缓存之美:万文详解 Caffeine 实现原理(上)
文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪共享问题、MPSC 多线程设计模式、高性能缓存的设计思想和多线程间的协调方案等等,文章最后会对全文内容进行总结,希望大家能有所收获的同时在未来对本地缓存选型时提供完整的理论依据。
Caffeine 缓存原理图如下:
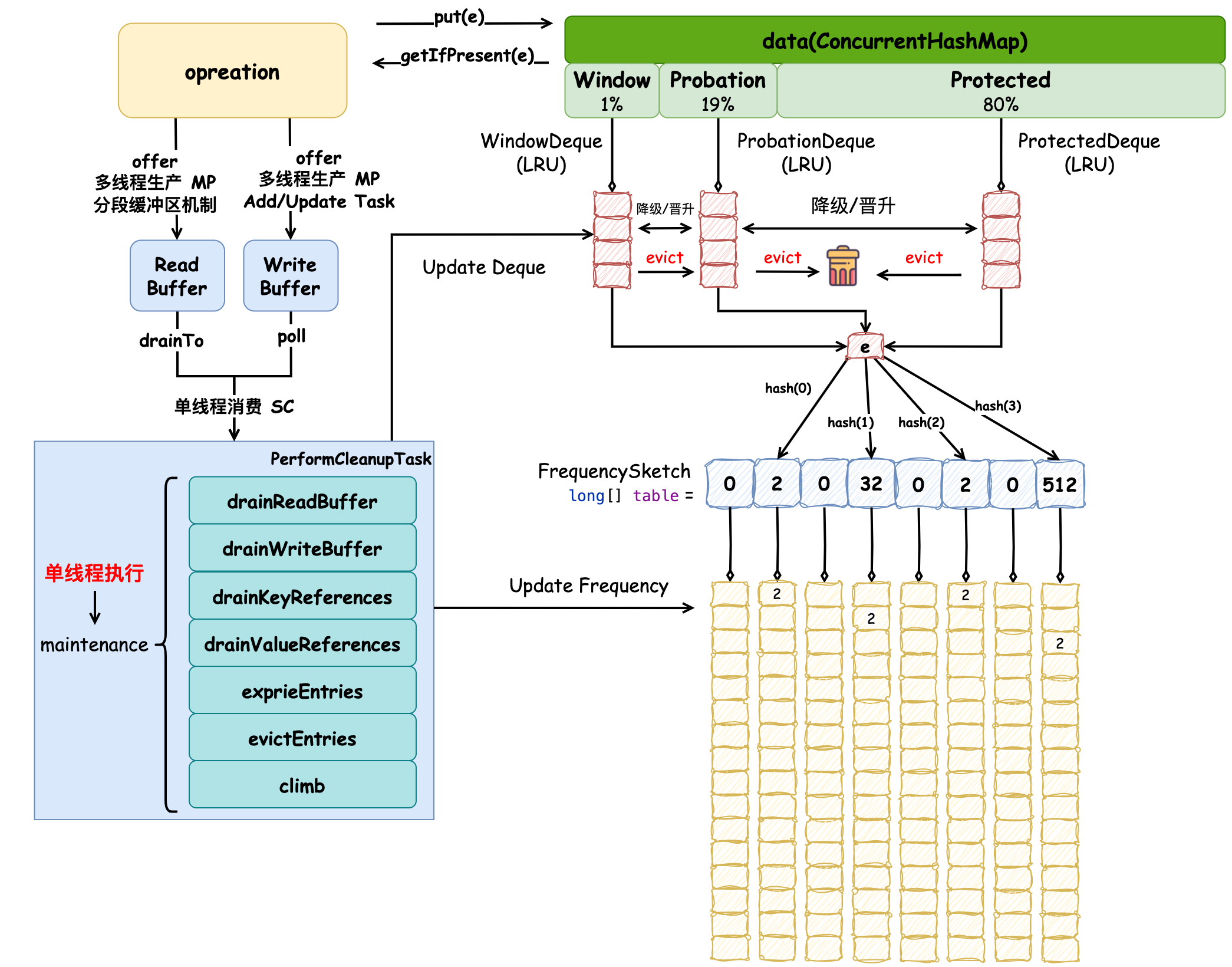
它使用 ConcurrentHashMap 保存数据,并在该数据结构的基础上创建了窗口区、试用区和保护区,用于管理元素的生命周期,各个区的数据结构是使用了 LRU 算法的双端队列,随着缓存的命中率变化,窗口区和保护区大小会自动调节以适应当前访问模式。在对元素进行驱逐时,使用了 TinyLFU 算法,会优先将频率低的元素驱逐,访问频率使用 Count-Min Sketch 数据结构记录,它能在保证较高准确率(93.75%)的情况下占用较少内存空间。读、写操作分别会向 ReadBuffer 和 WriteBuffer 中添加“读/写后任务”,这两个缓冲区的设计均采用了 MPSC 多生产者单消费者的多线程设计模式。缓冲区中任务的消费由维护方法 maintenance 中 drainReadBuffer 和 drainWriteBuffer 实现,维护方法通过添加同步锁,保证任务只由单线程执行,这种设计参考了 WAL(Write-Ahead Logging)思想,即:先写日志,再执行操作,先把操作记录在缓冲区,然后在合适的时机异步、批量地执行缓冲区中的任务。维护方法除了这些作用外,还负责元素在各个分区的移动、频率的更新、元素的驱逐等操作。
接下来的源码分析以如下测试用例为例:先分析构造方法,了解缓存初始化过程中创建的重要数据结构和关键字段,然后再深入添加元素的方法(put),该方法相对复杂,也是 Caffeine 缓存的核心,理解了这部分内容,文章剩余的内容理解起来会非常容易,接着分析获取元素的方法(getIfPresent),最后再回到核心的维护方法 maintenance 中,这样便基本理解了 Caffeine 缓存的运行原理,需要注意的是,因为我们并未指定缓存元素的过期时间,所以与此相关的内容如时间过期策略和时间轮等内容不会专门介绍。
public class TestReadSourceCode {
@Test
public void doRead() {
// read constructor
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.build();
// read put
cache.put("key", "value");
// read get
cache.getIfPresent("key");
}
}
constructor
Caffeine 的实现类区分了 BoundedLocalManualCache 和 UnboundedLocalManualCache,见名知意它们分别为“有边界”的和“无边界”的缓存。Caffeine#isBounded 方法诠释了“边界”的含义:
public final class Caffeine<K, V> {
static final int UNSET_INT = -1;
public <K1 extends K, V1 extends V> Cache<K1, V1> build() {
// 校验参数
requireWeightWithWeigher();
requireNonLoadingCache();
@SuppressWarnings("unchecked")
Caffeine<K1, V1> self = (Caffeine<K1, V1>) this;
return isBounded()
? new BoundedLocalCache.BoundedLocalManualCache<>(self)
: new UnboundedLocalCache.UnboundedLocalManualCache<>(self);
}
boolean isBounded() {
// 指定了最大大小;指定了最大权重
return (maximumSize != UNSET_INT) || (maximumWeight != UNSET_INT)
// 指定了访问后过期策略;指定了写后过期策略
|| (expireAfterAccessNanos != UNSET_INT) || (expireAfterWriteNanos != UNSET_INT)
// 指定了自定义过期策略;指定了 key 或 value 的引用级别
|| (expiry != null) || (keyStrength != null) || (valueStrength != null);
}
}
也就是说,当为缓存指定了上述的驱逐或过期策略会定义为有边界的 BoundedLocalManualCache 缓存,它会限制缓存的大小,防止内存溢出,否则为无边界的 UnboundedLocalManualCache 类型,它没有大小限制,直到内存耗尽。我们以创建配置了固定大小的缓存为例,它对应的类型便是 BoundedLocalManualCache,在执行构造方法时,有以下逻辑:
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef
implements LocalCache<K, V> {
// ...
static class BoundedLocalManualCache<K, V> implements LocalManualCache<K, V>, Serializable {
private static final long serialVersionUID = 1;
final BoundedLocalCache<K, V> cache;
BoundedLocalManualCache(Caffeine<K, V> builder) {
this(builder, null);
}
BoundedLocalManualCache(Caffeine<K, V> builder, @Nullable CacheLoader<? super K, V> loader) {
cache = LocalCacheFactory.newBoundedLocalCache(builder, loader, /* async */ false);
}
}
}
BoundedLocalCache 为抽象类,缓存对象的实际类型都是它的子类。它在创建时使用了反射并遵循简单工厂的编码风格:
interface LocalCacheFactory {
static <K, V> BoundedLocalCache<K, V> newBoundedLocalCache(Caffeine<K, V> builder,
@Nullable AsyncCacheLoader<? super K, V> cacheLoader, boolean async) {
var className = getClassName(builder);
var factory = loadFactory(className);
try {
return factory.newInstance(builder, cacheLoader, async);
} catch (RuntimeException | Error e) {
throw e;
} catch (Throwable t) {
throw new IllegalStateException(className, t);
}
}
}
getClassName 方法非常有意思,它会根据缓存配置的属性动态拼接出实际缓存类名:
interface LocalCacheFactory {
static String getClassName(Caffeine<?, ?> builder) {
var className = new StringBuilder();
// key 是强引用或弱引用
if (builder.isStrongKeys()) {
className.append('S');
} else {
className.append('W');
}
// value 是强引用或弱引用
if (builder.isStrongValues()) {
className.append('S');
} else {
className.append('I');
}
// 配置了移除监听器
if (builder.removalListener != null) {
className.append('L');
}
// 配置了统计功能
if (builder.isRecordingStats()) {
className.append('S');
}
// 不同的驱逐策略
if (builder.evicts()) {
// 基于最大值限制,可能是最大权重W,也可能是最大容量S
className.append('M');
// 基于权重或非权重
if (builder.isWeighted()) {
className.append('W');
} else {
className.append('S');
}
}
// 配置了访问过期或可变过期策略
if (builder.expiresAfterAccess() || builder.expiresVariable()) {
className.append('A');
}
// 配置了写入过期策略
if (builder.expiresAfterWrite()) {
className.append('W');
}
// 配置了刷新策略
if (builder.refreshAfterWrite()) {
className.append('R');
}
return className.toString();
}
}
这也就是为什么能在 com.github.benmanes.caffeine.cache 包路径下能发现很多类似 SSMS 只有简称命名的类的原因(下图只截取部分,实际上有很多):

根据代码逻辑,它的命名遵循如下格式 S|W S|I [L] [S] [MW|MS] [A] [W] [R] 其中 [] 表示选填,| 表示某配置不同选择的分隔符,结合注释能清楚的了解各个位置字母简称表达的含义。如此定义实现类使用了 多级继承,尽可能多地复用代码。
以我们测试用例中创建的缓存类型为例,它对应的实现类为 SSMS,表示 key 和 value 均为强引用,并配置了非权重的最大缓存大小限制,类图关系如下:
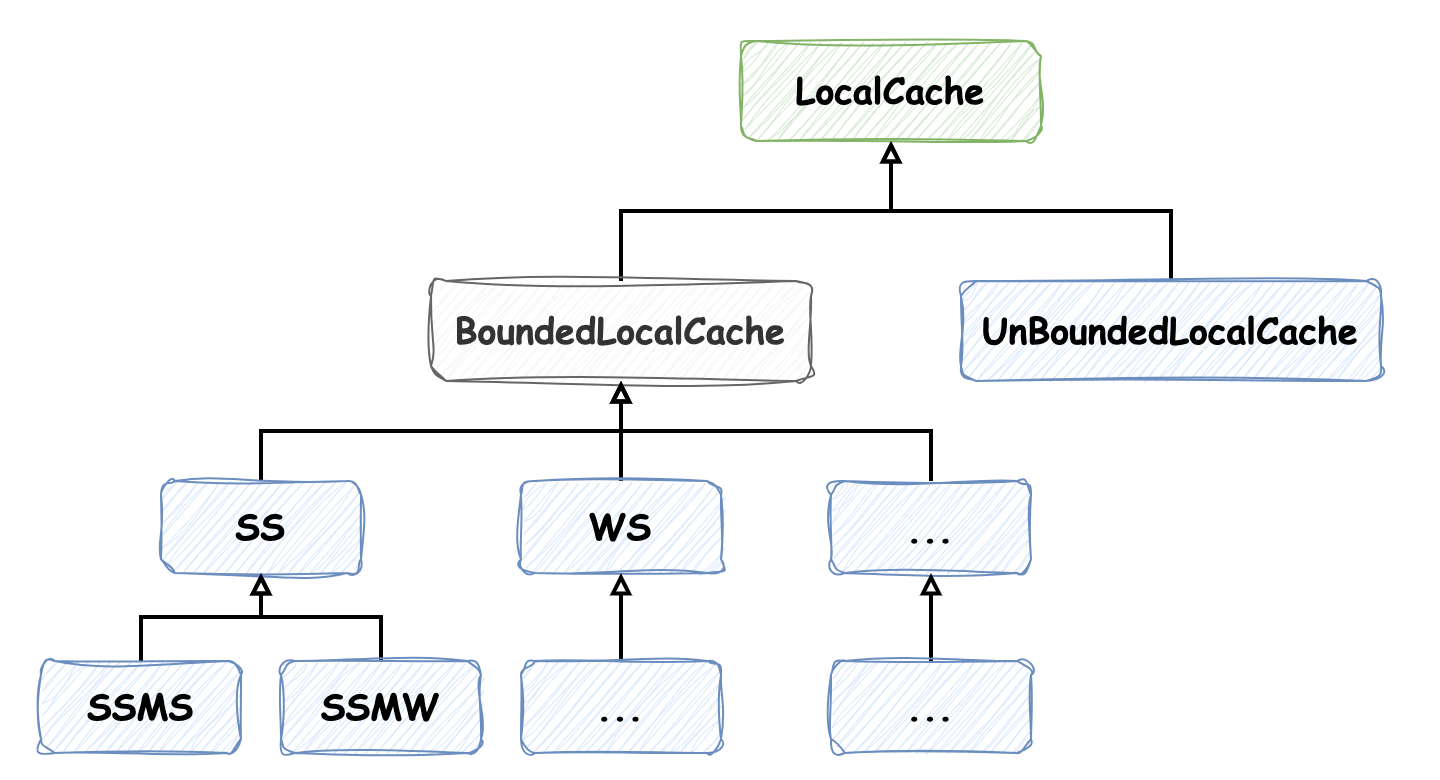
虽然在一些软件设计相关的书籍中强调“多用组合,少用继承”,但是这里使用多级继承我觉得并没有增加开发者的理解难度,反而了解了它的命名规则后,能更清晰的理解各个缓存所表示的含义,更好地实现代码复用。
执行 SSMS 的构造方法会有以下逻辑:
// 1
abstract class BoundedLocalCache<K, V> extends BLCHeader.DrainStatusRef
implements LocalCache<K, V> {
static final int WRITE_BUFFER_MIN = 4;
static final int WRITE_BUFFER_MAX = 128 * ceilingPowerOfTwo(NCPU);
static final long MAXIMUM_CAPACITY = Long.MAX_VALUE - Integer.MAX_VALUE;
static final double PERCENT_MAIN = 0.99d;
static final double PERCENT_MAIN_PROTECTED = 0.80d;
static final double HILL_CLIMBER_STEP_PERCENT = 0.0625d;
final @Nullable RemovalListener<K, V> evictionListener;
final @Nullable AsyncCacheLoader<K, V> cacheLoader;
final MpscGrowableArrayQueue<Runnable> writeBuffer;
final ConcurrentHashMap<Object, Node<K, V>> data;
final PerformCleanupTask drainBuffersTask;
final Consumer<Node<K, V>> accessPolicy;
final Buffer<Node<K, V>> readBuffer;
final NodeFactory<K, V> nodeFactory;
final ReentrantLock evictionLock;
final Weigher<K, V> weigher;
final Executor executor;
final boolean isAsync;
final boolean isWeighted;
protected BoundedLocalCache(Caffeine<K, V> builder,
@Nullable AsyncCacheLoader<K, V> cacheLoader, boolean isAsync) {
// 标记同步或异步
this.isAsync = isAsync;
// 指定 cacheLoader
this.cacheLoader = cacheLoader;
// 指定用于执行驱逐元素、刷新缓存等任务的线程池,不指定默认为 ForkJoinPool.commonPool()
executor = builder.getExecutor();
// 标记是否定义了节点计算权重的 Weigher 对象
isWeighted = builder.isWeighted();
// 同步锁,在接下来的内容中会看到很多标记了 @GuardedBy("evictionLock") 注解的方法,表示这行这些方法时都会获取这把同步锁
// 根据该锁的命名,eviction 表示驱逐的意思,也就是说关注驱逐策略执行的方法都要获取该锁,这一点需要在后文中注意
evictionLock = new ReentrantLock();
// 计算元素权重的对象,不指定为 SingletonWeigher.INSTANCE
weigher = builder.getWeigher(isAsync);
// 执行缓存 maintenance 方法的任务,在后文中具体介绍
drainBuffersTask = new PerformCleanupTask(this);