05 RDD编程
一、词频统计:
- 读文本文件生成RDD lines
- 将一行一行的文本分割成单词 words flatmap()
- 全部转换为小写 lower()
- 去掉长度小于3的单词 filter()
- 去掉停用词
- 转换成键值对 map()
- 统计词频 reduceByKey()

8.按字母顺序排序 sortBy(f)
9.按词频排序 sortByKey()

10.结果文件保存 saveAsTextFile(out_url)
11.词频结果可视化charts.WordCloud()


成功安装pyecharts
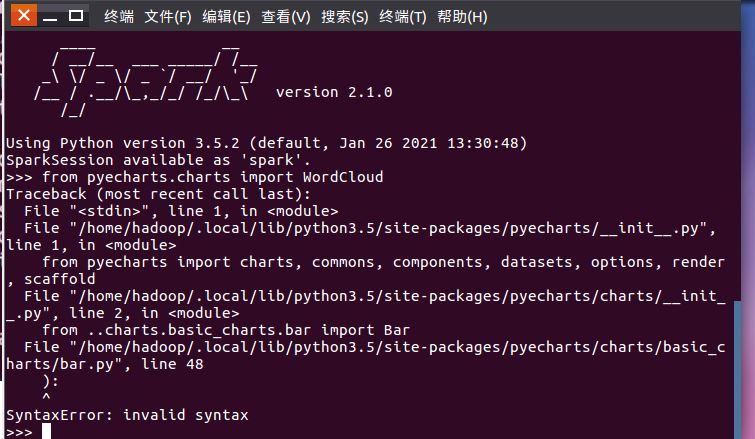
运行:from pyecharts.charts import WordCloud时报错,问题未解决
12.比较不同框架下(Python、MapReduce、Hive和Spark),实现词频统计思想与技术上的不同,各有什么优缺点.
python的优点:环境容易搭建
python的缺点:不能处理太大的数据
MapReduce的 优点:易于编程,有良好的扩展性和高容错性,适合PB级以上海量数据的离线处理
MapReduce 的缺点:不擅长实时计算,不擅长流式计算等
hive的优点:简单容易上手,可扩展,提供统一的元数据管理,延展性
hive的缺点:hive的HQL表达能力有限,hive的效率比较低,hive可控性差
Spark的优点:Spark可以直接对HDFS进行数据读写,支持YARN等部署模式,spark计算处理数据速度快
Spark的缺点:稳定性差,不能支持复杂的SQL统计
二、学生课程分数案例
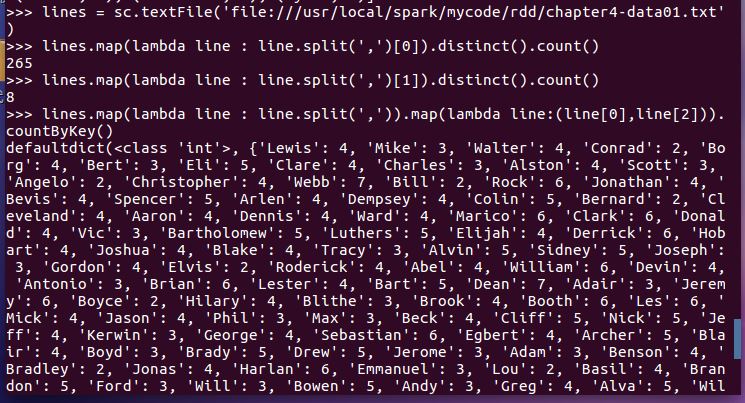
- 总共有多少学生?map(), distinct(), count()
- 开设了多少门课程?
- 每个学生选修了多少门课?map(), countByKey()
- 每门课程有多少个学生选?map(), countByValue()
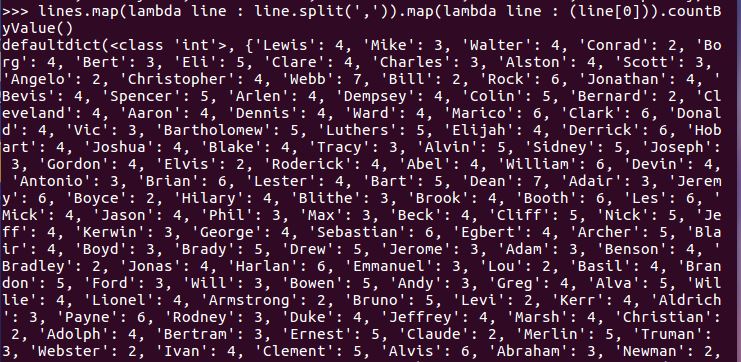
- Webb选修了几门课?每门课多少分?filter(), map() RDD
- Webb选修了几门课?每门课多少分?map(),lookup() list
- Webb的成绩按分数大小排序。filter(), map(), sortBy()

- Webb的平均分。map(),lookup(),mean()
完成此次操作需要导入numpy库,执行如下操作:
sudo apt-get update
sudo apt-get install python-numpy
出现报错:

解决方案:输入以下代码后即可成功安装numpy库
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
回到spark,执行import numpy as np时依然报错

检查后发现是因为使用的python的问题,输入下列代码后就解决了:
sudo apt-get install python3-numpy
最终效果:

- 生成(课程,分数)RDD,观察keys(),values()

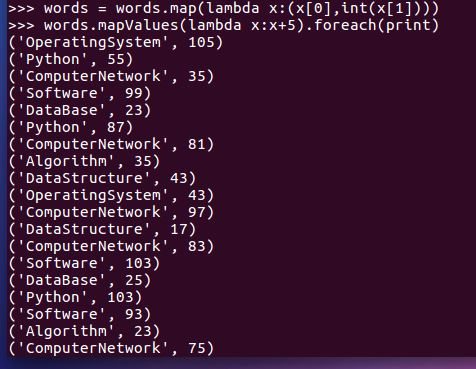
- 每个分数+5分。mapValues(func)
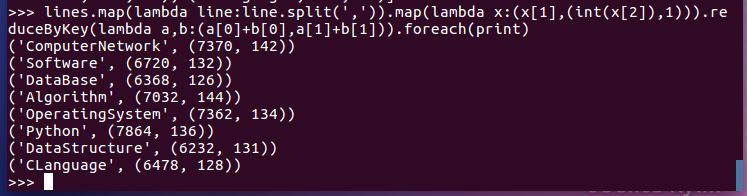
- 求每门课的选修人数及所有人的总分。combineByKey()

- 求每门课的选修人数及平均分,精确到2位小数。map(),round()

- 求每门课的选修人数及平均分。用reduceByKey()实现,并比较与combineByKey()的异同。