requests关于Exceeded 30 redirects问题得出的结论
首先说结论,发送requests请求必须带上headers否则无法保持bs之间的会话。从而报上述的错误。
昨天一个朋友在爬网页时出现的一个问题,以及后续我对这个问题进行了简单的测试。
先说出现的问题的简单描述。
首先是使用urllib请求网页:
#urllib.request发起的请求 import urllib.request response = urllib.request.urlopen("https://baike.baidu.com") html = response.read().decode('utf8') print(type(html)) print(html)
结果正常显示了百科的页面信息:

我们使用requests来请求这个https页面
#requests发起的请求 import requests html = requests.get('https://baike.baidu.com') print(type(html)) print(html)
然后报错了:

报错是重定向超过三十个,百度的结果是取消默认允许的重定向。
到这里我们得出第一条结论:
urllib和requests发送的请求默认会根据响应的location进行重定向。
百度了一下,根据众网友的一致推荐,我们关闭allow_redirects这个字段。
看一看源码里默认是允许重定向的。

关闭了重定向以后,页面不再跳转。
#requests发起的请求,关闭重定向 import requests html = requests.get('https://baike.baidu.com', allow_redirects=False).text print(type(html)) print(html)
禁止了重定向页面必然不能显示正常的百科主页了,这里我们得到的是302的跳转页面。

再次表明一下,百度里总有一些人只解决当前一个问题而不说明解决思路,或者试出来的结果就放上来当作回答的行为是很不负责的。
这里重定向的问题根本不在于页面跳转了,而是页面为什么会多次跳转。
我查到一篇关于请求亚马逊超出重定向限制的文章:http://www.it1352.com/330504.html。
简单来说就是没有与服务器建立会话,页面重定向成了环形的死循环。即你的原始URL重定向一个没有新的URL B,其重定向到C,它重定向到B,等等。
文章的结尾提到加请求头来保持会话的持久性。
#requests发起的请求,添加请求头 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} html = requests.get('https://baike.baidu.com', headers=headers).text print(type(html)) print(html)
请求的页面应当是正确的,但是却出现了如下乱码:
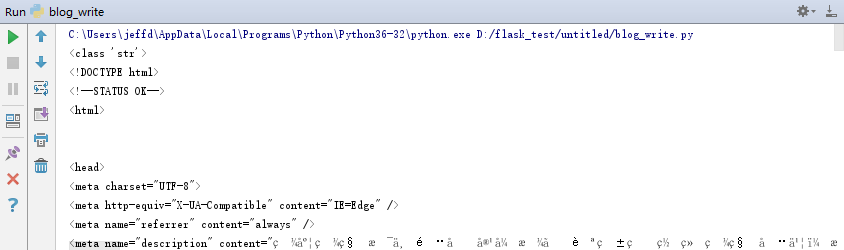
本文的第二个结论也出来了:http头部没有编码方式,requests默认使用自己的编码方式。也是很任性,具体关于requests的乱码行为的出现原因及解决方案,在这篇博客有详细介绍,可以看一下。https://www.cnblogs.com/billyzh/p/6148066.html。
#requests发起的请求,解决乱码问题 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} html = requests.get('https://baike.baidu.com', headers=headers).content.decode('utf8') print(type(html)) print(html)
此时页面显示无异常,正确显示百科的地址。

#requests发起的请求,加上重定向禁止 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} html = requests.get('https://baike.baidu.com', headers=headers, allow_redirects=False).content.decode('utf8') print(type(html)) print(html)

结果没有影响,所以前面提到的解决重定向问题解决方案,多数人提到的禁止重定向根本无效,根本在于保持会话,防止重定向进入死循环。
本文结论三:多Google少百度(只针对技术性问题)。
到这里我们到底在模拟发送请求时请求头带了哪些东西导致的出现上面的问题呢?只能一步步分析请求头的信息。
#urllib请求时发送的请求头 import urllib.request request = urllib.request.Request("https://baike.baidu.com") print(request.headers)#{} print(request.get_header("User-agent"))#None

但实际上肯定是不能发送一个空的请求头的,所以我们抓包获取发送的请求信息。
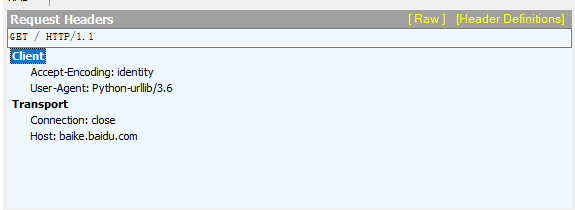
urllib的响应头
#urllib请求时回应的响应头 import urllib.request request = urllib.request.urlopen("https://baike.baidu.com") print(request.headers)

urllib在请求的时候什么也没做,请求头也没东西,然而服务器对他温柔以待,响应了正确的跳转页面。
#requests请求超出30次重定向,暂时无法得到他的请求头 import requests h=requests.get('https://baike.baidu.com') print(h.request.headers)
同理响应头我也看不到。
#requests阻止重定向他的请求头 import requests h=requests.get('https://baike.baidu.com', allow_redirects=False) print(h.request.headers)
{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
User-Agent表示了自己是python解释器的请求。
#requests阻止重定向他的响应头 import requests h=requests.get('https://baike.baidu.com', allow_redirects=False).headers print(h)
{'Connection': 'keep-alive', 'Content-Length': '154', 'Content-Type': 'text/html', 'Date': 'Wed, 31 Jan 2018 04:07:32 GMT', 'Location': 'https://baike.baidu.com/error.html?status=403&uri=/', 'P3p': 'CP=" OTI DSP COR IVA OUR IND COM "', 'Server': 'Apache', 'Set-Cookie': 'BAIDUID=C827DBDDF50E38C0C10F649F1DAAA462:FG=1; expires=Thu, 31-Jan-19 04:07:32 GMT; max-age=31536000; path=/; domain=.baidu.com; version=1'}
连接是keep alive,有location显示重定向地址。
#requests带上自己浏览器信息的请求头 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} h=requests.get('https://baike.baidu.com', allow_redirects=False,headers=headers) print(h.request.headers)
{'User-Agent': 'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
#requests带上自己浏览器信息的请求头,默认允许重定向 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} h=requests.get('https://baike.baidu.com',headers=headers) print(h.request.headers)
与上面一样,再次验证阻不阻止页面重定向不是解决问题的关键点。
根据上面的测试,我有一个大胆的猜测,urllib请求会被服务器接受并响应了setcookie字段,有了cookie创建一个会话最后保证了重定向的正常请求到一个最终的页面,但是requests不加请求头并不会被服务器返回setcookie,产生环形的重定向,最终无法定位到跳转的页面,而加上请求头User-Agent字段,那么服务器默认会建立会话保证跳转到正常的页面。
补充一点,结论是不加请求头,requests无法保证与服务器之间的会话,每次连接服务器都被当作一条新请求直接让他跳转,不存在重定向环路的问题。
# #requests禁止跳转的请求头 import requests h=requests.get('https://baike.baidu.com', allow_redirects=False,verify=False) print(h.request.headers)
抓到的get的请求包:
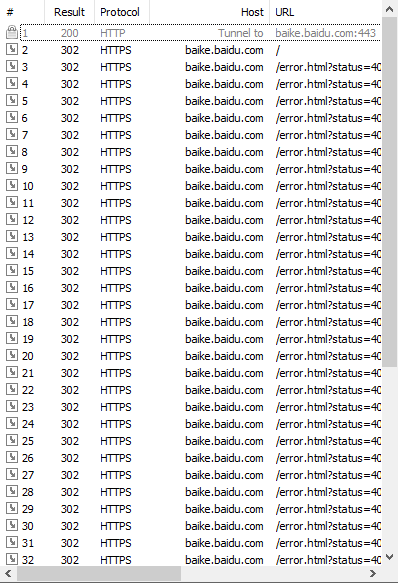
# #requests带上自己浏览器信息的请求头 import requests headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} h=requests.get('https://baike.baidu.com', allow_redirects=False,headers=headers,verify=False) print(h.request.headers)

所以使用requests记得一定加上请求头信息。
希望各位大神如果一不小心看完这篇文章请指出我说的不对的地方,或者哪些方面理解的还不够深刻。谢谢。
测试的时候没考虑太多,其实可以通过http://httpbin.org来查看请求响应信息更加直观方便,这个网址是专门用来测试http请求的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号