OpenClaw Agent与Skill架构详解
1. 概述
1.1 为什么需要 OpenClaw
我们在日常使用AI过程中,会感觉到构建一个Agent 系统面临着一系列现有框架难以解决的问题:
(1)多渠道消息统一处理的痛点
真实场景中,用户可能通过多种渠道与 AI Agent 交互。现有框架要么只支持 HTTP API 调用,要么需要为每个渠道从零开始写集成代码。OpenClaw内建了十余种渠道支持,并通过插件机制(extensions/)允许扩展更多渠道(如飞书、Matrix、Microsoft Teams 等)。
(2)长时运行 Agent 的挑战
多数 Agent 框架假设"一次请求、一次响应"的交互模式。但生产环境中的 Agent 需要:
- 在后台持续运行(Gateway 模式),接收来自多个渠道的消息
- 管理跨多轮对话的会话状态
- 处理 LLM 提供商的各种故障(限流、过载、认证失效)并自动恢复
- 支持多个 API Key 轮换以规避单点故障
(3)灵活的知识扩展需求
Agent 需要在不修改核心代码的前提下,动态获取特定领域的操作指南。例如,同一个 Agent 面对"帮我创建 GitHub PR"和"帮我查今天的天气"需要截然不同的操作知识。这种需求催生了 OpenClaw 的 Skill 机制。
1.2 OpenClaw 与其他架构的区别
| 传统 Chatbot 框架 | LangChain / LlamaIndex | AutoGPT / AgentGPT | OpenClaw | |
| 核心定位 | 意图匹配 + 模板回复 | LLM 编排链/索引 | 自主目标分解 | 生产级多渠道 Agent 平台 |
| 运行模式 | 请求-响应 | 请求-响应 / 链式调用 | 自主循环 | Gateway 常驻 + 多 session 并发 |
| 渠道支持 | 通常单一渠道 | 无内建渠道 | Web UI | 10+ 内建渠道 + 插件扩展 |
| 知识扩展 | 硬编码意图 | RAG / 工具注册 | 插件市场 | Skill(SKILL.md)按需加载 |
| 容错能力 | 基本重试 | 有限 | 有限 | 多层容错(Auth 轮换 + 模型回退 + 上下文压缩 + 智能重试) |
| 并行执行 | 不支持 | 有限支持 | 有限支持 | 原生子 Agent 并行 + 推送式结果返回 |
| 成本控制 | — | Token 追踪 | 有限 | Skill 按需加载 + 子 Agent 模型可配 |
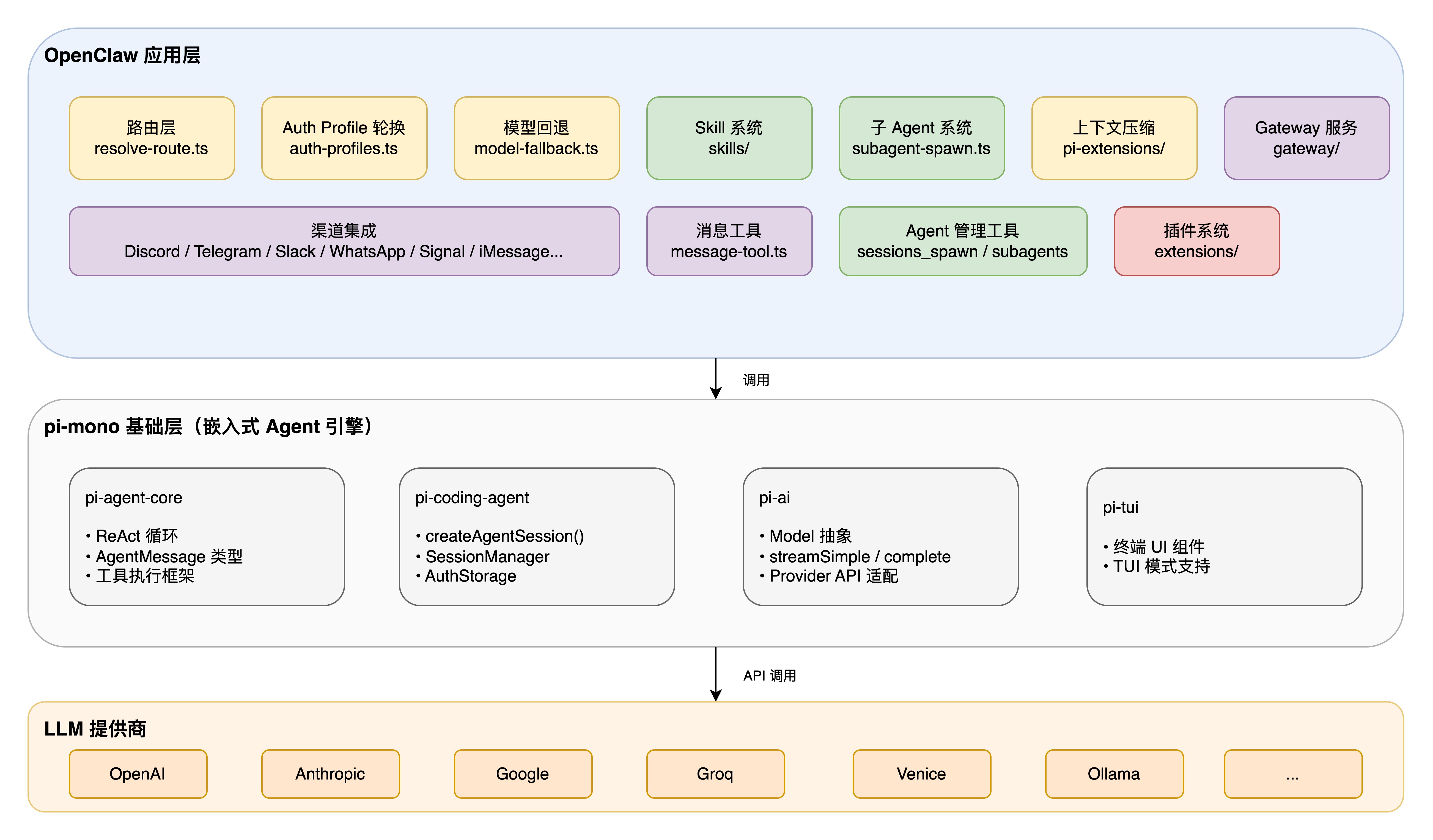
OpenClaw 的差异化定位体现在三个层面:
1. 基础设施层:基于 pi-mono(嵌入式 Agent 引擎),提供 ReAct 循环、LLM 调用、工具执行等底层能力
2. 平台层:在 pi-mono 之上构建路由、容错、认证管理、Skill 系统等生产级能力
3. 渠道层:统一消息抽象,让同一个 Agent 可以同时服务于多个通信平台
1.3 Agent 与 Skill 的设计理念
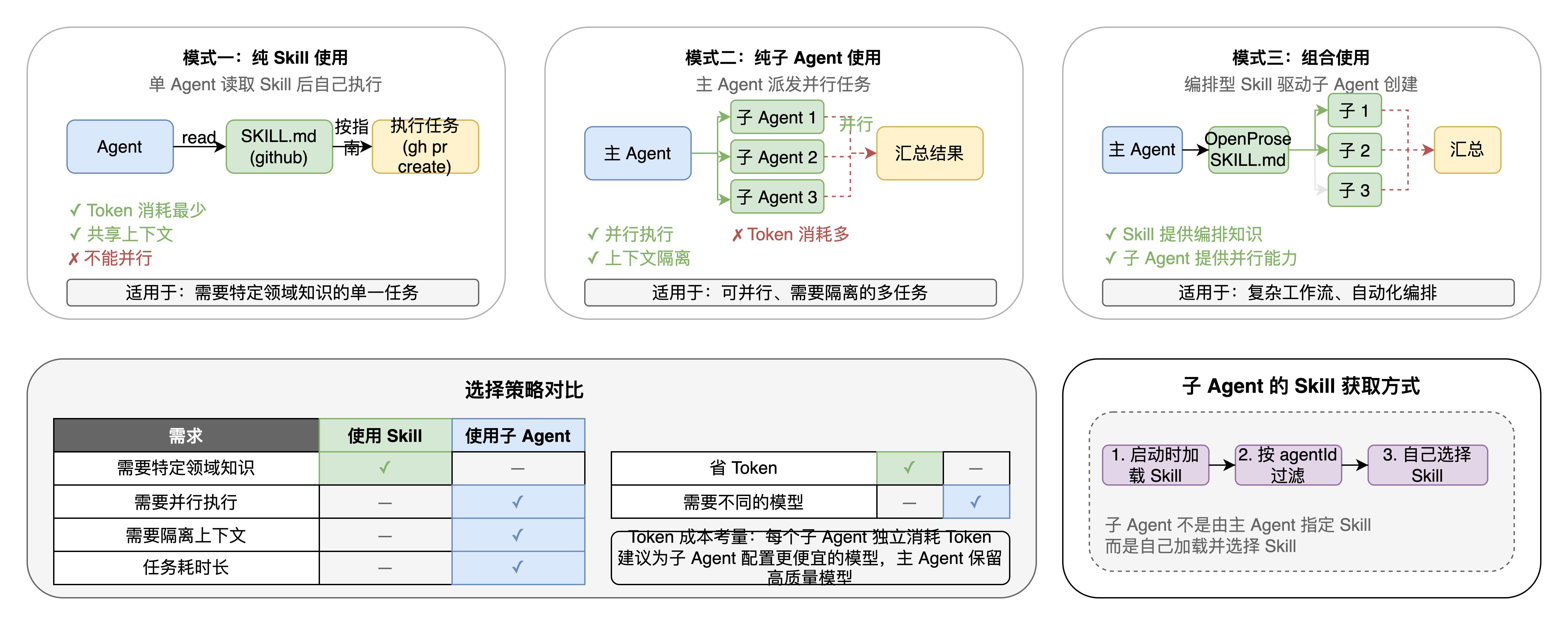
OpenClaw 中*同时存在两种互补的架构模式:
- Agent + Skill 架构:通过 SKILL.md 文件为 Agent 注入领域知识,就像给一个人发一本操作手册
- 主子 Agent(Subagent)架构:通过创建独立子 Agent 实现并行执行和上下文隔离,就像派出多个助手分头干活
两者不是替代关系,而是互补关系。一个 Agent 可以在读取 Skill 获得知识后,再创建多个子 Agent 并行执行任务;子 Agent 自身也可以使用 Skill。
| 维度 | Skill | 子 Agent |
|---|---|---|
| 本质 | 知识文档(SKILL.md) | 独立进程/会话 |
| 执行方式 | 注入到当前 Agent 的上下文 | 独立 session 运行 |
| 状态 | 共享父 session 状态 | 完全独立的 session 状态 |
| 并发 | 不能并行(只是知识) | 可以并行 |
| Token 消耗 | 共享当前 session | 独立消耗 |
| 通信方式 | 通过共享上下文 | 完成后 announce 回父 Agent |
2. Agent 核心架构
2.1 Agent 执行引擎
OpenClaw 的 Agent 执行引擎是整个系统的核心,负责从接收用户请求到返回 Agent 响应的完整流程。
2.1.1 入口与编排
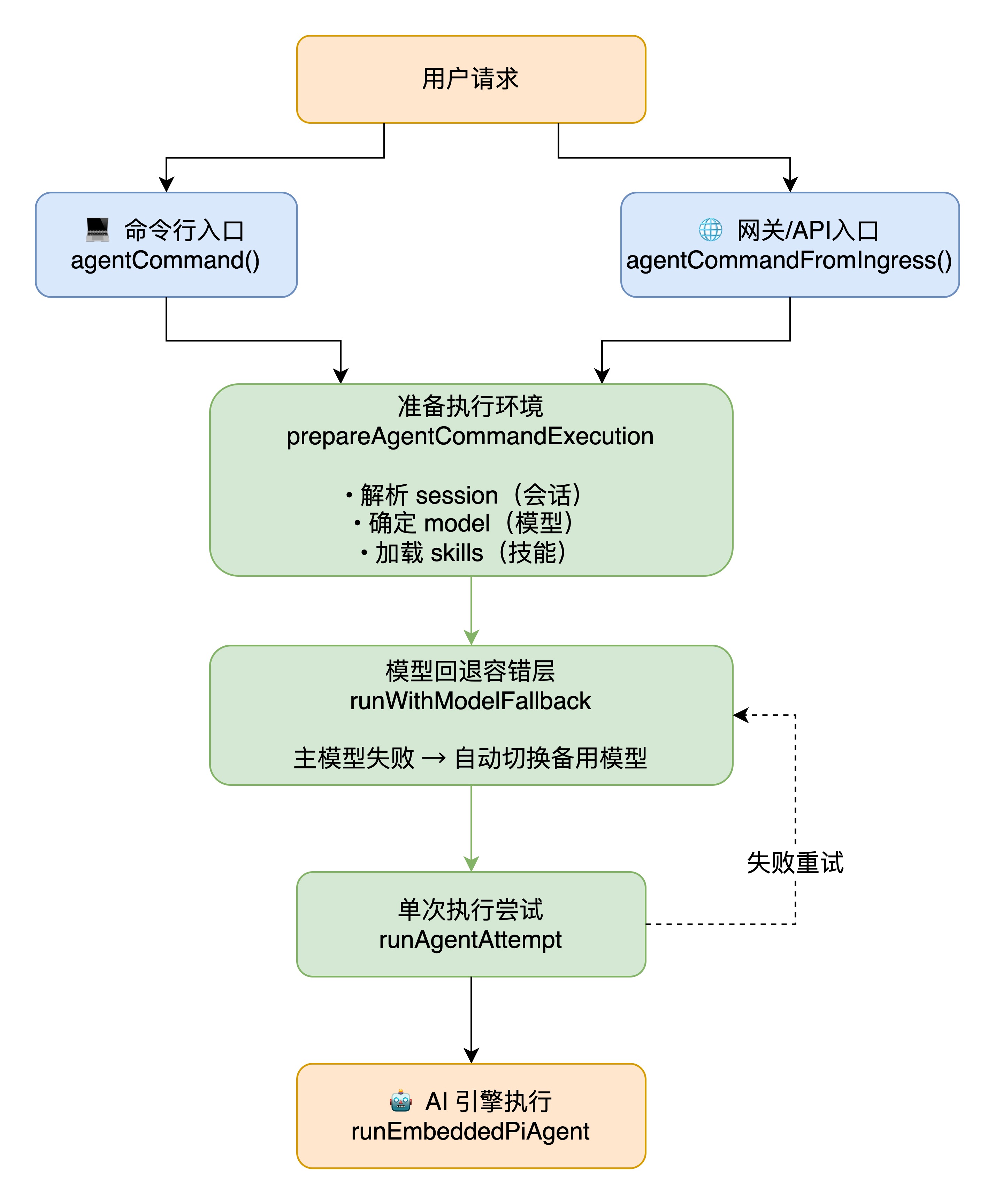
就像去银行办业务:
2. 准备工作
3. 容错保护层
4. 真正干活
一句话总结: 不管你从哪进来,都走同一条路,而且有"备胎机制"保证服务不中断。
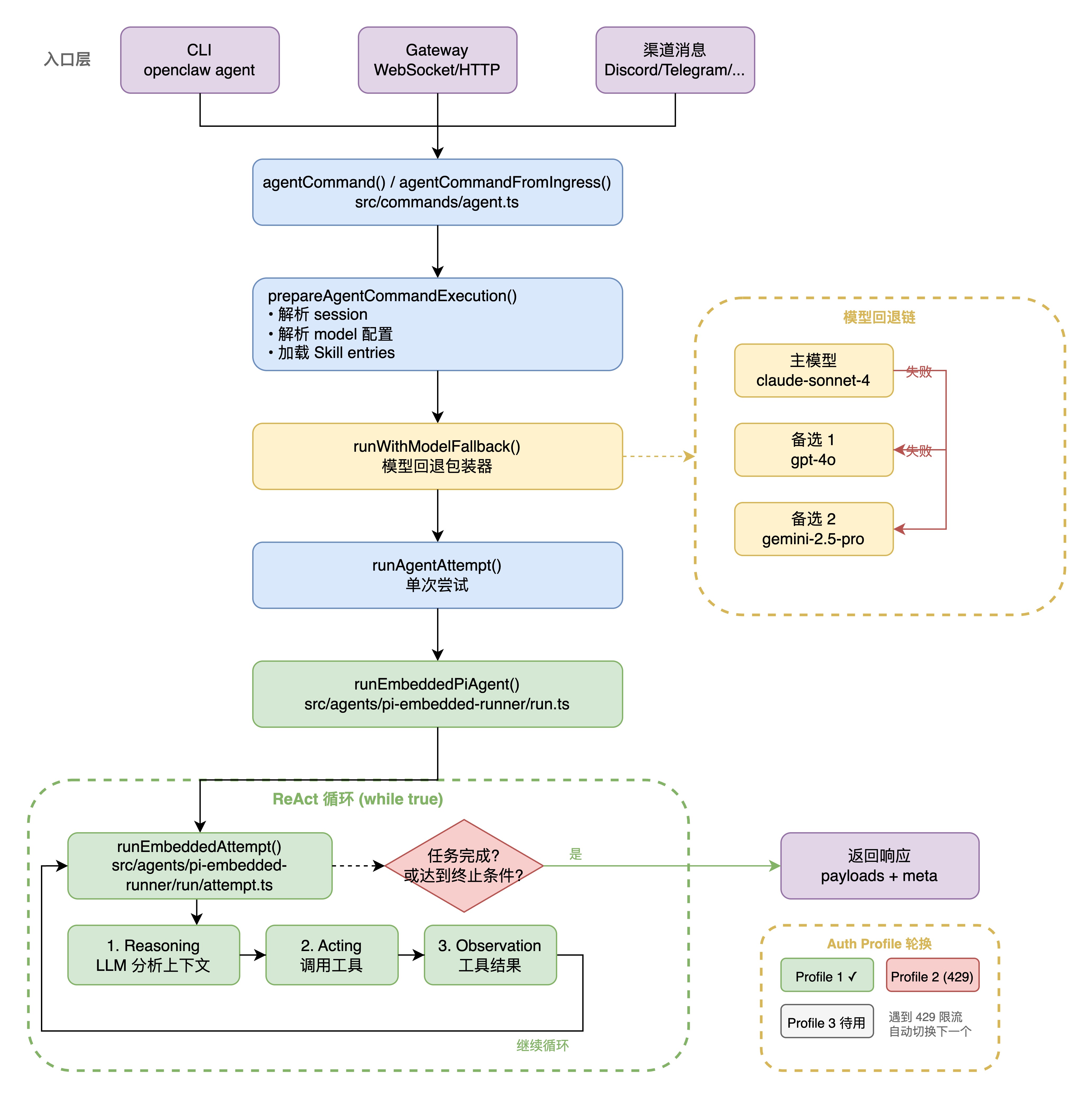
2.1.2 ReAct 循环
Agent 的核心执行逻辑在 src/agents/pi-embedded-runner/run.ts中实现。这是一个基于 ReAct范式的循环:
1. Reasoning:LLM 分析当前上下文,决定下一步行动
2. Acting:调用工具执行具体操作
3. Observation:将工具结果反馈给 LLM
4. 重复直到任务完成或达到终止条件
外层运行循环通过 MAX_RUN_LOOP_ITERATIONS控制最大迭代次数,该值根据可用的 Auth Profile 数量动态缩放。这意味着配置了更多 API Key 的系统拥有更大的重试空间,充分利用多 Profile 轮换的优势。
2.1.3 单次执行尝试
1. 准备 workspace 目录
2. 加载 Skill entries(复用 snapshot 或重新加载)
3. 构建 System Prompt(注入 Skill 菜单、工具说明、身份信息)
4. 创建工具集(文件操作、命令执行、消息发送、子 Agent 管理等)
5. 调用 pi-coding-agent 完成一次 LLM 对话
6. 处理工具调用结果、流式输出、上下文压缩等
2.2 Agent 配置与作用域
每个 Agent 的 workspace 目录决定了它能访问哪些文件、加载哪些 Skill,形成天然的权限边界。注销、消息通知主agent等功能是 subagents steer(重定向子 Agent)和 subagents kill(终止子 Agent)操作的底层支撑。
从用户请求进入(CLI/Gateway/HTTP)、经过路由匹配、模型解析、ReAct 循环执行、工具调用、到最终响应返回的完整调用链。包含 runWithModelFallback`的回退逻辑和 runEmbeddedAttempt的内部步骤。
3. Skill 机制详解
3.1 Skill 是什么
Skill 是以SKILL.md文件形式存在的知识/指令包,告诉 Agent "如何做某类事情"。它不是可执行代码,而是一份结构化的操作指南。
项目中内置约 50+ 个 Skill,涵盖开发工具、知识管理、通信平台等多个领域。
3.2 Skill 的加载机制
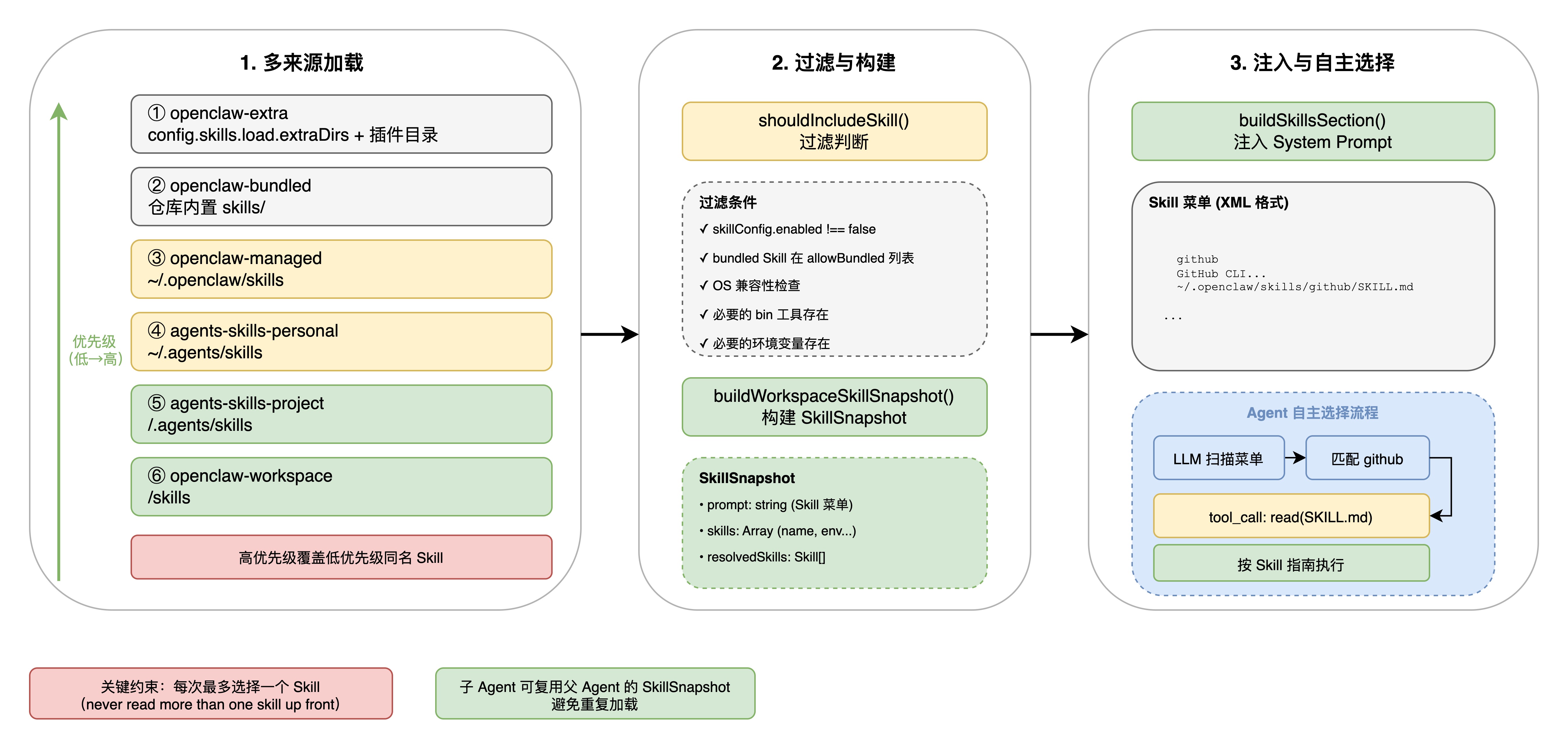
3.2.1 多源加载
Skill 的加载由 src/agents/skills/workspace.ts中的 loadSkillEntries()负责,它从6 个来源按优先级合并:
| 优先级(低→高) | 来源 | 目录 | 说明 |
|---|---|---|---|
| 1 | openclaw-extra |
config.skills.load.extraDirs + 插件目录 |
额外配置目录 + 插件 Skill |
| 2 | openclaw-bundled |
仓库内置 skills/ |
OpenClaw 自带的 Skill |
| 3 | openclaw-managed |
~/.openclaw/skills |
用户通过 openclaw skills install 安装的 Skill |
| 4 | agents-skills-personal |
~/.agents/skills |
个人级别的 Agent Skill |
| 5 | agents-skills-project |
<workspace>/.agents/skills |
项目级别的 Agent Skill |
| 6 | openclaw-workspace |
<workspace>/skills |
工作区本地 Skill |
高优先级来源会覆盖低优先级的同名 Skill。例如,项目级的github Skill 会覆盖内置的 github Skill。
3.2.2 内置 Skill 目录解析
src/agents/skills/bundled-dir.ts负责定位内置 Skill 目录,按以下顺序查找:
1. 环境变量 `OPENCLAW_BUNDLED_SKILLS_DIR`(优先级最高)
2. 可执行文件同级的 `skills/` 目录(适用于 `bun --compile` 构建)
3. 从包根目录向上查找包含 SKILL.md 的 `skills` 目录
3.2.3 插件 Skill
src/agents/skills/plugin-skills.ts从已启用的插件中收集 Skill 目录。每个插件通过 openclaw.plugin.json的 skills字段声明自己提供的 Skill 路径。安全检查确保路径必须在插件根目录内。
3.2.4 过滤与资格判断
并非所有加载的 Skill 都会出现在 Agent 的可用列表中。`src/agents/skills/config.ts` 中的 `shouldIncludeSkill()` 执行多层过滤:
1. 配置禁用:skillConfig.enabled === false→ 排除
2. 内置白名单:bundled Skill 需在 allowBundled列表中
3. 运行时资格:检查 OS 兼容性、必要的二进制工具、必要的环境变量等
3.2.5 数量限制
src/config/types.skills.ts中定义了 Skill 的各种限制参数:
SkillsLimitsConfig = {
maxCandidatesPerRoot?: number; // 每个来源目录的最大候选数
maxSkillsLoadedPerSource?: number; // 每个来源的最大加载数
maxSkillsInPrompt?: number; // Prompt 中的最大 Skill 数
maxSkillsPromptChars?: number; // Prompt 中 Skill 段的最大字符数
maxSkillFileBytes?: number; // 单个 SKILL.md 文件的最大字节数
}
3.3 Skill 选择与执行
菜单注入(System Prompt):
所有符合条件的 Skill 的摘要信息会被注入到 Agent 的 System Prompt 中,而非完整内容。src/agents/system-prompt.ts中的 buildSkillsSection()负责这个过程。
注入到 Prompt 中的 Skill 菜单包含name、description、location,不包含 SKILL.md 的完整内容,有效控制了 Token 消耗。
Agent 自主选择机制:
Skill 的选择是 Agent(LLM)自主完成的,不是系统硬编码的规则匹配。整个过程是正常的多轮对话:
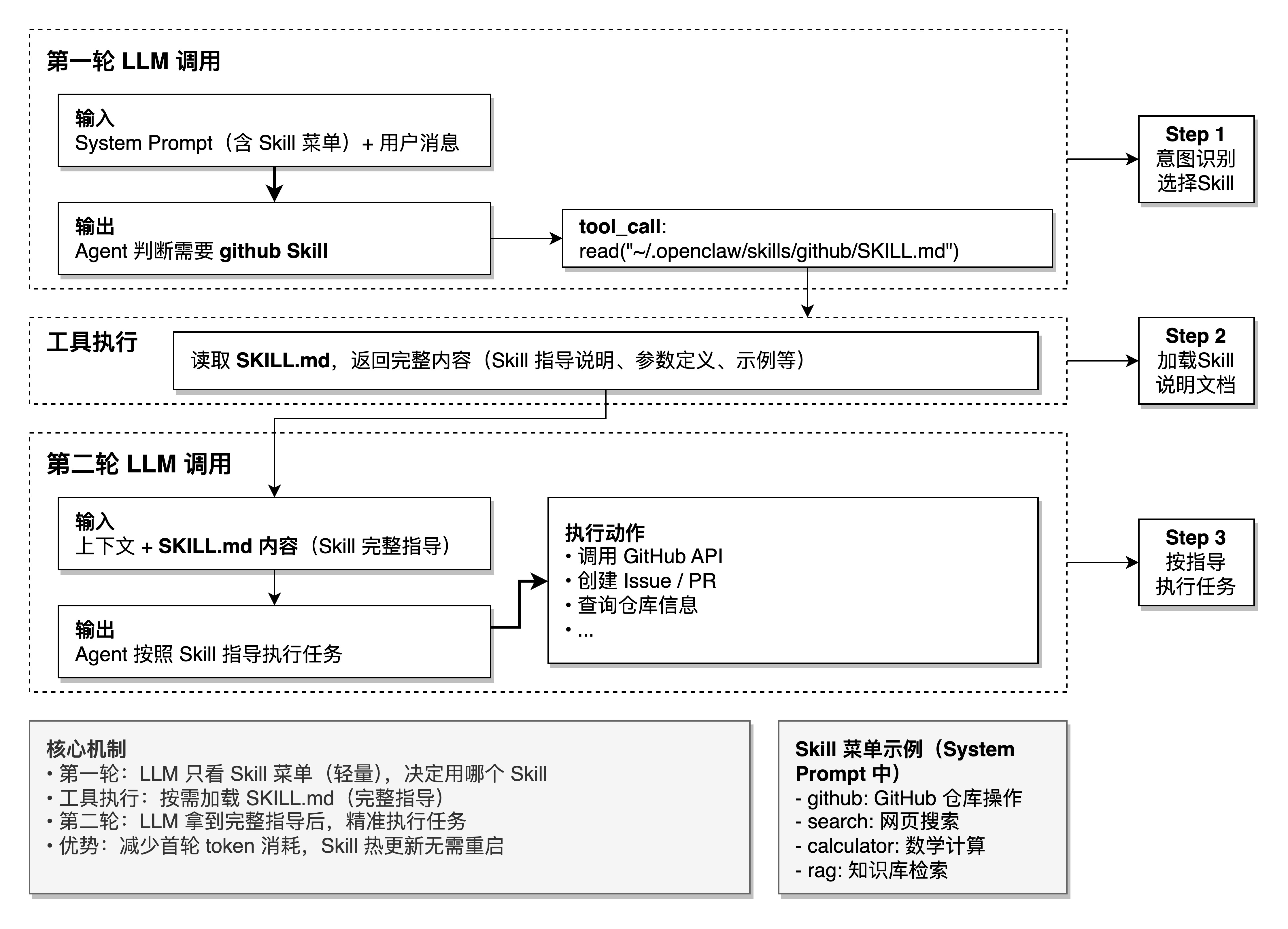
关键约束:never read more than one skill up front——每次最多选择一个 Skill,避免不必要的 Token 消耗。
buildWorkspaceSkillSnapshot()将 Skill 加载结果封装为 SkillSnapshot:
SkillSnapshot = {
prompt: string; // 生成的 Skill 菜单 Prompt
skills: Array<{
name: string;
primaryEnv?: string; // 主要环境变量
requiredEnv?: string[]; // 必需的环境变量
}>;
skillFilter?: string[]; // Agent 级别的过滤规则
resolvedSkills?: Skill[]; // 已解析的 Skill 对象
version?: number; // 快照版本号
};
子 Agent 启动时可以复用父 Agent 的 `SkillSnapshot`,避免重复加载。src/agents/pi-embedded-runner/skills-runtime.ts 中的判断逻辑很清晰。
4. 主子 Agent(Subagent)架构
4.1 子 Agent 的设计动机
在以下场景中,单个 Agent 处理所有任务并不高效:
| 场景 | 问题 | 子 Agent 方案 |
|---|---|---|
| 并行任务 | 串行执行耗时过长 | 创建多个子 Agent 并行处理 |
| 长时间任务 | 阻塞主 Agent 响应 | 子 Agent 后台执行,主 Agent 继续服务 |
| 上下文隔离 | 不同任务互相污染上下文 | 每个子 Agent 有独立 session |
| 资源密集型 | 大规模搜索/代码分析消耗大量 Token | 子 Agent 可使用更便宜的模型 |
创建子 Agent 是主 Agent 主动决定的,不是系统自动触发。Agent(LLM)根据任务复杂度自行判断是否需要创建子 Agent。
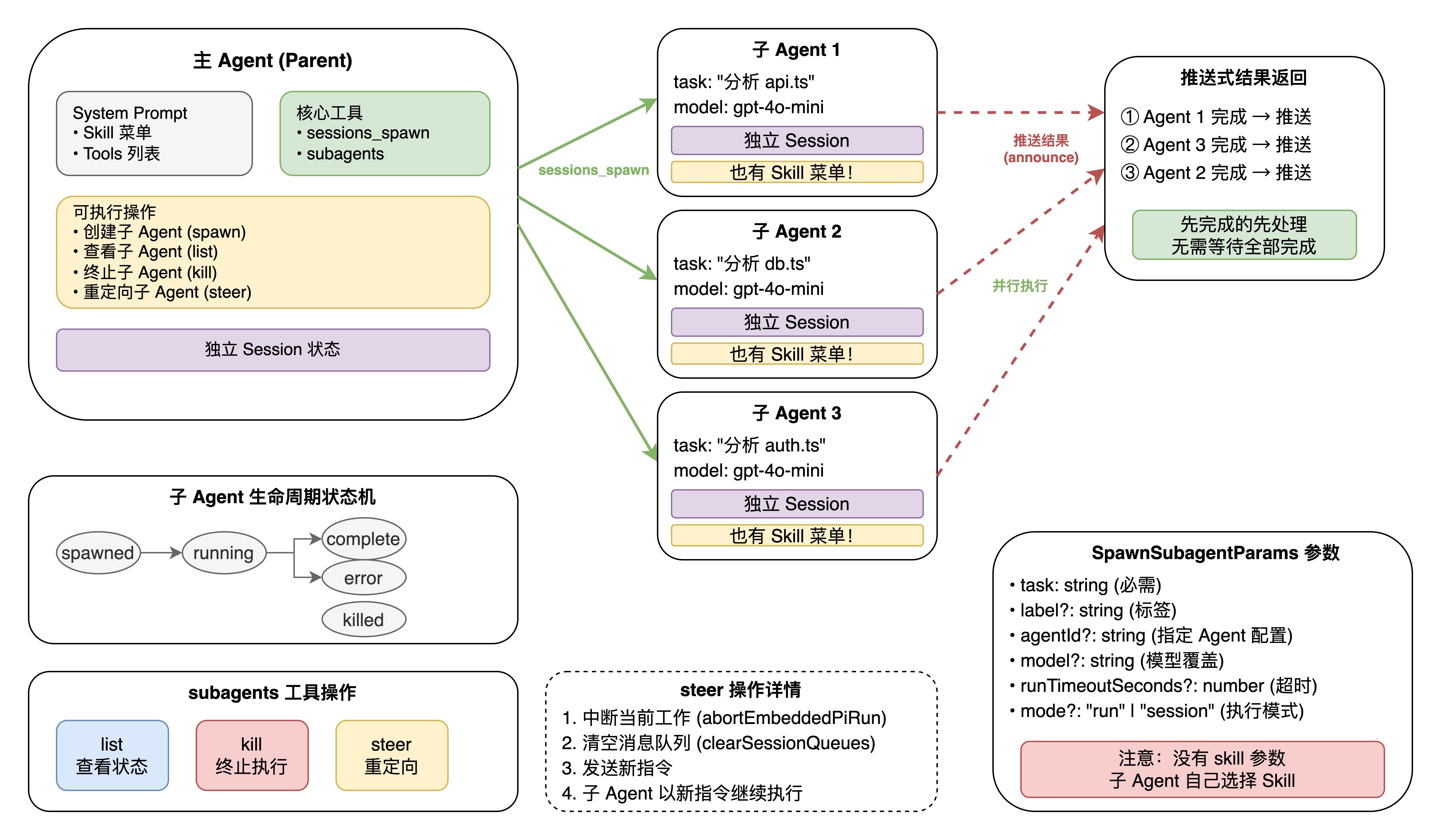
4.2 子 Agent 创建机制
sessions_spawn工具:
子 Agent 通过 sessions_spawn工具创建(定义在 src/agents/tools/sessions-spawn-tool.ts):
SpawnSubagentParams 参数:
SpawnSubagentParams = {
task: string; // 必需:任务描述
label?: string; // 可选:标签(用于识别)
agentId?: string; // 可选:指定使用哪个 Agent 配置
model?: string; // 可选:模型覆盖
thinking?: string; // 可选:思考级别
runTimeoutSeconds?: number; // 可选:超时时间
thread?: boolean; // 可选:绑定到消息线程
mode?: "run" | "session"; // 可选:一次性执行 or 持久会话
cleanup?: "delete" | "keep"; // 可选:结束后清理策略
sandbox?: "inherit" | "require"; // 可选:沙箱模式
expectsCompletionMessage?: boolean; // 可选:是否期望完成消息
attachments?: Array<{...}>; // 可选:附件
};
注意这里没有skill或 skillFilter 参数—子 Agent 的 Skill 选择是自主的。
创建模式:
- mode: run(默认):一次性执行,完成任务后自动结束。适合明确的单次任务。
- mode: "session:创建持久会话,可以多次交互。适合需要迭代的复杂任务。
创建流程:
spawnSubagentDirect() 的核心流程:
1. 校验参数:验证 agentId 格式、thread/mode 兼容性、sandbox 权限
2. 深度检查:检查 spawnDepth 是否超过 maxSpawnDepth,防止无限递归
3. 子 Agent 数量检查:检查 maxChildren 限制
4. 创建 child session:生成唯一的 childSessionKey
5. 注册运行:通过 registerSubagentRun 记录到注册表
6. 异步执行:调用 Gateway 的 agent 方法启动子 Agent
7. 触发 Hook:发出 subagent_spawned 事件
4.3 子 Agent 生命周期
状态追踪:
src/agents/subagent-registry.ts 维护所有子 Agent 的运行记录,核心数据结构为 subagentRuns: Map<string, SubagentRunRecord>。它提供了丰富的查询和管理 API:
- registerSubagentRun(params):注册新的子 Agent
- listSubagentRunsForRequester(sessionKey):列出某个父 Agent 的所有子 Agent
- countActiveRunsForSession(sessionKey):统计活跃子 Agent 数量
- markSubagentRunTerminated(runId, reason):标记终止
- releaseSubagentRun(childSessionKey):释放资源
注册表还具备持久化能力:子 Agent 记录会保存到磁盘,系统重启后通过 restoreSubagentRunsFromDisk() 恢复未完成的工作。
生命周期事件:
子 Agent 的生命周期通过以下事件(`src/agents/subagent-lifecycle-events.ts`)来表示:
export const SUBAGENT_ENDED_REASON_COMPLETE = "subagent-complete"; // 正常完成
export const SUBAGENT_ENDED_REASON_ERROR = "subagent-error"; // 执行出错
export const SUBAGENT_ENDED_REASON_KILLED = "subagent-killed"; // 被主动终止
export const SUBAGENT_ENDED_REASON_SESSION_RESET = "session-reset"; // session 被重置
export const SUBAGENT_ENDED_REASON_SESSION_DELETE = "session-delete"; // session 被删除
这些事件会被转化为结果回传给父 Agent。
推送式结果返回:
OpenClaw 采用逐个推送而非统一返回的方式处理子 Agent 结果。runSubagentAnnounceFlow()负责这个过程:
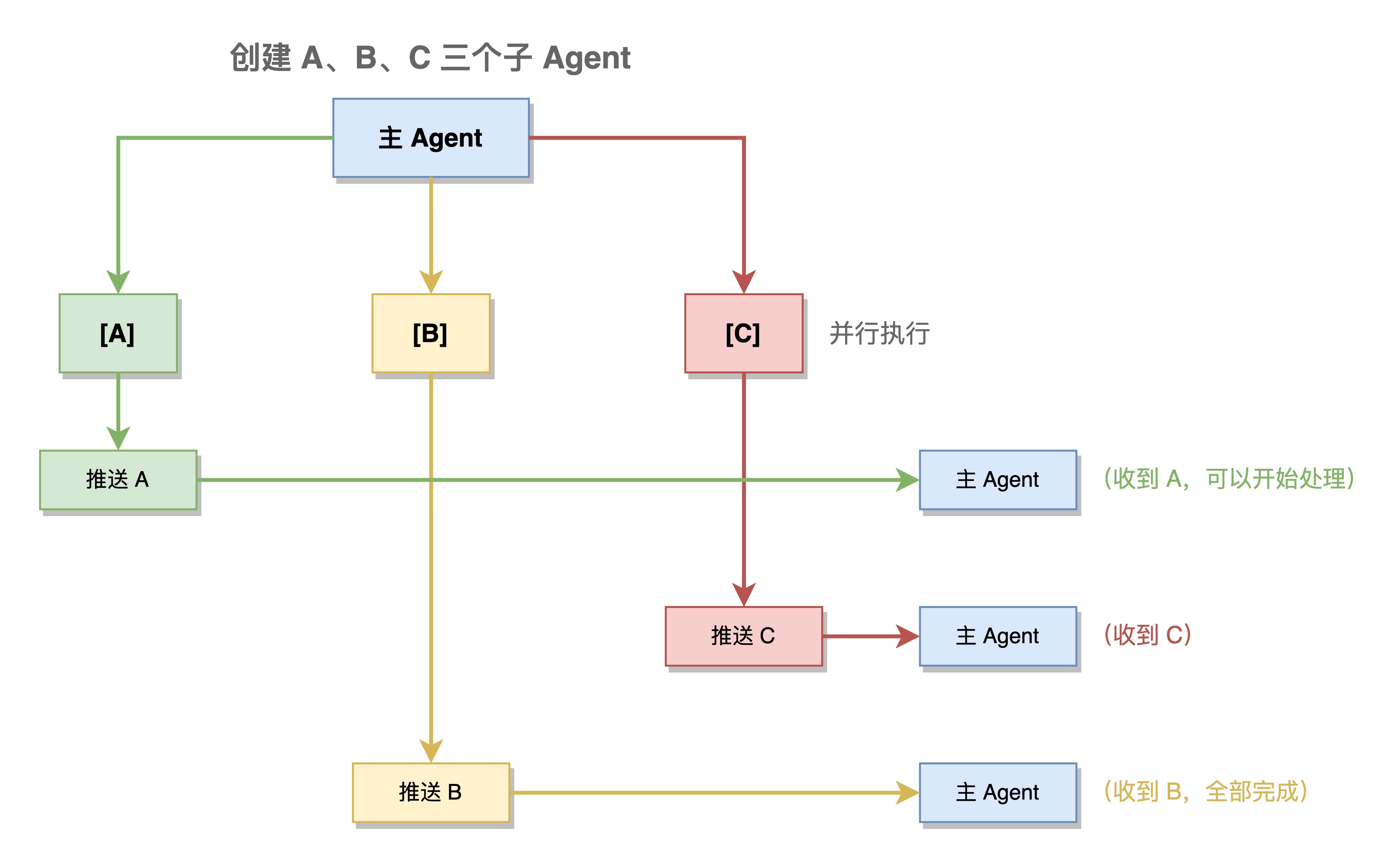
推送式返回的优势:
1. 提前处理:无需等待所有子 Agent 完成,先完成的先处理
2. 提前终止:发现答案后可以 kill 其余子 Agent,节省资源
3. 渐进式反馈:用户可以看到逐步的进度
4. 部分失败处理:某个子 Agent 失败时可以立即补救,不影响其他
5. 精细超时:每个子 Agent 独立超时,互不影响
4.4 主 Agent 对子 Agent 的管理
主 Agent 通过 subagents 工具管理子 Agent:
list:查看状态:
列出所有活跃和近期完成的子 Agent,包括运行状态、标签、模型等信息。
kill:终止执行:
- target=具体标签/ID:终止指定子 Agent
- targe tall或 target="*":终止所有子 Agent
steer:重定向(核心容错机制,个人认为是灵魂)
当子 Agent 方向偏离或卡住时,主 Agent 可以通过 steer 重新指挥:
Steer 的执行步骤:
1. 中断当前工作:调用 abortEmbeddedPiRun() 中止子 Agent 当前执行
2. 清空队列:清除子 Agent 的待处理消息队列
3. 等待停止:确认子 Agent 已完全停止
4. 发送新指令:向子 Agent 注入新的任务描述
5. 重新开始:子 Agent 以新指令继续执行
> **图 4**:主子 Agent 通信架构图
5. Skill 与子 Agent 的协作
5.1 两者的互补关系
Skill 和子 Agent 在 OpenClaw 架构中扮演不同但互补的角色:
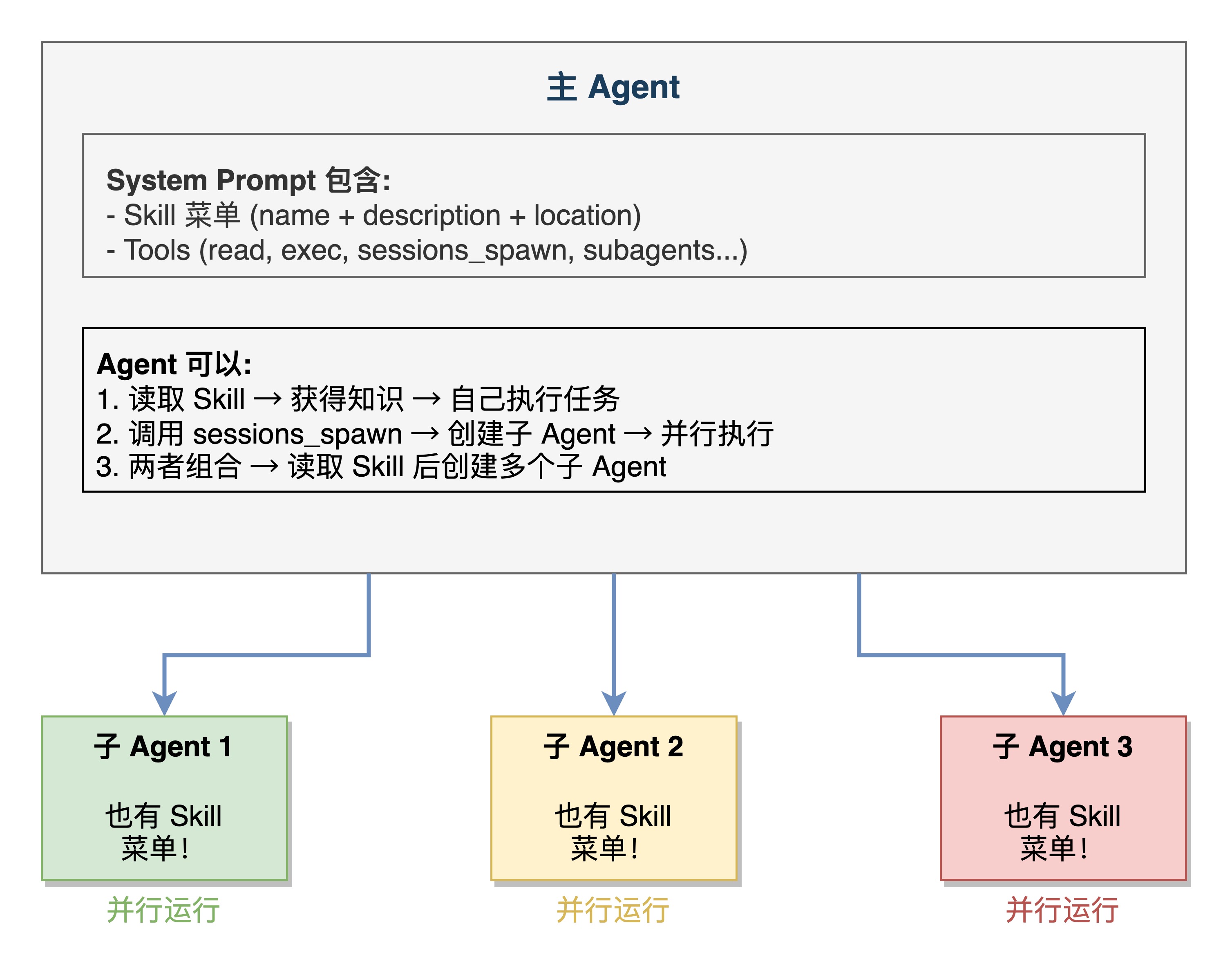
5.2 子 Agent 的 Skill 获取
子 Agent 不是由主 Agent 指定 Skill,而是自己加载并选择 Skill:
1. 子 Agent 启动时,根据自己的 workspace 加载所有 Skill
2. 根据 `agentId` 对应的 `skills` 配置过滤
3. 生成自己的 Skill 菜单注入到 System Prompt
4. 自行决定使用哪个 Skill
通过配置可以限制不同 Agent 的 Skill 范围:
{
agents: {
list: [
{
id: "research-bot",
skills: ["web-research", "summarize"] // 只允许这两个 Skill
},
{
id: "code-bot",
skills: ["github", "coding-agent"] // 只允许这两个 Skill
}
]
}
}
5.3 组合使用场景
编排型 Skill:
某些 Skill(如 OpenProse)本身会指导 Agent 创建子 Agent:
用户: prose run my-workflow.prose
↓
主 Agent 扫描 Skill 菜单 → 匹配到 OpenProse Skill
↓
主 Agent 读取 OpenProse SKILL.md → 获得 workflow 编排指南
↓
OpenProse Skill 指导 Agent 创建多个子 Agent 执行 workflow
↓
子 Agent 1: 执行 step-1 子 Agent 2: 执行 step-2在 OpenClaw 项目约 50+ 个 Skill 中,绝大多数(50+ 个)是纯知识型的,编排型 Skill 是特例。
5.4 选择策略指南
| 需求 | 使用 Skill | 使用子 Agent |
|---|---|---|
| 需要特定领域知识 | ✅ | — |
| 需要并行执行 | — | ✅ |
| 需要隔离上下文 | — | ✅ |
| 任务耗时长 | — | ✅ |
| 省 Token | ✅ | — |
| 需要不同的模型 | — | ✅ |
Token 成本考量:每个子 Agent 都有独立的上下文和 Token 消耗。对于重复性或密集型任务,建议为子 Agent 配置更便宜的模型,主 Agent 保留高质量模型。
6. 容错与可靠性机制
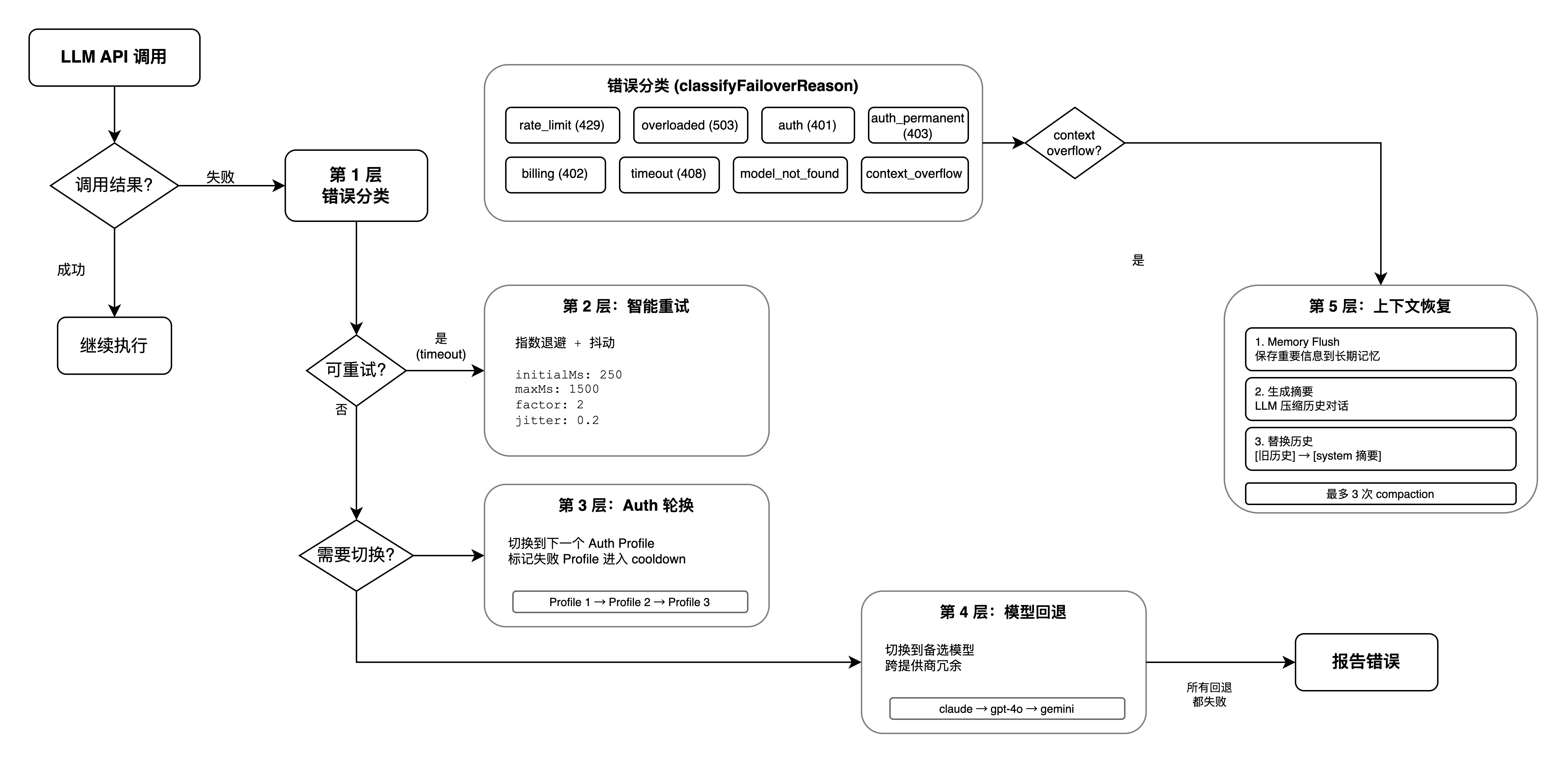
OpenClaw 在 pi-mono 基础引擎之上构建了多层容错机制,确保 Agent 在面对各种故障时能够自动恢复。
6.1 错误分类与识别
系统首先将来自 20+ LLM 提供商的不同错误格式统一标准化为以下类型:
| 错误类型 | HTTP 状态码 | 触发条件 | 后续处理 |
|---|---|---|---|
rate_limit |
429 | 触发限流 | 切换 Auth Profile + 退避 |
overloaded |
503 | 模型过载 | 退避 + 切换模型 |
auth |
401 | 认证失败 | 切换 Auth Profile |
auth_permanent |
403 | 永久认证错误 | 标记 Profile 禁用 |
billing |
402 | 账单问题 | 切换 Auth Profile |
timeout |
408 | 超时 | 重试(不标记 cooldown) |
model_not_found |
404 | 模型不存在 | 切换到备选模型 |
session_expired |
410 | 会话过期 | 重新创建会话 |
context_overflow |
— | 上下文超限 | 触发 compaction |
这套分类机制将临时故障(可重试)和永久故障(需要切换或人工干预)清晰地区分开来,为后续各层容错策略提供决策依据。
6.2 认证熔断器
OpenClaw 支持配置多个 API Key / Auth Profile,通过熔断器模式管理其健康状态:
- 健康追踪:记录每个 Profile 的成功/失败历史
- 自动轮换:当前 Profile 失败时(如 429 限流),自动切换到下一个
- 熔断保护:对已知失败的 Profile 暂停请求,防止重复失败
- 渐进恢复:通过探测机制检测 Profile 是否恢复正常
run.ts 中的 advanceAuthProfile() 是轮换的核心逻辑,当遇到认证相关错误时切换到下一个可用 Profile。
6.3 模型回退
当主模型不可用时,系统按照配置的回退链自动切换:
主模型(如 claude-sonnet-4-20250514)
│ 失败
▼
备选模型 1(如 gpt-4o)
│ 失败
▼
备选模型 2(如 gemini-2.5-pro)
│ 失败
▼
报告错误回退链在 AgentConfig.model.fallbacks 中配置,runWithModelFallback()负责执行。回退是跨提供商的——可以从 Anthropic 回退到 OpenAI 再到 Google,实现多提供商冗余。
6.4 上下文恢复
当对话历史过长导致上下文窗口溢出时,系统自动执行压缩:

系统最多尝试 3 次 compaction,如果仍然溢出,还会尝试截断工具结果。
6.5 智能重试策略
对临时性故障使用指数退避 + 抖动策略,避免"惊群效应":
const OVERLOAD_FAILOVER_BACKOFF_POLICY: BackoffPolicy = {
initialMs: 250, // 初始延迟 250ms
maxMs: 1_500, // 最大延迟 1.5s
factor: 2, // 指数因子(250 → 500 → 1000 → 1500)
jitter: 0.2, // 20% 随机抖动,分散请求
};
const DEFAULT_RETRY_CONFIG = {
attempts: 3, // 最多 3 次
minDelayMs: 300, // 最小延迟 300ms
maxDelayMs: 30_000, // 最大延迟 30s
jitter: 0, // 默认无抖动
};
不同错误类型采取不同策略:
| 错误类型 | 重试? | 退避策略 | 说明 |
|---|---|---|---|
rate_limit |
✅ | 指数退避 | 等待后重试,可能切换 Profile |
overloaded |
✅ | 指数退避 + 抖动 | 避免惊群效应 |
timeout |
✅ | 立即重试 | 不标记 cooldown |
auth |
❌ | — | 切换 Profile,不重试当前 |
billing |
❌ | — | 切换 Profile,不重试当前 |
context_overflow |
❌ | — | 触发 compaction,不重试 |
6.6 容错层级总结
整个容错体系形成五层防御:
第 1 层:错误分类 → 统一识别错误类型
第 2 层:智能重试 → 临时故障自动重试
第 3 层:Auth 轮换 → API Key 级别的故障转移
第 4 层:模型回退 → 模型/提供商级别的故障转移
第 5 层:上下文恢复 → 上下文溢出时自动压缩
7. OpenClaw 与 pi-mono 的关系
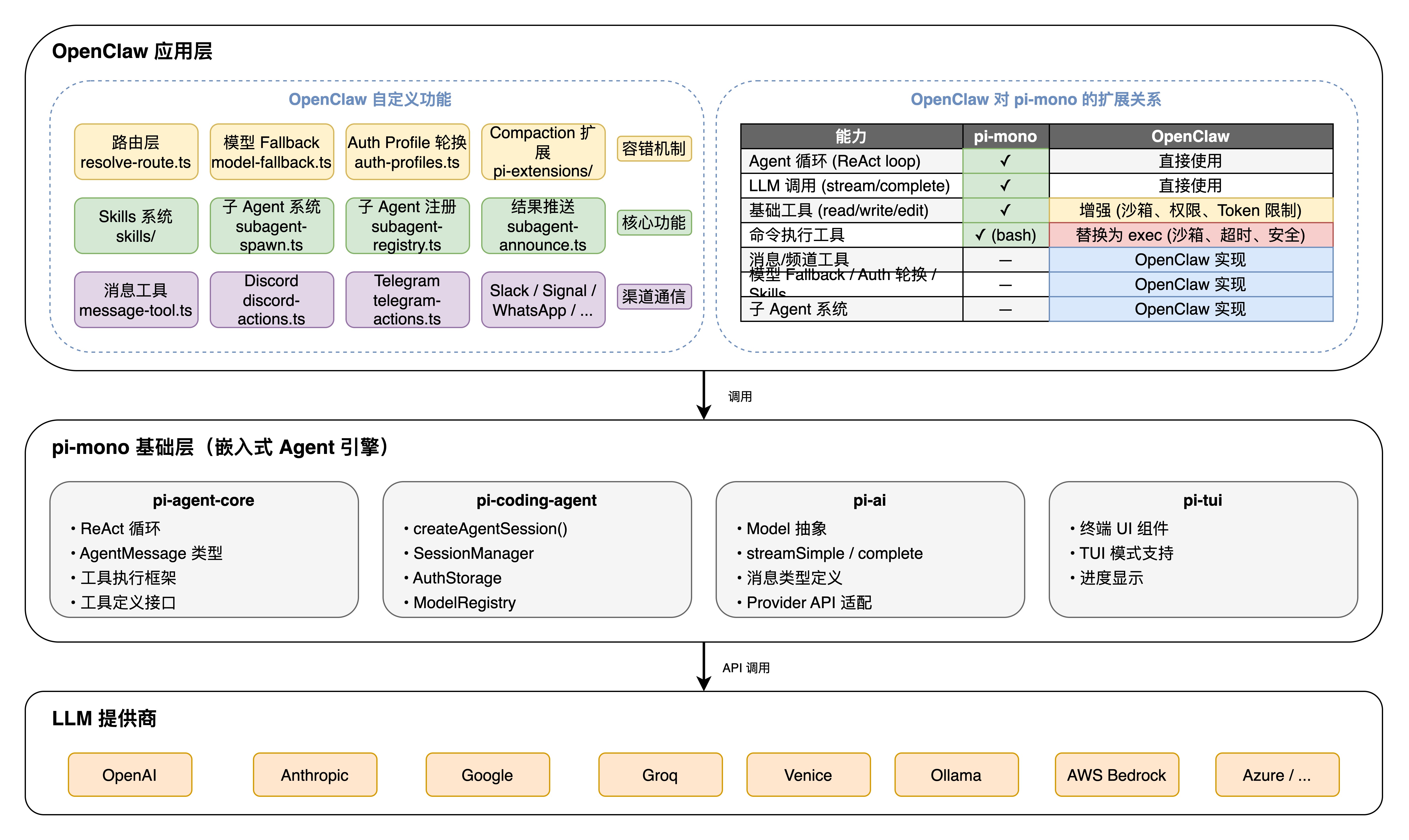
OpenClaw 并非从零构建 Agent 引擎,而是基于 pi-mono这个嵌入式 Agent 基础包进行扩展。理解两者的边界有助于把握系统的整体架构。
7.1 pi-mono 提供的基础能力
pi-mono 由多个子包组成:
| 子包 | 提供的能力 |
|---|---|
| pi-agent-core | Agent 循环(ReAct loop)、AgentMessage 类型、工具执行框架 |
| pi-coding-agent | createAgentSession()、SessionManager、AuthStorage、ModelRegistry |
| pi-ai | Model 抽象、streamSimple、complete、消息类型、Provider API 适配 |
| pi-tui | 终端 UI 组件(用于本地 TUI 模式) |
pi-mono 提供了一个功能完备的 Agent 引擎,但它主要面向单用户、单 session、请求-响应的场景。
7.2 OpenClaw 的扩展与定制
OpenClaw 在 pi-mono 之上构建了生产级的扩展层:
| 能力 | pi-mono 提供? | OpenClaw 扩展 |
|---|---|---|
| Agent 循环(ReAct loop) | ✅ | 直接使用 |
| LLM 调用(stream/complete) | ✅ | 直接使用 |
| 工具执行框架 | ✅ | 直接使用 |
| 会话管理 | ✅ | 自定义扩展(多 session 并发) |
| 基础工具(read/write/edit) | ✅ | 增强(沙箱、权限控制、Token 限制) |
| 命令执行工具 | ✅(bash) | 替换为 exec(增加沙箱、超时、安全控制) |
| 消息工具 | ❌ | OpenClaw 实现 |
| 频道工具 | ❌ | OpenClaw 实现(Discord/Telegram/Slack…) |
| 路由层 | ❌ | OpenClaw 实现 |
| 模型 Fallback | ❌ | OpenClaw 实现 |
| Auth Profile 轮换 | ❌ | OpenClaw 实现 |
| Skills 系统 | ❌ | OpenClaw 实现 |
| 子 Agent 系统 | ❌ | OpenClaw 实现 |
| Context Compaction 扩展 | ❌ | OpenClaw 实现 |
7.3 架构分层
pi-mono 提供单用户、单 session、请求-响应模式的 Agent 引擎,OpenClaw 在其上构建多用户、多 session、多渠道的生产级扩展。
8. 工具系统
8.1 核心工具分类
OpenClaw Agent 的工具分为四大类:
(1)文件工具(来自 pi-mono,被 OpenClaw 增强)
| 工具 | 作用 | OpenClaw 增强 |
|---|---|---|
read |
读取文件 | 沙箱限制、图片检测、Token 限制 |
write |
写入文件 | 沙箱限制、workspace 范围限制 |
edit |
编辑文件 | 沙箱限制、workspace 范围限制 |
(2)命令执行工具(OpenClaw 替换 pi-mono 的 bash)
| 工具 | 作用 | 说明 |
|---|---|---|
exec |
执行 shell 命令 | 替代 pi-mono 的 bash,增加沙箱、超时、安全控制 |
process |
管理后台进程 | 查看/终止后台任务 |
apply_patch |
应用代码补丁 | 仅 OpenAI Codex 模型可用 |
(3)消息与频道工具(OpenClaw 独有)
使 Agent 能够与外部通信平台交互,是 OpenClaw 多渠道能力的具体体现。
(4)Agent 管理工具(OpenClaw 独有)
| 工具 | 作用 |
|---|---|
sessions_spawn |
创建子 Agent |
subagents |
管理子 Agent(list/kill/steer) |
sessions_list |
列出会话 |
sessions_history |
查看会话历史 |
8.2 工具权限策略
src/agents/pi-tools.policy.ts 定义了子 Agent 的工具权限策略,通过两级拒绝列表实现:
所有子 Agent 始终禁止的工具
const SUBAGENT_TOOL_DENY_ALWAYS = [
"gateway", "agents_list", "whatsapp_login", "session_status",
"cron", "memory_search", "memory_get", "sessions_send",
];
叶子节点子 Agent(最深层)额外禁止的工具
const SUBAGENT_TOOL_DENY_LEAF = [
"subagents", "sessions_list", "sessions_history", "sessions_spawn",
];
叶子节点判断:当子 Agent 的 spawnDepth >= maxSpawnDepth 时,被视为叶子节点,不能再创建自己的子 Agent,从而防止无限递归。
非叶子节点的子 Agent 保留 sessions_spawn 和 subagents 工具,支持多级子 Agent 嵌套。
8.3 自定义工具扩展
插件(extensions/)可以通过 openclaw.plugin.json 注册自定义工具。工具定义遵循统一接口:
type AnyAgentTool = {
label: string; // 显示标签
name: string; // 工具名称(唯一标识)
description: string; // 功能描述(注入 Prompt)
parameters: TSchema; // 参数 Schema
execute: (toolCallId: string, args: unknown) => Promise<ToolResult>;
};
> **图 8**:工具系统架构图
> 文件:`diagrams/08-tool-system.drawio`
> 说明:展示工具的四大分类、pi-mono 工具 vs OpenClaw 增强/替换/新增工具、子 Agent 工具权限策略(DENY_ALWAYS + DENY_LEAF)、以及插件工具的注册流程。
9. 常见问题
Q1: Skill 选择需要额外调用 LLM 吗?
不需要额外调用。Skill 选择是 Agent 在正常多轮对话的第一轮中完成的——Agent 扫描 Skill 菜单,调用 `read` 工具读取 SKILL.md,这只是普通的工具调用。
Q2: Skill 能并行执行吗?
不能。Skill 是知识文档,不是执行单位。如果需要并行执行,应创建多个子 Agent,每个子 Agent 可以各自使用 Skill。
Q3: 子 Agent 的 Skill 是谁指定的?
子 Agent 自己决定。主 Agent 通过 `sessions_spawn` 只传递 `task`(任务描述),子 Agent 启动后自行加载和选择 Skill。可以通过 `agents.list[].skills` 配置限制某个 Agent 可用的 Skill 范围。
Q4: 子 Agent 之间能互相通信吗?
不能直接通信。子 Agent 的结果通过 announce 机制推送给父 Agent,由父 Agent 做信息中转。这种设计保持了架构的简洁性和可预测性。
Q5: 子 Agent 报错后怎么办?
父 Agent 会收到错误通知(`subagent-error` 事件),可以通过 `subagents` 工具进行补救:`kill` 终止后重新 spawn,或使用 `steer` 发送新指令让子 Agent 换个方向继续。
Q6: 系统支持多少层子 Agent 嵌套?
由 `maxSpawnDepth` 配置决定(默认值在 `DEFAULT_SUBAGENT_MAX_SPAWN_DEPTH`)。达到最大深度的子 Agent 成为叶子节点,不能再创建子 Agent。
10 总结
上周看的整体openclaw源码,分析架构,主要是我想升级JoyApex,所以在升级过程中,想看下openclaw架构有何神奇之处。看完Agent和记忆模块之后,感觉写的真好。上面有很多细节,可能大家感觉太多了,但是都是我在真实改造过程中遇到的问题,以及给其他人讲解过程中,其他人提出的疑问(非常感谢其他人的疑问和耐心倾听),所以很详细。感觉Agent架构确实在不断升级,如果从开始接触Agent一路走来的人,更能感觉出这套架构的灵魂和带来的眼前一亮,希望能给大家带来帮助,有不对的地方欢迎指导。最后祝大家早安、午安、晚安。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号