没时间了解技术热点?让大模型帮你整理重点吧!
1. 前言
提问:技术人的精神食粮是什么❓
AI给出的第一条是“知识与学习”。学习的方式有很多种,对笔者而言了解新技术和新热点是保持职业热爱很重要的方式。完成日常工作是保证物质基础,人终究还是想追求一些精神价值😂。

但日常工作已经占用了大量的时间,此外还有生活琐事需要对线,根本就没有时间搜集并学习新知识。这时如果有一个工具能自动抓取技术热点并将长篇大论的文字浓缩为100~200字左右的摘要,这样每天花半个小时就能消化信息了,这也太棒了吧(看过摘要也算读过文章了😁)。
2. 实现思路
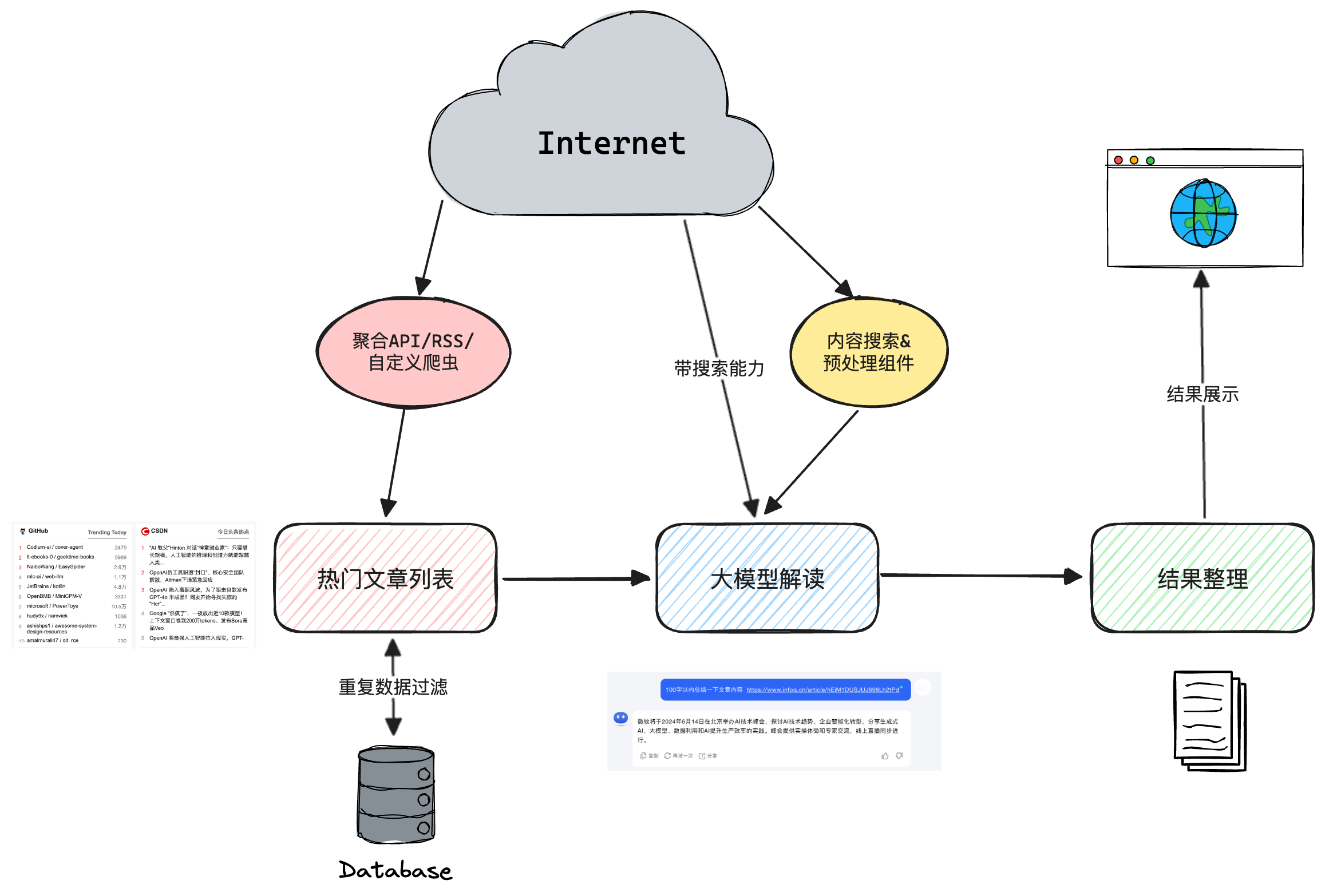
实现过程分三步走:信息收集->信息解读->结果展示。其中:
① 信息收集:对感兴趣的内容进行收集。实现方式可以使用聚合API、RSS或者自定义爬虫;
② 信息解读:通过大模型对内容进行解读。目前通过端直接访问的大模型大多都带有搜索能力,将网页发送给它就可以生成摘要。但多数大模型开放API不带搜索能力,需要自己抓取网页内容再传递给它处理;

③ 结果展示:将文章原始信息和解读后的摘要按照一定格式进行展示。
3. 落地方案
业余时间搞了一个DEMO:developer-hotspots-summary,基本实现了按照配置的榜单信息进行抓取和解读功能,但暂未实现“文章重复数据过滤”、“自定义爬虫”和“文章内容预处理”功能,后续会逐步完善。生成的结果样例如下,完整数据查看☞生成样例。
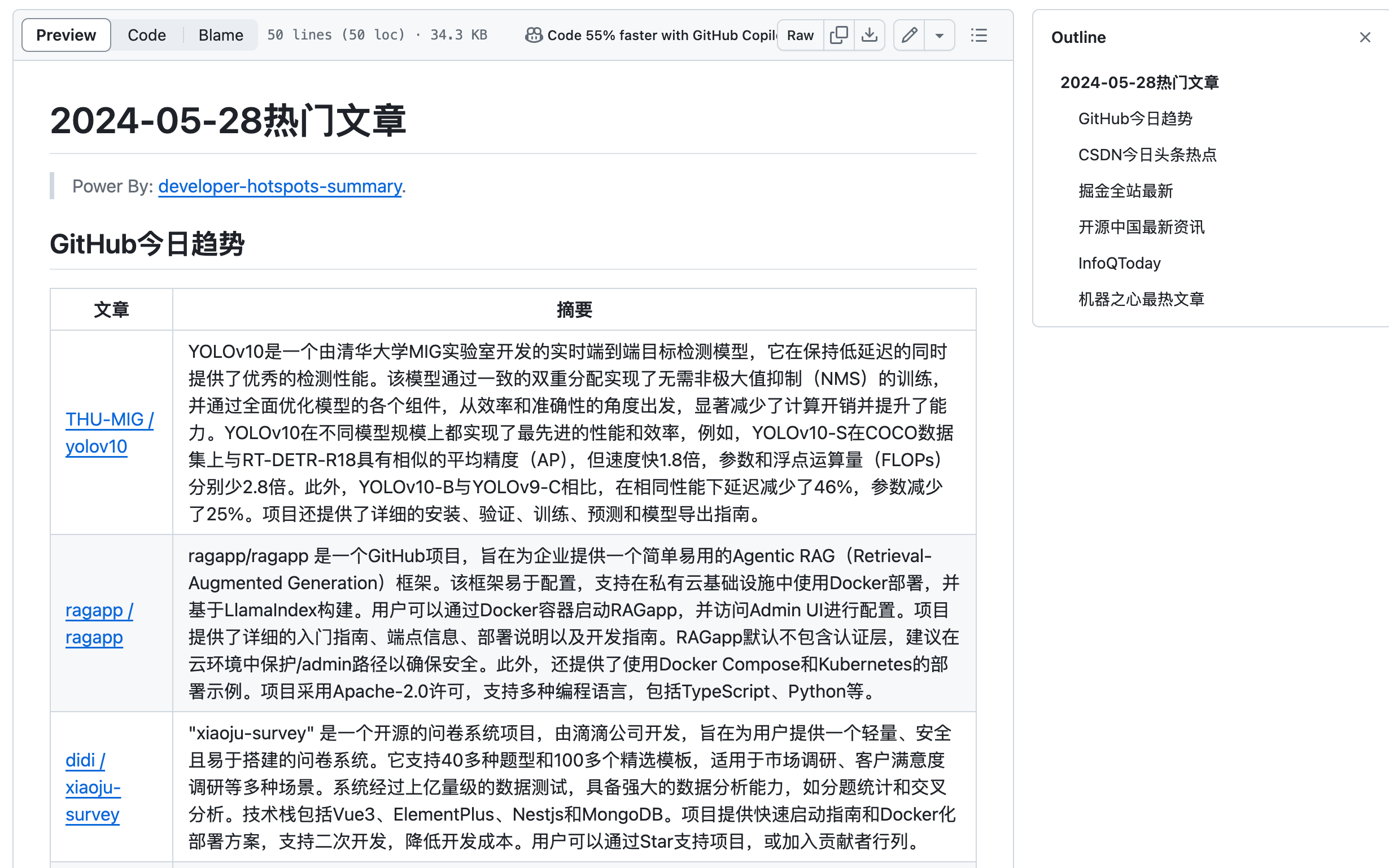
下面简要说明实现方案:
3.1 信息收集
信息收集主要是对感兴趣的内容进行收集,可使用聚合API、RSS或者自定义爬虫。目前DEMO实现了基于聚合API和RSS的内容收集,下面介绍不同方式的基本实现思路:
① 聚合API
聚合API已经对信息进行了封装并提供了易用的接口,上手难度最低,但天下没有免费的午餐一般都会按照调用量收取一定费用。DEMO中使用今日热榜的开放APITophubdata,目前提供了7500+数据源。

接口的调用也封装的很简洁,通过修改数据源类型可实时获取最新数据,具体代码实现可以查看DEMO源码。
curl --location 'https://api.tophubdata.com/nodes/mproPpoq6O' --header 'Authorization: YOUR_ACCESS_KEY'{
"error":false,
"status":200
"data": {
"hashid": "mproPpoq6O",
"name": "知乎",
"display": "热榜",
"domain": "zhihu.com",
"logo": "********",
"items": [
{
"extra": "455 万热度",
"url": "https://www.zhihu.com/question/629047878",
"thumbnail": "https://pica.zhimg.com/80/v2-00a693d9ac81c601223512d5725cbacd_1440w.png",
"description": "美联储加息周期终于似要走到尽头了。 ",
"title": "美元大跳水,10 年期美债收益率大跌,离岸人民币大涨 400 点,美股五连阳,美联储加息周期到头了吗?"
},
{
"extra": "206 万热度",
"url": "https://www.zhihu.com/question/621684259",
"thumbnail": "https://pic3.zhimg.com/50/v2-0e599dcb44ad61215462fdfbb58d983e_qhd.jpg",
"description": "感觉老一辈的亲戚总是不知道一些边界感,每次都无下限的打探我的个人问题和生活,弄得我非常的不适。要怎么样才能有礼貌的进行回应呢?",
"title": "过节聚餐时总感到亲戚在惯性「侵犯」我的边界,是我太敏感还是「亲戚PTSD」在作祟?"
}
...
]
}
}其他还有历史数据获取、WebHook功能可以自己研究一下API文档。不过由于调用会收费,不是长久之计。
② RSS源
如果网站支持RSS,那么可以通过RSS源获取到页面最新的内容信息。
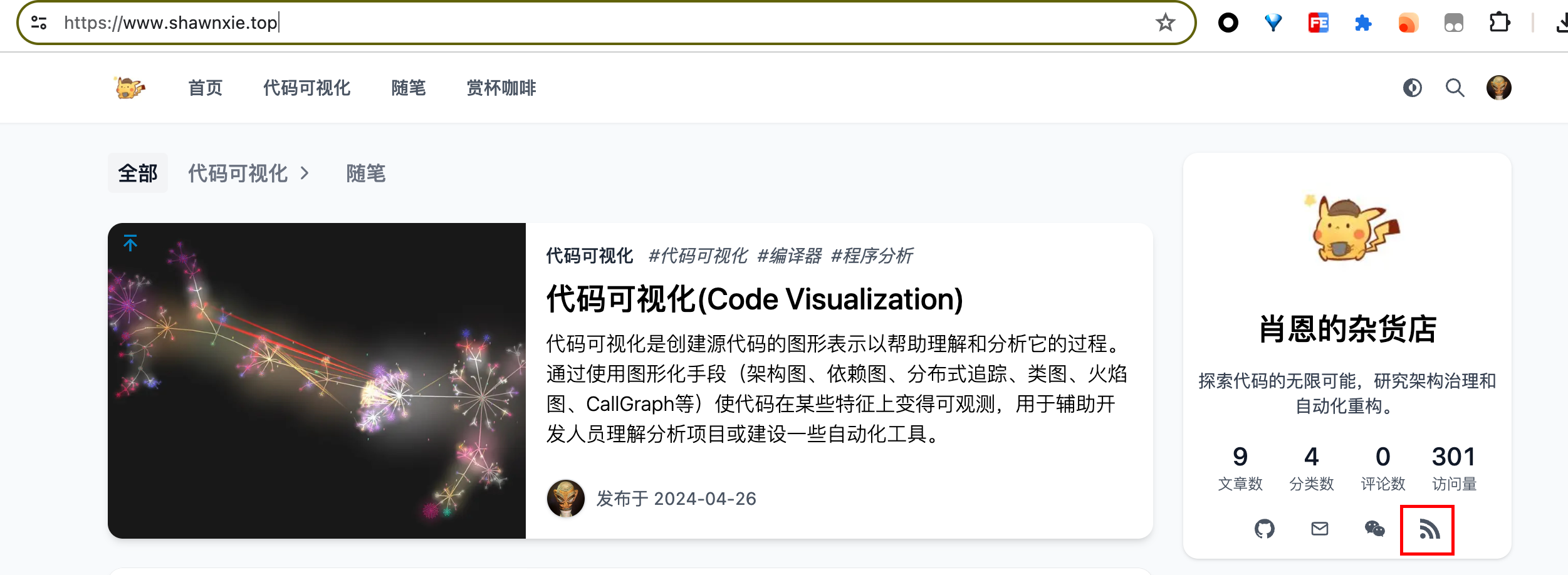

如果未提供源,那就要感谢 RSSHub项目了,它可以给各种奇奇怪怪的网站生成了 RSS 源,堪称“万物皆可 RSS”。再结合RSSHub Radar或脚本RSS+对当前页面RSS源进行检测,妈妈再也不用担心我找不到订阅源啦。更多扩展知识可阅读“可能是 2023 年最全的 RSS 源,微信公众号也有!”这篇文章,一些热门的RSS源可以在top-rss-list获取。

介绍完RSS源的获取方式后,下面用代码实现从rss源中获取文章名称和地址。
import feedparser
def parse_rss_feed(rss_url):
# 解析 RSS 源
feed = feedparser.parse(rss_url)
# 创建一个列表存储结果
result = []
# 遍历每个条目,提取标题和链接,并添加到结果列表中
for entry in feed.entries:
item = {
'title': entry.title,
'url': entry.link
}
result.append(item)
return result
# 示例 RSS 源 URL
rss_url = 'https://www.shawnxie.top/feed.xml'
# 调用函数并获取结果
parsed_feed = parse_rss_feed(rss_url)
# 打印结果
for item in parsed_feed:
print(item)③ 自定义爬虫
如果上述两种方式都不能获取到想要的信息,那就只有通过自定义爬虫了。由于实现的逻辑比较定制化,DEMO中暂时没有提供相关功能。下面举例说明抓取掘金热榜数据过程,使用Selenium加载页面,然后使用BeautifulSoup解析HTML并提取所需的信息。
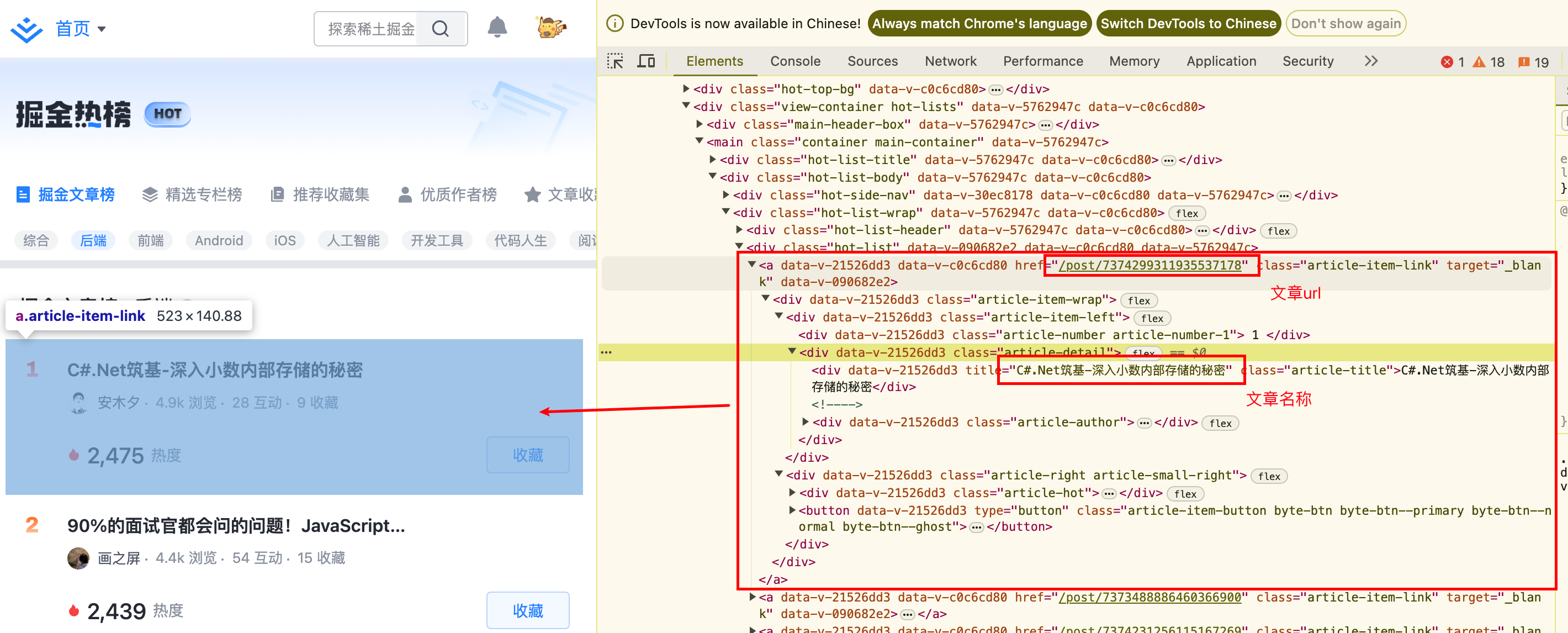
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from bs4 import BeautifulSoup
url = 'https://juejin.cn/hot/articles/6809637769959178254'
# 设置浏览器选项
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 无头模式,不显示浏览器窗口
options.add_argument('--disable-gpu')
# 启动浏览器
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
driver.get(url)
# 等待页面加载完成(根据页面复杂度设置适当的等待时间)
time.sleep(5)
# 获取页面HTML
html = driver.page_source
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')
# 查找所有文章项
article_items = soup.find_all('a', class_='article-item-link'