缓存之美:Guava Cache 相比于 Caffeine 差在哪里?
本文将结合 Guava Cache 的源码来分析它的实现原理,并阐述它相比于 Caffeine Cache 在性能上的劣势。为了让大家对 Guava Cache 理解起来更容易,我们还是在开篇介绍它的原理:
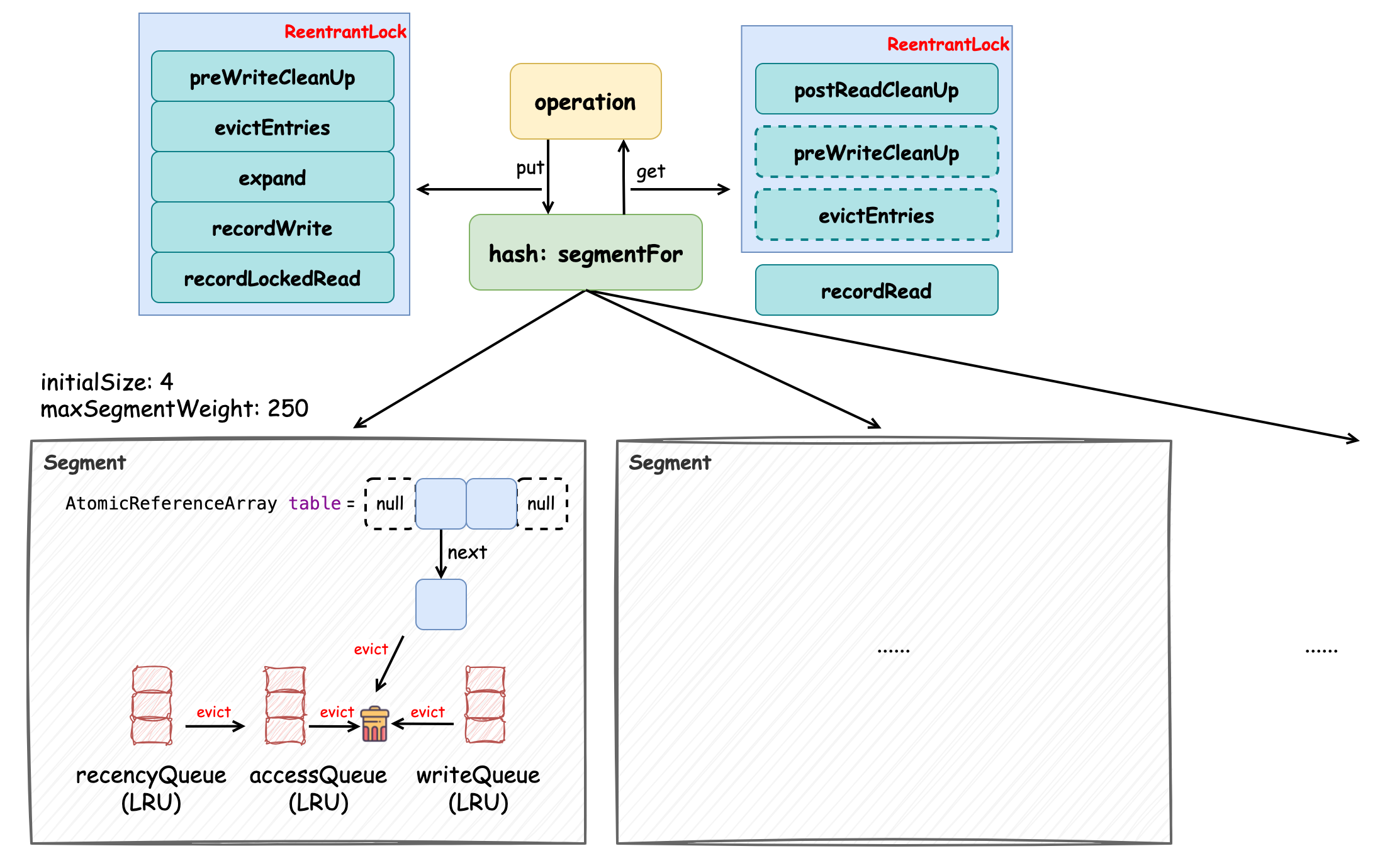
Guava Cache 通过分段(Segment)锁(ReentrantLock)机制、volatile 变量和多种缓存策略实现了性能相对 Caffeine 性能较差的缓存,它的数据结构如上图所示。它会将缓存分成多个段(Segment)去管理,单个段内写操作加锁互斥,如果要创建大小为 1000 的缓存,那么实际上会分配 4 个段,每个段的最大容量为 250。读写操作在执行时都会经 segmentFor 方法“路由”到某一个段。数据结构的实现都在 Segment 中,它对元素的管理采用的是 AtomicReferenceArray 数组,在初始化时是较小的容量,并随着元素的增多触发扩容机制。我们称数组中每个索引的位置为“桶”,每个桶中保存了元素的引用,这些元素是通过单向链表维护的,每当有新元素添加时,采用的是“头插法”。此外,在 Segment 中还维护了三个基于 LRU 算法 的队列,处于尾部的元素最“新”,分别是 accessQueue、writeQueue 和 recencyQueue,它们分别用于记录被访问的元素、被写入的元素和“最近”被访问的元素。accessQueue 的主要作用是在对超过最大容量(超过访问后过期时间)的元素进行驱逐时,优先将最近被访问的越少的元素驱逐(头节点开始遍历);writeQueue 的主要作用是对写后过期的元素进行驱逐时,优先将最近最少被访问的元素驱逐,因为越早被添加的元素越早过期,当发现某元素未过期时,后续队列中的元素是不需要判断的;recencyQueue 的作用是记录被访问过的元素,它们最终都会被移动到 accessQueue 中,并根据访问顺序添加到其尾节点中。
对元素生命周期的管理主要是在 put 方法中完成的,put 相关的操作都需要加锁,如图中左上方所示,这些方法均与缓存元素的管理相关。Guava Cache 为了在不触发写操作而有大量读操作时也能正常触发对缓存元素的管理,添加了一个 readCount 变量,每次读请求都会使其累加,直到该变量超过规定阈值,也会触发缓存元素的驱逐(postReadCleanUp),保证数据的一致性,如图中右上方所示。
接下来我们通过创建最大大小为 1000,并配置有访问后和写后过期时间的 LoadingCache 来分析 Guava Cache 的实现原理,主要关注它的构造方法,put 方法和 get 方法:
public class TestGuavaCache {
@Test
public void test() {
LoadingCache<String, String> cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.SECONDS)
.expireAfterAccess(10, TimeUnit.SECONDS)
.build(
new CacheLoader<>() {
@Override
public String load(String key) {
return String.valueOf(key.hashCode());
}
}
);
cache.put("key1", "value1");
try {
System.out.println(cache.get("key"));
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}
}
constructor
首先我们来看一下它的构造方法,它会将创建缓存时指定的参数记录下来,比如访问后过期时间(expireAfterAccessNanos),写后过期时间(expireAfterWriteNanos)等等,除此之外还包括 Segment 分段对象的创建,定义分段的数量和每个分段的大小,并将这些 Segment 对象保存在一个数组中,以创建最大元素数量为 1000 的缓存为例,它会创建 4 个分段,每个分段分配 250 个元素。源码如下所示,均为赋值操作,可关注 Segment 相关逻辑:
class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V> {
static final int MAX_SEGMENTS = 1 << 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
final int concurrencyLevel;
final Strength keyStrength;
final Strength valueStrength;
final Equivalence<Object> keyEquivalence;
final Equivalence<Object> valueEquivalence;
final long maxWeight;
final Weigher<K, V> weigher;
final long expireAfterAccessNanos;
final long expireAfterWriteNanos;
final long refreshNanos;
final RemovalListener<K, V> removalListener;
final Queue<RemovalNotification<K, V>> removalNotificationQueue;
final Ticker ticker;
final EntryFactory entryFactory;
final StatsCounter globalStatsCounter;
@CheckForNull final CacheLoader<? super K, V> defaultLoader;
final int segmentMask;
final int segmentShift;
final Segment<K, V>[] segments;
LocalCache(CacheBuilder<? super K, ? super V> builder, @CheckForNull CacheLoader<? super K, V> loader) {
// 并发级别,不指定默认为 4
concurrencyLevel = min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// key 和 value 的引用强度,默认为强引用
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
// 键值比较器,默认为强引用比较器
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
// maxWeight 最大权重,指定了为 1000
maxWeight = builder.getMaximumWeight();
// weigher 没有指定,默认为 1,表示每个元素的权重为 1
weigher = builder.getWeigher();
// 访问后和写后过期时间,默认为 0,表示不设置过期时间
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
// 刷新时间,默认为 0,表示不刷新
refreshNanos = builder.getRefreshNanos