【AI新范式】两条路线,一个答案:来自测开视角的实战手记
一、脑海中的两个声音
作为一名测试开发工程师,除了日场的业务需求测试,自己还承担了一些测试工具平台的开发维护工作。
在这个AI技术飞速发展的时代,我常常在想两个问题:
如果我具备代码能力,开发这个平台能让AI做什么?
如果我代码能力有限,该怎么结合AI完成这个平台?
这两个问题一直萦绕在我脑海。直到最近,一个需求的出现,让我有机会同时回答这两个问题——用两种完全不同的视角,去审视同一段开发旅程。
二、机会这不就来了
2.1 需求背景
保单指挥中心平台是一个面向保险业务全生命周期管理的统一数据查询平台。该平台通过整合互联网、商家险、延保、履约理赔、计费、供应链等多条业务线的数据,为业务人员提供基于保单维度的统一视图和快速检索能力。平台一期上线后,我们紧接着需要迭代一个重要需求:
记录所有用户的查询操作,支持数据追踪和性能监控
听起来简单,但细想下来,问题不少:
2.2 两种视角的起点
在正式开始之前,我将会用两种不同的视角来审视这个需求:
视角A:具备代码能力
"我知道AOP可以实现切面拦截,异步处理可以避免阻塞主流程,设计模式要遵循单一职责...具体怎么落地,提供我的想法,让AI来帮我完成。"
视角B:代码能力有限
"我不太懂AOP是什么,异步线程池怎么配置,甚至不确定这个需求该用什么技术方案...但我知道要解决什么问题。"
无论哪种视角,最终的目标都是一样的:交付一个可用的、可扩展的查询记录功能。两种视角的路径,注定不同。
三、同样的终点,不同的路
3.1 当你具备代码能力时
3.1.1 你是架构师,AI是执行者
作为一名熟练的测试开发,我对代码并不陌生。我知道要做什么,但我更想知道:AI能帮我做到什么程度?
于是我尝试了一个大胆的方式:
我只提供平台架构和需求背景,代码和技术方案全交给AI。
我的输入:
【项目背景】
保单指挥中心平台 - 保险业务全生命周期管理的统一数据查询平台
技术架构:前后端分离
前端:Vue 技术栈
后端:DongBoot 框架,双服务架构
【服务架构】
| 服务 | 定位 | 核心职责 |
|------|------|----------|
| 服务A (API Gateway Service) | 网关层 | 前端接口统一入口、请求参数校验与转换、响应数据格式化、统一异常处理、API文档管理 |
| 服务B (Business Service) | 业务层 | 业务逻辑编排、多业务线数据聚合、外部接口调用管理、业务规则执行、业务异常处理 |
【需求描述】
实现查询轨迹记录功能,需满足以下要求:
1. 记录内容
用户 ERP
查询类型
请求 URI
请求参数
响应数据
耗时
2. 技术约束
异步处理,不影响主业务性能
保证数据完整性
3. 决策要求
请先决策日志记录应该在哪一层进行(服务A/服务B/两层结合),说明决策依据及优缺点分析,经我确认后再完成技术方案设计。
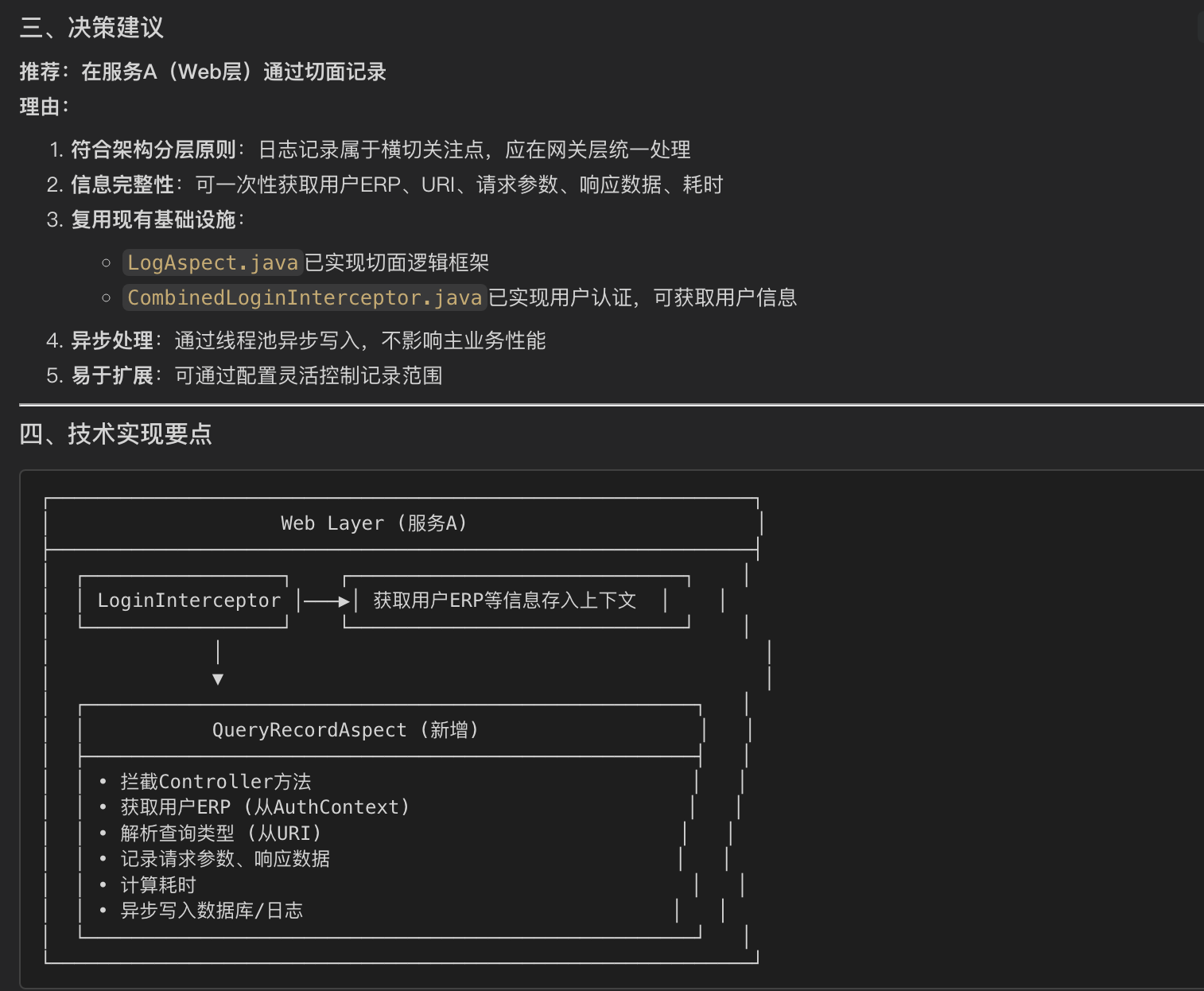
明确在哪一层实现后,之后在项目A中,完成技术方案设计,并根据技术方案微调后的结果由AI全自主生成代码。
3.1.2 你的价值在哪里?
既然AI能生成方案,那我的价值是什么?
判断力和决策力。
当AI给出方案后,我需要判断:
比如,AI最初生成的方案中,客户端IP获取只考虑了X-Forwarded-For头,我要求补充X-Real-IP和Proxy-Client-IP的处理。
这就是具备代码能力的优势:你能看懂AI的输出,能发现问题,能引导改进。
3.2 当你代码能力有限时
3.2.1 你是产品经理,AI是技术顾问
如果换一个视角呢?假设我对AOP、线程池这些概念比较模糊,我会怎么做?
我会把问题翻译成业务语言,让AI帮我找技术方案。
我的输入:
【项目背景】
保单指挥中心平台 - 保险业务全生命周期管理的统一数据查询平台
技术架构:前后端分离
前端:Vue 技术栈
后端:DongBoot 框架,双服务架构
【服务角色说明】
| 服务 | 角色 | 想象成 |
|------|------|--------|
| 服务A (API Gateway Service) | 前台接待 | 像公司前台,负责接待客户、登记信息、转交请求 |
| 服务B (Business Service) | 业务专员 | 像业务部门,负责处理具体业务、查询数据、给出结果 |
【业务需求】我
们需要一个**"查询留痕"功能**,就像银行的柜台业务记录仪:
每次用户查询时,自动记录:
谁查的(用户ERP)
查什么(查询类型)
从哪查的(请求URI)
查了什么条件(请求参数)
查到什么结果(响应数据)
查了多久(耗时)
【核心诉求】
不影响客户体验 - 记录过程不能让用户感觉变慢
就像银行办业务时,监控录像在后台自动录制,不会让客户等待
记录不能丢 - 数据要可靠保存
就像监控录像不能因为断电就丢失
不知道在哪记录 - 请帮我判断应该在前台记录,还是在业务部门记录,或者两边配合?
【请帮我分析】
请用通俗易懂的语言告诉我:
应该在哪个服务实现这个记录功能?
为什么选择这里?
各个方案的优缺点是什么?
等确认后,再给出具体的技术实现方案。请避免使用太多技术术语,用业务场景来类比说明。AI的输出:


发现没有,在这种思路下,AI开始"教学"了!它在解释技术概念,在选择方案,在帮你理清思路。
3.2.2 你的价值在哪里?
需求翻译和验收判断。
虽然你不太懂技术细节,但你清楚地知道:
比如,你可能会问AI:
"如果记录失败了,会影响用户查询吗?" "响应数据特别大怎么办?" "数据要保存多久?"
这些问题,来自于你对业务的熟悉,而不是对技术的熟悉。
3.3 两种路径的交汇
无论哪种视角,最终都指向了同一个结果:
人负责定义问题和验收结果,AI负责寻找方案和执行实现。
区别只在于:
四、AI出手了
4.1 架构设计:AI的思路
基于需求背景和工程架构,AI给出的技术方案如下:
┌─────────────────────────────────────────────────────────────┐
│ 前端层 (Vue) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 保单查询 │ │ 理赔查询 │ │ 签约查询 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────┬───────────────────────────────────┘
│ HTTP/HTTPS
┌─────────────────────────▼───────────────────────────────────┐
│ 服务A (网关层) │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ QueryRecordAspect │ │
│ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │
│ │ │ 请求拦截 │ │ 响应记录 │ │ 异常处理 │ │ │
│ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │
│ └─────────────────────────┬───────────────────────────┘ │
└───────────────────────────┼─────────────────────────────────┘
│ @RecordQuery
┌───────────────────────────▼─────────────────────────────────┐
│ QueryRecordService │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 参数转换 │ │ 异步保存 │ │ 错误处理 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└───────────────────────────┬─────────────────────────────────┘
│ MyBatis
┌───────────────────────────▼─────────────────────────────────┐
│ 数据库 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ query_record 表 │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 用户ERP │ │ 查询类型 │ │ 请求URI │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 响应数据 │ │ 耗时(ms) │ │ 查询状态 │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
这个设计的核心思路:
4.2 代码实现:AI的输出
4.2.1 表结构设计与实体类定义
@Data
public class QueryRecordDO {
//具体的字段
}4.2.2 注解定义
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RecordQuery {
QueryType queryType(); // 查询类型
boolean async() default true; // 是否异步
boolean recordResponse() default true; // 是否记录响应
int maxResponseLength() default 10000; // 响应数据最大长度
}4.2.3 切面实现
@Aspect
@Component
@Order(2)
public class QueryRecordAspect {
@Autowired
private QueryRecordService queryRecordService;
@Around("@annotation(com.jd...RecordQuery)")
public Object recordQuery(ProceedingJoinPoint joinPoint) throws Throwable {
// 获取注解配置
RecordQuery recordQuery = signature.getMethod().getAnnotation(RecordQuery.class);
// 创建记录对象
QueryRecordBO queryRecordBO = createQueryRecordBO(joinPoint, recordQuery, request);
long startTime = System.currentTimeMillis();
try {
// 执行目标方法
result = joinPoint.proceed();
// 记录成功信息
queryRecordBO.setQueryStatus("SUCCESS");
queryRecordBO.setDuration(System.currentTimeMillis