缓存有大key?你得知道的一些手段
背景:
最近系统内缓存CPU使用率一直报警,超过设置的70%报警阀值,针对此场景,需要对应解决缓存是否有大key使用问题,扫描缓存集群的大key,针对每个key做优化处理。
以下是扫描出来的大key,此处只放置了有效关键信息。
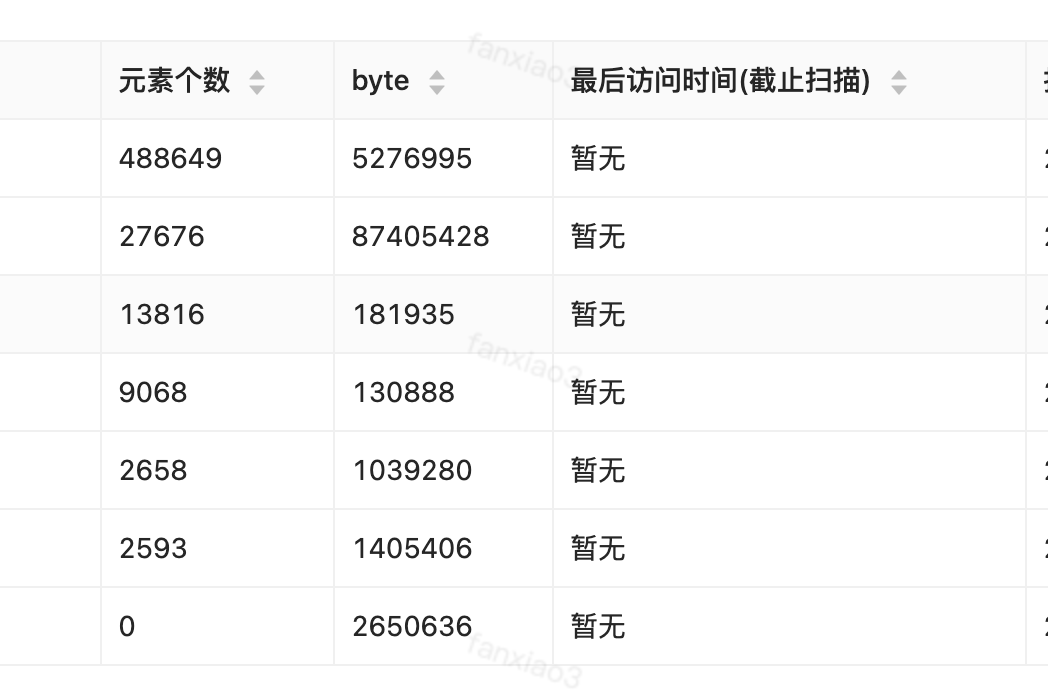
图1
大key介绍:
想要解决大key,首先我们得知道什么定义为大key。
什么是大KEY:
大key 并不是指 key 的值很大,而是 key 对应的 value 很大(非常占内存)。此处为中间件给出的定义:
大KEY带来的影响:
知道了大key的定义,那么我们也得知道大key的带来的影响:
大KEY解决手段:
1、历史key未使用
场景描述:
针对这种key场景,其实存在着历史原因,可能是伴随着某个业务下线或者不使用,往往对应实现的缓存操作代码会删除,但是对于缓存数据往往不会做任何处理,久而久之,这种脏数据会一直堆积,占用着资源。那么如果确定已经无使用,并且可以确认有持久化数据(如mysql、es等)备份的话,可以直接将对应key删除。
实例经验:
如图1上面的元素个数488649,其实整个系统查看了下,没有使用的地方,最近也没有访问,相信也是因为一直没有用到, 否则系统内一旦用了这个key来操作hgetall、smembers等,那么缓存服务应该就会不可用了。
2、元素数过多
场景描述:
针对于Set、HASH这种场景,如果元素数量超过5000就视为大的key,以上面图1为例,可以看到元素个数有的甚至达到了1万以上。针对这种的如果对应value值不大,我们可以采取平铺的形式,
实例经验:
比如系统内历史的设计是存储下每个品牌对应的名称,那么就设置了统一的key,然后不同的品牌id作为fild,操作了hSet和hGet来存储获取数据,降低查询外围服务的频率。但是随着品牌数量的增长,导致元素逐步增多,元素个数就超过了大key的预设值了。这种根据场景,我们其实存储本身只有一个品牌名称,那么我们就针对于品牌id对应加上一个统一前缀作为唯一key,采用平铺方式缓存对应数据即可。那么针对这种数据的替换,我这里也总结了下具体要实现的步骤:
修改代码查询和赋值逻辑:
历史数据刷新到新缓存key:
为了避免上线之后出现缓存雪崩,因为替换了新的key,我们需要通过现有的HASH的数据刷新到新的缓存中,所以需要历史数据处理。
通过hGetAll获取所以元素数据
循环缓存元素数据操作存储新的缓存key和value。
public String refreshHistoryData(){
try {
String key = "historyKey";
Map<String, String> redisInfoMap= redisUtils.hGetAll(key);
if (redisInfoMap.isEmpty()){
return "查询缓存无数据";
}
for (Map.Entry<String, String> entry : redisInfoMap.entrySet()) {
String redisVal = entry.getValue();
String filedKey = entry.getKey();
String newDataRedisKey = "newDataKey"+filedKey;
redisUtils.set(newDataRedisKey,redisVal);
}
return "success";
}catch (Exception e){
LOG