log_2 n)\)的时间内直接在原数组进行区间修改的本质是因为树状数组的区间划分。仅仅通过二进制划分的区间传递,我们无法对整段区间进行修改,因为每个数的二进制划分不一定是相同的。只能对单点修改,再通过 性质二 将修改映射于其他包含此点的小区间上。如果强行将区间分成单点进行修改,那么时间复杂度将达到\(\Theta(n\log_2 n)\)。
如果我们想要实现 区间修改,区间查询 的操作,我们需要进行较为复杂的构造。首先因为有区间修改我们必须构造原数组的差分数组,对差分数组两端点进行修改以实现区间修改,当我们对差分数组求前缀和时,得到的是原数组。为了实现区间查询,我们需要构造原数组的前缀和数组,也就是差分数组的前缀和数组的前缀和数组,如果我们暴力维护差分数组的双重前缀和数组,我们需要对每个前缀和数组也就是单点进行累加,复杂度明显不合格。为了高效的求出差分数组的双重前缀和数组,我们需要考虑构造出两个树状数组,通过对他们两个的维护,我们可以获得到差分数组的双重前缀和。对于差分数组的双重前缀和数组我们有以下推导。
通过上面的数学推导你发现了什么?我们可以通过分别维护差分数组\(d\)以及差分数组与其下标的乘积数组\(d[i]*i\)再将他们俩分别查询前缀和后相加就能得到原数组的前缀和!时间复杂度为\(\Theta(log_2 n)\)。以下是实现代码。
#include<iostream>
using namespace std;
const int N = 5e6+10;
int d[N],c[N],c1[N],m,n,a[N];
int lowbit(int x){
return x&-x;
}
void add(int x, int value){
for(int i=x;i<=n;i+=lowbit(i)) c[i]+=value,c1[i]+=value*x;
}
int query(int x){
int ans=0;
for(int i=x;i;i-=lowbit(i)) ans+=(x+1)*c[i]-c1[i];
return ans;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
for(int i=1;i<=n;++i) add(i,a[i]-a[i-1]);
while(m--){
int opt;scanf("%d",&opt);
if(opt-1){
int l,r;
scanf("%d%d",&l,&r);
printf("%d\n",query(r)-query(l-1));
}
else{
int l,r,k;scanf("%d%d%d",&l,&r,&k);
add(l,k);
add(r+1,-k);
}
}
return 0;
}
2.由于 性质三 不能迅速的进行非可叠加性的区间修改。
在本文上述,讨论的都是 区间加和 这类小区间可以直接叠加到大区间的操作。我们可以直接通过查询两点的前缀和做差获取。然而对于小区间不能直接叠加到大区间的区间类型,例如区间最值,我们不能直接通过简单的两个单点查询而得到答案。这是因为前缀和我们可以将其看作以区间右端为基准不断通过之前区间划分的二进制得到的小区间进行累加得到。而前缀和这类区间查询因为和的可叠加性我们可以将其转换为两个单点前缀和之差。而对于区间最值的查询,由于没有前缀和的叠加性质,我们必须从进行完整的区间查询开始,从左端点开始检查,判断是否与右半边构成树状数组维护的整块区间,如果能够构成,则整块判断,不能则单独处理该端点,继续判断下一个端点。 有点类似分块的思想,感觉常数有点大 。因为我们可以通过直接划分查询区间再通过对应树状数组维护的区间的值来处理区间最值,相对于加和而言只是麻烦了点没有本质的影响。
然后对于区间修改而言,由于区间的非可叠加性,我们不能像处理区间和问题那样直接通过父节点向上传递和,因为从小区间向大区间传递最值还需要与大区间的其他小区间进行比较,所以我们每当我们向上传递树状数组的更新,我们需要与上一级大区间的其他小区间做比较,这就需要求出大区间的所有小区间也就是父节点的所有子节点。 由 性质三 可以获取到每个子节点。由于一个父节点共有\(\Theta(\log_2 n)\)个子节点而我们需要向上传递\(\Theta(\log_2 n)\)层,所以单次修改的时间复杂度为\(\Theta(\log_2^2 n)\),不能继续优化,劣于线段树,而且构造想法比较难,需要读者对树状数组结构的充分理解。还是建议大家用线段树维护动态区间问题,用ST表维护静态区间问题。 我竟然写一遍就过了,我甚至不敢相信,让朋友检查了好几遍,如果代码有问题或者过于繁杂还请提出 。
#include<iostream>
using namespace std;
const int N = 5e6+10;
int d[N],c[N],c1[N],m,n,a[N];
int lowbit(int x){
return x&-x;
}
void change(int x, int v){
a[x]=v;
for(int i=x;i<=N;i+=lowbit(i)){
c[i]=a[i];//单点必定是当前节点的一个儿子
for(int k=1;i-k>0;k<<=1){
if(i-k+lowbit(i-k)==i) c[i]=max(c[i],c[i-k]);//寻找当前节点的子节点,用于更新最值
else break;//当前节点的儿子已经找到头了,不需要继续深入
}
//继续更新当前节点的父亲
}
}
int query(int l, int r){
int ans=a[r];
while(r>=l){
while(l+lowbit(l)<=r&&l+lowbit(l)-lowbit(l+lowbit(l))+1>=l){//寻找被整块维护的区间
ans=max(ans,c[l+lowbit(l)]);//整块更新
l+=lowbit(l);//向深入继续查找整块
}
ans=max(ans,a[l]);//碎块直接处理
++l;//跳过碎块继续前进
}
return ans;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
for(int i=1;i<=n;++i) change(i,a[i]);
while(m--){
int opt;scanf("%d",&opt);
if(opt-1){
int l,r;
scanf("%d%d",&l,&r);
printf("%d\n",query(l,r));
}
else{
int l,k;scanf("%d%d",&l,&k);
change(l,k);
}
}
return 0;
}
虽然树状数组通过巧妙的二进制划分,让区间有二进制性质的包含性质。使让我们可以用极小的内存和编码量实现动态区间修改查询。但树状数组修改时,只能将一个值通过小区间向大区间传递,这是因为每个区间的划分是由二进制决定的, 树状数组是一段畸形的多叉树或森林 ,这直接导致了树状数组无论如何扩展都不能实现对于数组本身的区间修改,我们只能在特定的区间问题,例如区间和问题,通过构造差分数组等方式将区间修改转换成多个单点修改。树状数组的畸形树性质也导致了我们无法对迅速的修改一段大区间所包含的小区间,这导致了例如区间最值这类不能直接往父节点叠在而是需要其他子节点的问题的复杂度多了一个对数级。举个不恰当例子, 树状数组就像你们讨厌的小情侣们,一对有一对,如果你想修改那个人的恋人,让关系再次达到平衡是非常容易的,让\(\log_2 n\)个人的关系发生改变就行了,这就是 单点修改 。但如果你想改变一个班的关系链,这太难了!因为有一堆奇葩的关系,你只能给每个人都给一改要用\(n\log_2 n\)的时间,有可能你毕业前都做不完,这是件不可能的事件,这就是 区间修改 。同理如果你想了解一个班的所有关系链,你就需要对每个人的恋人以及恋人的朋友进行了解。这就是 非可叠加区间询问 。要\(\log_2^2 n\)的时间。所以说OIer从不谈恋爱(doge)。
七.树状数组的离线扫描
对于一段序列,我们需要知道某些元素一共出现多少次,或者有什么加和关系,我们可以通过树状数组进行离线扫描。
例题HH的项链(洛谷P1972)
[SDOI2009] HH的项链
题目描述
HH 有一串由各种漂亮的贝壳组成的项链。HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义。HH 不断地收集新的贝壳,因此,他的项链变得越来越长。
有一天,他突然提出了一个问题:某一段贝壳中,包含了多少种不同的贝壳?这个问题很难回答…… 因为项链实在是太长了。于是,他只好求助睿智的你,来解决这个问题。
输入格式
一行一个正整数 \(n\),表示项链长度。
第二行 \(n\) 个正整数 \(a_i\),表示项链中第 \(i\) 个贝壳的种类。
第三行一个整数 \(m\),表示 HH 询问的个数。
接下来 \(m\) 行,每行两个整数 \(l,r\),表示询问的区间。
输出格式
输出 \(m\) 行,每行一个整数,依次表示询问对应的答案。
样例 #1
样例输入 #1
6
1 2 3 4 3 5
3
1 2
3 5
2 6
样例输出 #1
2
2
4
提示
【数据范围】
对于 \(20\%\) 的数据,\(1\le n,m\leq 5000\);
对于 \(40\%\) 的数据,\(1\le n,m\leq 10^5\);
对于 \(60\%\) 的数据,\(1\le n,m\leq 5\times 10^5\);
对于 \(100\%\) 的数据,\(1\le n,m,a_i \leq 10^6\),\(1\le l \le r \le n\)。
本题可能需要较快的读入方式,最大数据点读入数据约 20MB
观察题目,我们可以发现题目需要我们维护一个区间所含不同元素个数的问题。这是一种时效性区间问题,即每一次新区间更新都会对前区间产生不可逆的影响,我们不能同时维护后段区间状态和前段区间完整状态。针对这种问题如果我们想要实现实时的在线维护只能使用 可持久化数据结构 。 主席树 就是其中一种,然而他的编码非常困难,而且耗时比较高,针对此题的加强版明显吃不消。 我立志写一篇主席树的blog,不知道能不能实现(恼) 。所以我们考虑离线算法,将询问区间离线下来通过合理的排序使各个询问的修改的维护不会产生冲突。我们观察问题,他需要我们求出一段范围内的不相同元素数,于是我们考虑从左到右离线扫描序列,如果发现新的元素就在该位置\(+1\),如果发现已经出现过的元素怎么办?先别急,我们先考虑用什么数据结构吧()。我们发现我们需要维护的显然是一段区间不同元素数之和,是可叠加的。显然可以通过前缀和来查询,于是我们选用树状数组。回到上面的问题,如果我们出现重复元素立刻让重复元素\(+1\),并将之前出现过的元素\(-1\),当我们下一次询问区间的右端点\(<\)\(+1\)然后\(-1\)的位置,我们会导致那个\(+1\)没有算进去然后前面反而被\(-1\)了,导致结果偏小。于是我们考虑让区间按右端点顺序从小到大排序,使每次产生重复修改时,新的询问已经包含的新\(+1\)的点,使扫描过程中动态的过程中询问之间不会产生互相干扰。 对于这种方法我们叫做离线法,即是将询问改变成扫描过程中输出之间结果 。这类方法还要一种叫 莫队算法 ,他编码极其简单,通过用来代替线段树进行区间维护,但是他的代码量和速度还是比不过我们的主角树状数组啊(doge)。以下是具体代码实现。
#include<bits/stdc++.h>
const int N = 1e7;
struct ask{
int l,r,id,ans;
}q[N];
int n,c[N],a[N],vis[N],m;
bool cmp1(ask a,ask b){
return a.r<b.r;
}
bool cmp2(ask a,ask b){
return a.id<b.id;
}
int lowbit(int x){
return x&-x;
}
void add(int x, int v){
for(;x<=n;x+=lowbit(x)) c[x]+=v;
}
int ask(int x){
int ans=0;
for(;x;x-=lowbit(x)) ans+=c[x];
return ans;
}
int main()
{
//freopen("P1972_1.in.txt","r",stdin);
scanf("%d",&n);
for(int i=1;i<=n;++i) scanf("%d",&a[i]);
scanf("%d",&m);
for(int i=1;i<=m;++i) scanf("%d%d",&q[i].l,&q[i].r),q[i].id=i;
std::sort(q+1,q+m+1,cmp1);
int pos=1;
for(int i=1;i<=n;++i){
add(i,1);
if(vis[a[i]]) add(vis[a[i]],-1);
vis[a[i]]=i;
while(i==q[pos].r) q[pos].ans=ask(q[pos].r)-ask(q[pos].l-1),++pos;
if(pos>m) break;
}
std::sort(q+1,q+m+1,cmp2);
for(int i=1;i<=m;++i) printf("%d\n",q[i].ans);
return 0;
}
例题 虔诚的墓主人(洛谷P2154)
[SDOI2009] 虔诚的墓主人
题目描述
小W是一片新造公墓的管理人。公墓可以看成一块 \(N×M\) 的矩形,矩形的每个格点,要么种着一棵常青树,要么是一块还没有归属的墓地。
当地的居民都是非常虔诚的基督徒,他们愿意提前为自己找一块合适墓地。为了体现自己对主的真诚,他们希望自己的墓地拥有着较高的虔诚度。
一块墓地的虔诚度是指以这块墓地为中心的十字架的数目。一个十字架可以看成中间是墓地,墓地的正上、正下、正左、正右都有恰好 \(k\) 棵常青树。
形式化地,对于一个坐标为 \((x, y)\) 的墓地,以其为中心的十字架个数是这样的长度为 \(4k\) 的二元组序列 \([(x_{1,1},y_{1,1}),\allowbreak(x_{1,2},y_{1,2}),\allowbreak\cdots,(x_{1,k},y_{1,k}),\allowbreak(x_{2,1},y_{2,1}),\allowbreak(x_{2,2},y_{2,2}),\allowbreak\cdots,(x_{2,k},y_{2,k}),\allowbreak(x_{3,1},y_{3,1}),\allowbreak(x_{3,2},y_{3,2}),\allowbreak\cdots,(x_{3,k},y_{3,k}),\allowbreak(x_{4,1},y_{4,1}),\allowbreak(x_{4,2},y_{4,2}),\allowbreak\cdots,(x_{4,k},y_{4,k})]\) 的方案数:
- 每一个二元组对应着一棵常青树的坐标;
- \(x_{1,1}<x_{1,2}<\cdots< x_{1,k}<x\) 且 \(y_{1,1}=y_{1,2}=\cdots=y_{1,k}=y\);
- \(x<x_{2,1}<x_{2,2}<\cdots< x_{2,k}\) 且 \(y_{2,1}=y_{2,2}=\cdots=y_{2,k}=y\);
- \(y_{3,1}<y_{3,2}<\cdots< y_{3,k}<y\) 且 \(x_{3,1}=x_{3,2}=\cdots=x_{3,k}=x\);
- \(y<y_{4,1}<y_{4,2}<\cdots< y_{4,k}\) 且 \(x_{4,1}=x_{4,2}=\cdots=x_{4,k}=x\)。
小W希望知道他所管理的这片公墓中所有墓地的虔诚度总和是多少。
输入格式
第一行包含两个用空格分隔的正整数 \(N\) 和 \(M\),表示公墓的宽和长,因此这个矩形公墓共有 \((N+1) ×(M+1)\) 个格点,左下角的坐标为 \((0, 0)\),右上角的坐标为 \((N, M)\)。
第二行包含一个正整数 \(W\),表示公墓中常青树的个数。
第三行起共 \(W\) 行,每行包含两个用空格分隔的非负整数 \(x_i\) 和 \(y_i\),表示一棵常青树的坐标。输入保证没有两棵常青树拥有相同的坐标。
最后一行包含一个正整数 \(k\),意义如题目所示。
输出格式
输出仅包含一个非负整数,表示这片公墓中所有墓地的虔诚度总和。为了方便起见,答案对 \(2{,}147{,}483{,}648\) 取模。
样例 #1
样例输入 #1
5 6
13
0 2
0 3
1 2
1 3
2 0
2 1
2 4
2 5
2 6
3 2
3 3
4 3
5 2
2
样例输出 #1
6
提示
图中,以墓地 \((2, 2)\) 和 \((2, 3)\) 为中心的十字架各有 \(3\) 个,即它们的虔诚度均为 \(3\)。其他墓地的虔诚度为 \(0\)。
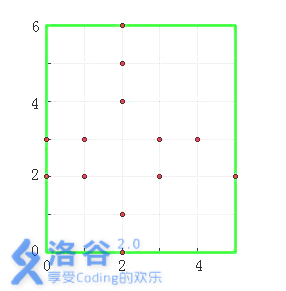
对于 \(30\%\) 的数据,满足 \(1 ≤ N, M ≤ 10^3\)。
对于 \(60\%\) 的数据,满足 \(1 ≤ N, M ≤ 10^6\)。
对于 \(100\%\) 的数据,满足 \(1 ≤ N, M ≤ 10^9\),\(0 ≤ x_i ≤ N\),\(0 ≤ y_i ≤ M\),\(1 ≤ W ≤ 10^5\),\(1 ≤ k ≤ 10\)。
存在 \(50\%\) 的数据,满足 \(1 ≤ k ≤ 2\)。
存在 \(25\%\) 的数据,满足 \(1 ≤ W ≤ 10^4\)。
首先我们观察地图大小,发现\(M\)和\(N\)已经达到\(10^9\)了!这大小\(\Theta(n)\)都吃力啊,但是我们发现\(W\)就小很多了,于是我们考虑把\(x\)和\(y\)离散化,这不会对结果产生影响,毕竟只有几颗树中间的点才有价值是吧,然后我们考虑把点按\(x\)为第一关键词\(y\)为第二关键词排序,方便我们扫描。我们从x轴开始扫描。通过 组合数学 。我们可以得知相同x值间的两个点之间的点的价值总和为(D,U,L,R分别表示下上左右分别还有几颗树)。
当我们对一个\(x\)上所有点求价值和时,我们从\(y\)值最高的点向下扫描时,我们不难发现\(C_{D_i}^k * C_{U_i}^k\)很容易求,因为\(y\)值相同点我们是已知的。于是将表达式变形得。
我们需要维护的便是一段\(y\)之间\(C_{L_i}^k * C_{R_i}^k\)的片段和,于是我们采用树状数组,当\(x\)轴的扫描过程中\(y\)轴上某点出现新的树时,就动态修改\(C_{L_i}^k * C_{R_i}^k\)的值。这里还有一个小技巧为了能够在常数时间内获取组合数的值,我们采用组合数递推公式预处理组合数。 什么递推?矩阵快速幂(幻视) 。\(C^i_j = C^i_{j-1} + C^{i-1}_{j-1}\),我们初始化每个\(i=0\)的位置就行了!以下是实现代码,供参考。 又A了道紫题啦!(喜) 。
#include<bits/stdc++.h>
#define loop for(int i=1;i<=w;++i)
#define int long long
using namespace std;
const int N = 1e5+10;
const int M = 2147483648;
int c[11][N],n,m,w,tree[N],tot[N],vis[N],k,ans;
struct node{int x,y;} q[N];
inline int read(){
char c;
bool flag=false;
while((c=getchar())<'0'||c>'9') if(c=='-') flag=true;
int res=c-'0';
while((c=getchar())>='0'&&c<='9') res=(res<<3)+(res<<1)+c-'0';
return flag? -res:res;
}
bool cmp(node n1,node n2){
if(n1.x==n2.x) return n1.y<n2.y;
return n1.x<n2.x;
}
void read_discrete(){
int a[N],b[N];
int cnt_a,cnt_b;
loop{
q[i].x=read(),q[i].y=read();
a[i]=q[i].x;
b[i]=q[i].y;
}
k=read();
sort(a+1,a+w+1);sort(b+1,b+w+1);
cnt_a=unique(a+1,a+w+1)-a-1;cnt_b=unique(b+1,b+w+1)-b-1;
loop q[i].x=lower_bound(a+1,a+cnt_a+1,q[i].x)-a;
loop q[i].y=lower_bound(b+1,b+cnt_b+1,q[i].y)-b;
}
int lowbit(int x){
return x&-x;
}
void add(int x, int v){
for(;x<=w;x+=lowbit(x)) tree[x]=(tree[x]+v)%M;
}
int ask(int x){
int ans=0;
for(;x;x-=lowbit(x)) ans=(ans+tree[x])%M;
return ans;
}
signed main()
{
//freopen("test.txt","r",stdin);
n=read(),m=read(),w=read();
read_discrete();
for(int i=0;i<=w;++i) c[0][i]=1;
for(int i=1;i<=10;++i) for(int j=1;j<=w;++j) c[i][j]=(c[i][j-1]+c[i-1][j-1])%M;
sort(q+1,q+w+1,cmp);
loop ++tot[q[i].y];
int pos=1;
while(pos<=w){
int temp[N],cnt=0;
while(q[pos].x==q[pos+1].x) ++cnt,temp[cnt]=q[pos].y,++pos;
++cnt,temp[cnt]=q[pos].y,++pos;
for(int i=k;i<=cnt-k;++i){
int l=temp[i]+1,r=temp[i+1]-1;
ans+=(ask(r)-ask(l-1))*c[k][i]*c[k][cnt-i];
}
for(int i=1;i<=cnt;++i){
int v=vis[temp[i]];
int prev=c[k][v]*c[k][tot[temp[i]]-v];
++vis[temp[i]];
int now=c[k][v+1]*c[k][tot[temp[i]]-v-1];
add(temp[i],now-prev);
}
}
printf("%lld",(ans%M+M)%M);
return 0;
}
八.后言( 废话 )
经过三天的奋笔疾书,我完成了这篇文章,对树状数组做了彻底且深入的分析。初衷是因为网上大部分blog以及辅导书都没有对树状数组的结构进行深度刨分,而是简单的讲一下区间二进制划分就过了,然后再给你几个模板。然后数据结构这种东西,不是你套几个模板就会做所有题了,况且万一你忘了模板,你甚至学过一道题的数据结构却最后拿不到分。只有了解数据结构的本源才能真正的学会数据结构所能解决的问题,而不是依赖于某个数据结构。下周奋战线段树的文章!大家敬请期待!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号