记一次疑似JVM内存泄漏的排查过程
一、背景
在日常部门OpsReview过程中,部门内多次遇到应用容器所在的宿主机磁盘繁忙导致的接口响应缓慢,TP99增高等影响服务性能的问题,其中比较有效的解决方案是开启日志的异步打印,可以有效避免同步日志打印在磁盘IO高起的情况下拖慢业务线程的执行效率。
部门内的jimkv应用为了配合仓做切量,在最近将日志打印功能降到了INFO级别,打开日志打印以便问题排查,期间遇到过一次因宿主机磁盘繁忙引起TP99升高导致多个comsumer超时而影响了个别业务。
经过评估遂对组内的两个基础应用(pk和jimkv)切换为异步日志打印功能,在pk上线一周后观察无异常情况后对jimkv也同样切换。
具体切换方法为在项目里和log4j2.xml同级目录下创建log4j2.component.properties文件,配置如下:
# 所有Logger异步配置
log4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector
# 日志队列满的处理策略,丢弃
log4j2.asyncQueueFullPolicy=Discard
# 丢弃日志的级别
log4j2.discardThreshold=ERROR
但是在jimkv开启3天后收到了JVM内存使用率超高的告警电话,担心会发生OOM而且时值周五晚就先将所有机器重启了一遍,最后一台执行jmap dump等命令来保留现场以备后续排查。
二、现象
2.1、容器和JVM配置
容器硬件配置:4C8G
JVM配置:-Xss256k -Xms4G -Xmx4G -XX:MaxMetaspaceSize=512m -XX:MetaspaceSize=512m -XX:MaxDirectMemorySize=256m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./java_pid<pid>.hprof -Dbasedir=/export/App -Dfile.encoding=UTF-8
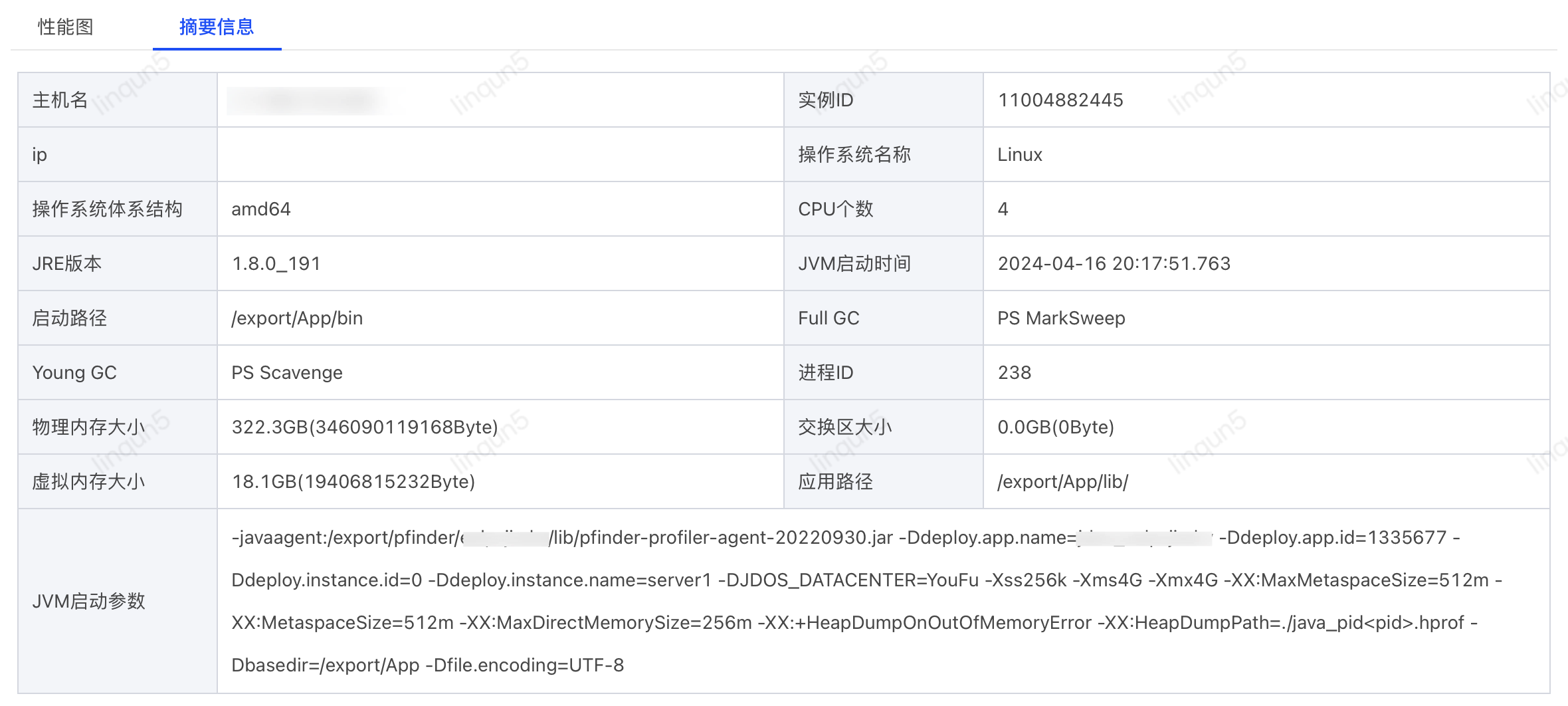
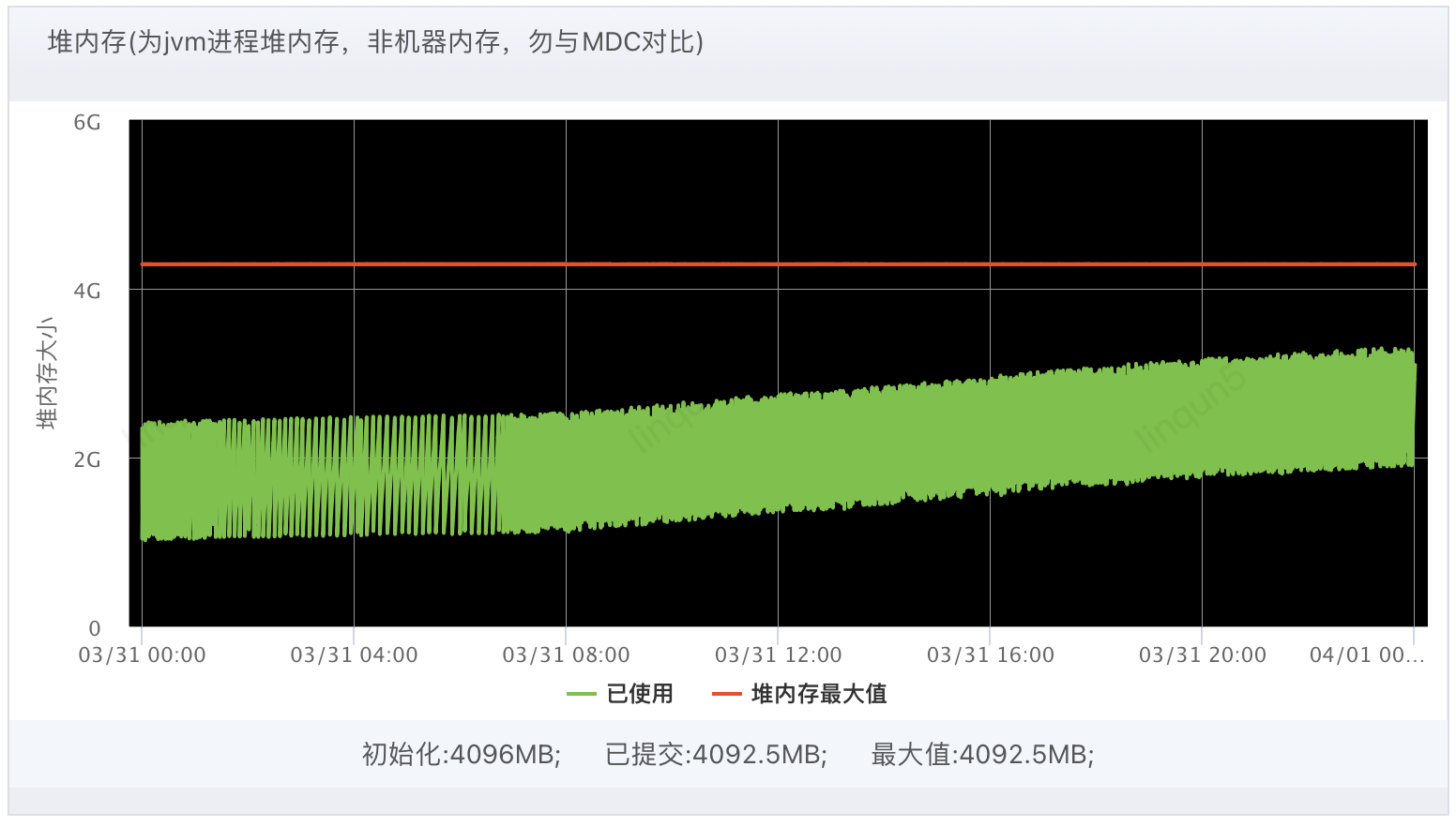
2.2、JVM监控图
下图为开启异步日志后的GC和堆内存监控图,在左下角的堆内存图可以明显的看到堆内存的上涨情况,特别是白天业务量大的时候,按此趋势正好3天就能把堆内存涨到90%的告警阈值。
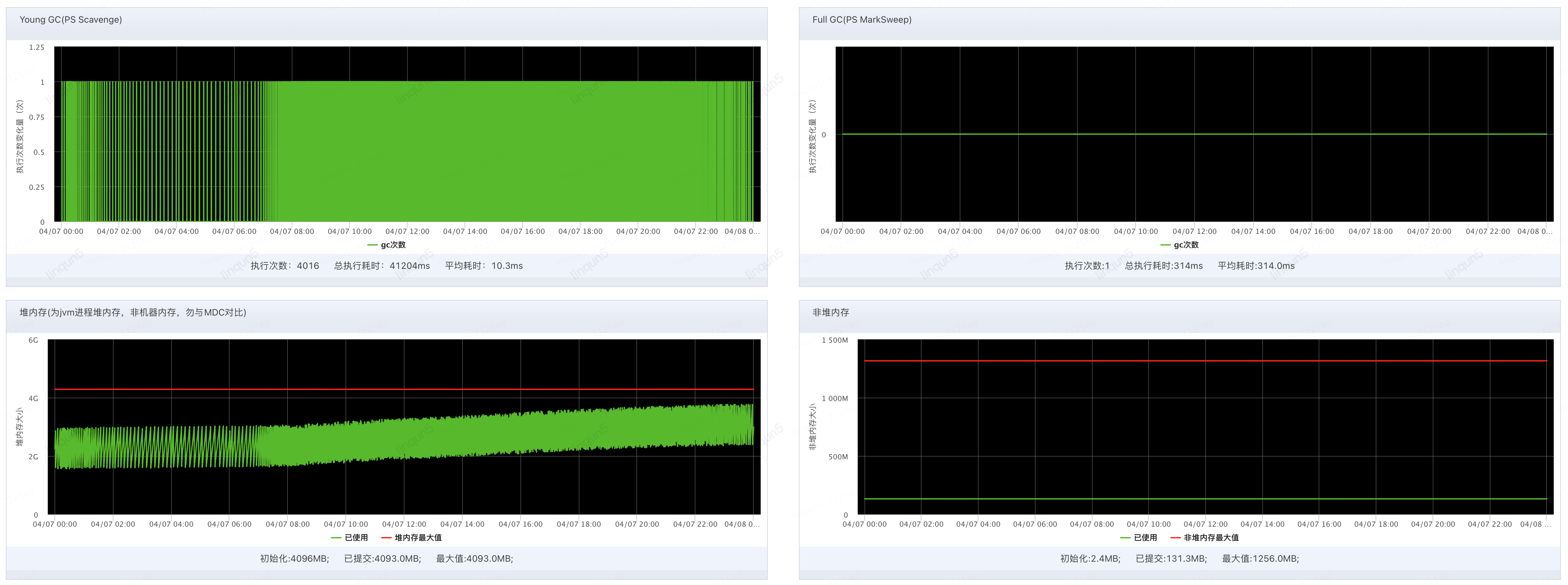
下图为未开启异步记录日志的同步记录日志的监控图,可以看到JVM的堆空间是一个很平直的波动,并不会随时间的增加而上涨。
下图是异步和同步的对比图,红色的是开启了异步记录日志:
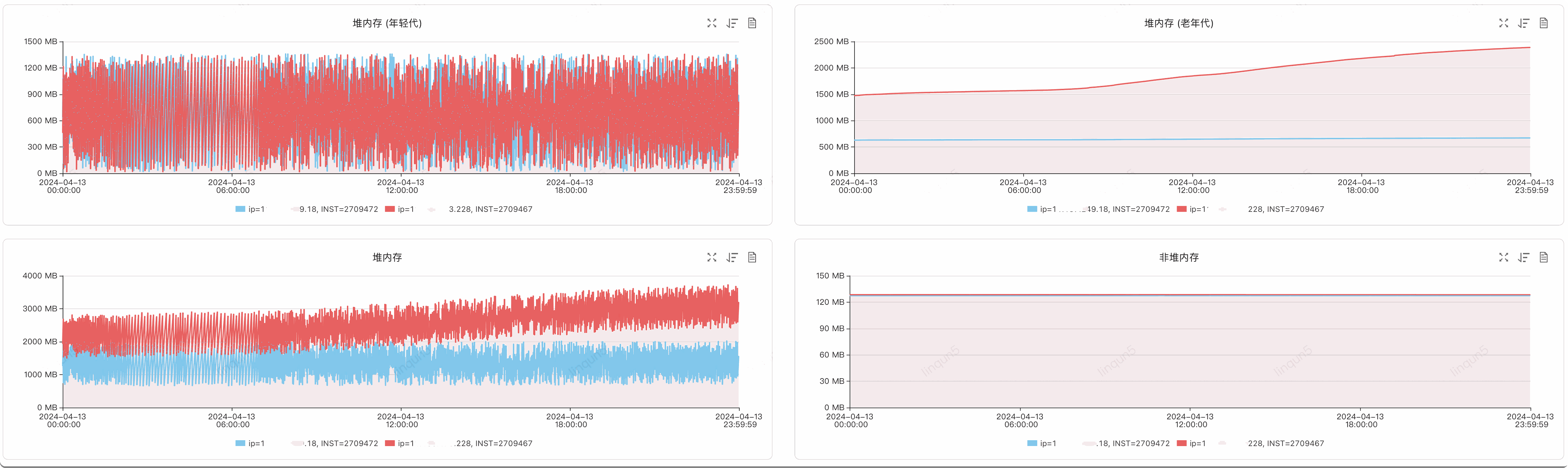
三、排查过程
分析可能出现问题的原因:
1、大日志日志导致的内存溢出;
2、日志打印太多导致的内存溢出;
3、log4j异步日志的隐藏问题/bug;
3.1、方向一:日志打印太多
首先排查上述可能的原因1&2,可以肯定的是跟日志有关,因为这个应用基本没有业务逻辑,也不存在大量的计算,最多的是日志打印,那为什么不减少日志打印或干脆关闭日志打印呢,是的,这个应用平时是关闭日志打印的,最近是为了配合仓做切量才打开的日志打印。
那么问题是由日志多导致的吗,说是,也可以说也不是,不是的原因是因为在开启异步日志之前已开启日志打印一段时间了,没有出现内存溢出的情况,所以推测日志多不是根因,它最多算是诱因。
那关闭能解决吗?直觉告诉我肯定是能解决的,但好奇心驱使我没有去这么做,一是目前没有因为内存溢出出现线上问题;二是还没有出现FGC,JVM的PS收集器是可能承受内存在几乎满的情况下通过FGC来清理内存的,我们可以留一台观察其是否会发生FGC来验证上述的想法;
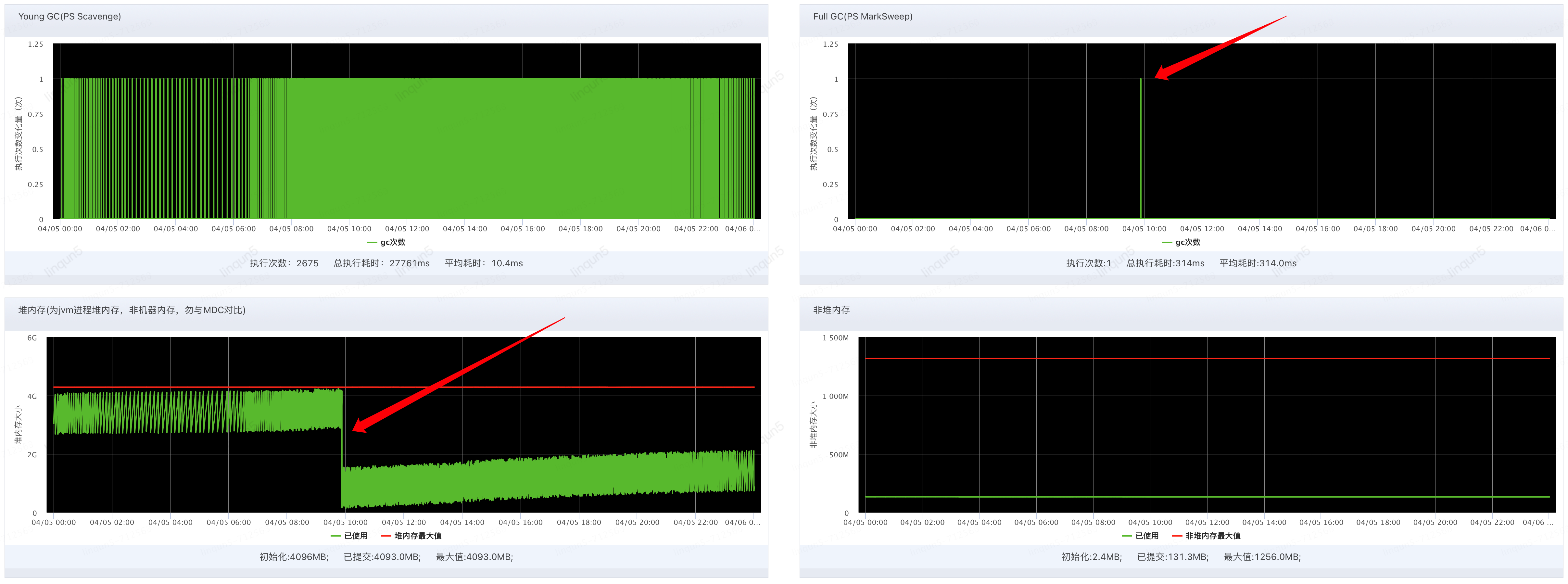
上图是留的一台机器,在某日的上午近10点果然发生了一次FGC,可以看到左下角的堆内存一下降到不到500M,接着如期继续上涨,说明其不会发生OOM,也不会对线上业务产生影响,可以放心的开启异步日志打印并随时dump堆内存现场下来分析。
这个现象最终并不会发生OOM,所以不能称其为内存溢出或泄漏,只能算作堆内存快速上涨(3天耗尽了4G内存),说明有不停的对象在YGC后被挪到了年老代,最后被FGC掉。
3.2、方向二:大日志
那既不是日志打印多引起的,会是大日志打印引起的吗?下面我们来看dump出的堆内存文件。
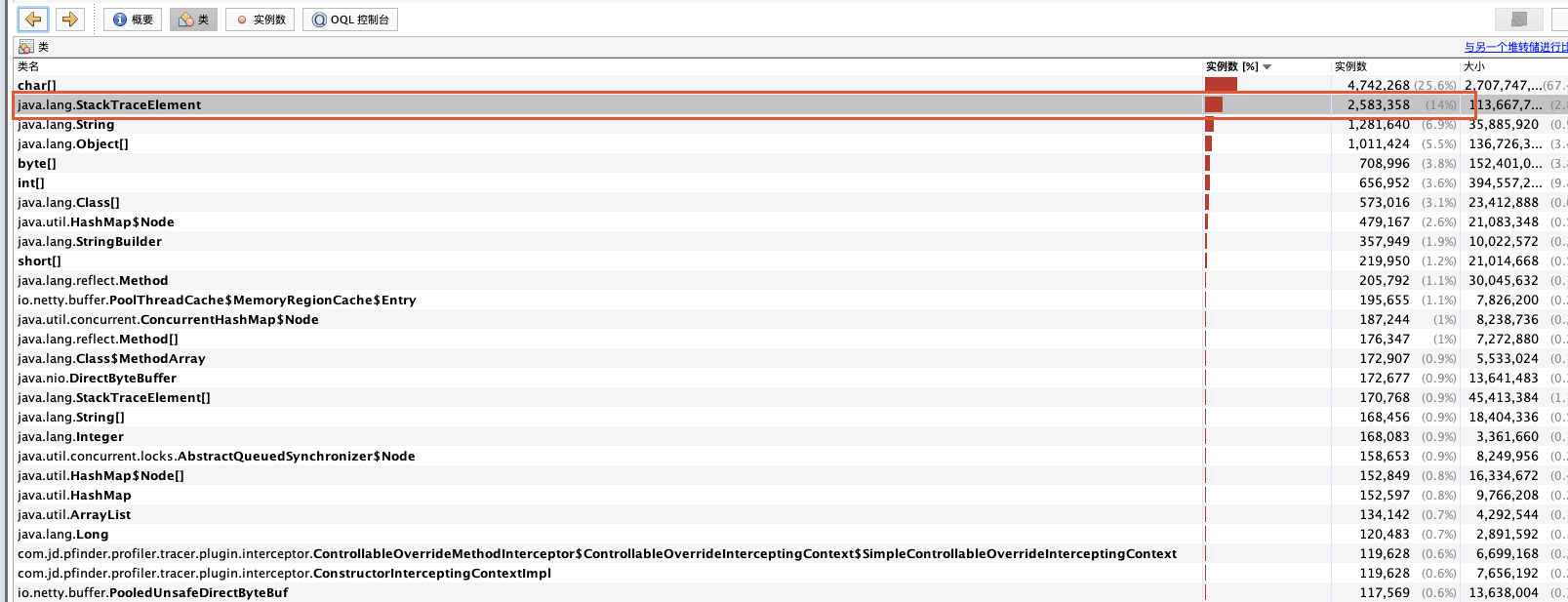
通过VisualVM打开dump下来的文件,按照实例数来倒序排,在排除char、byte、int等Java基本类型后,占据第一的是java.lang.StackTraceElement,对其进行重点排查。
StackTraceElement都是在StackTraceElement[]这个数组对象来,我们打开java.lang.StackTraceElement[]来看。

图3.2.1
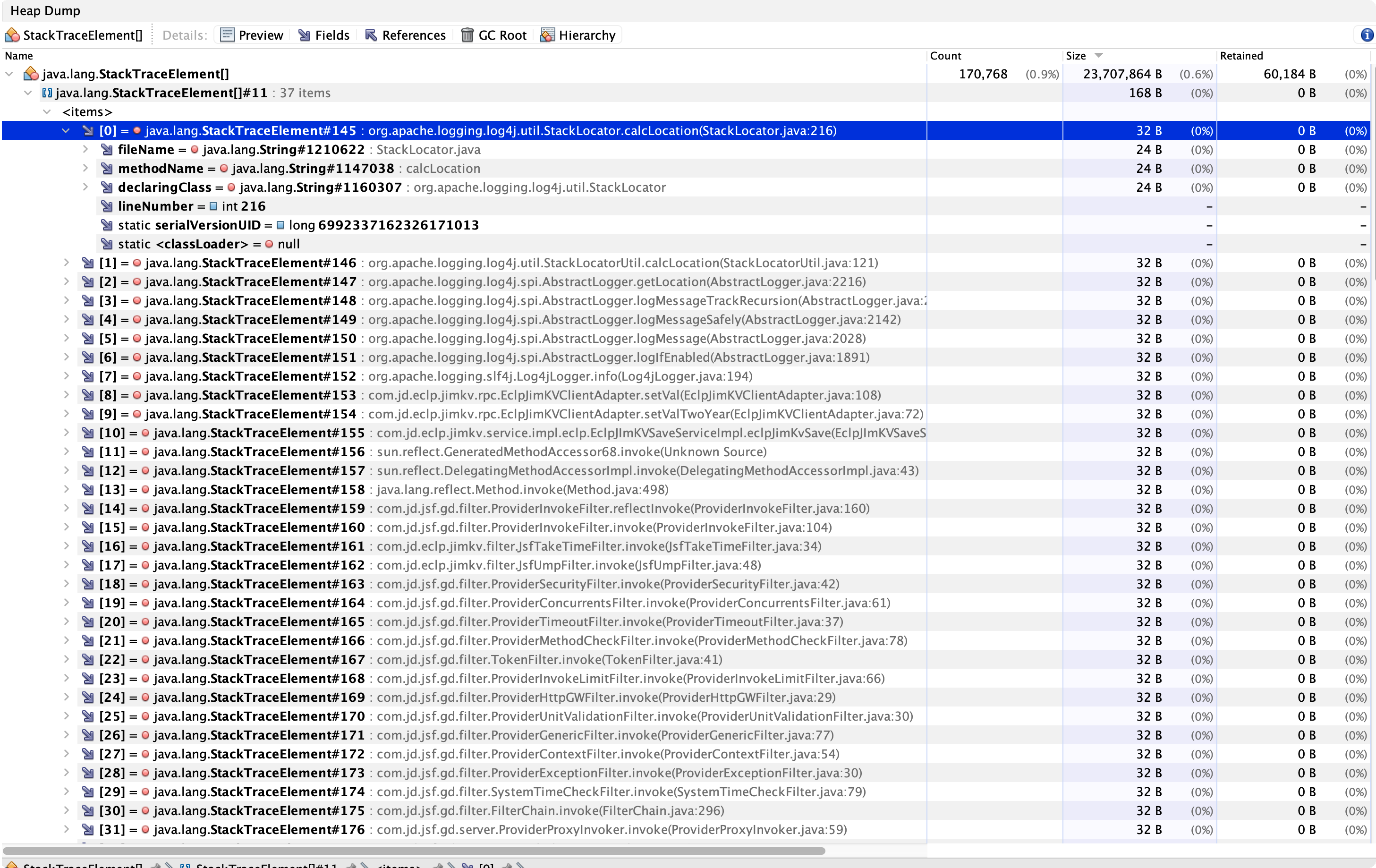
图3.2.2
可以明显看到java.lang.StackTraceElement[]里的信息是每一个线程所经过的类和方法路径,从线程入口到当前所在类方法一一记录。
此处并没有大日志,也没有日志大的相关信息,此时开始推测会不会是打印的异常日志导致的,因为应用里有一个频繁的业务异常会导致大量的堆栈信息打印,但异步日志开启前后并未有其他变化,而且也找不出可以证实的其他关键信息,只能留下来一个大大的问号【?】。
3.3、方向三:log4j异步日志bug
基本可以排除是日志多和大日志引起的原因后,开始在各大知识库里搜寻公开的log4j异步日志的bug,包括在咨询了搜索引擎和大模型后,并未得到有明确关于log4j的bug相关信息,内心也不相信强大的log4j框架有bug,就算有bug就这么让我遇到了吗,每次抽奖都轮不到的我不可能有这种运气。
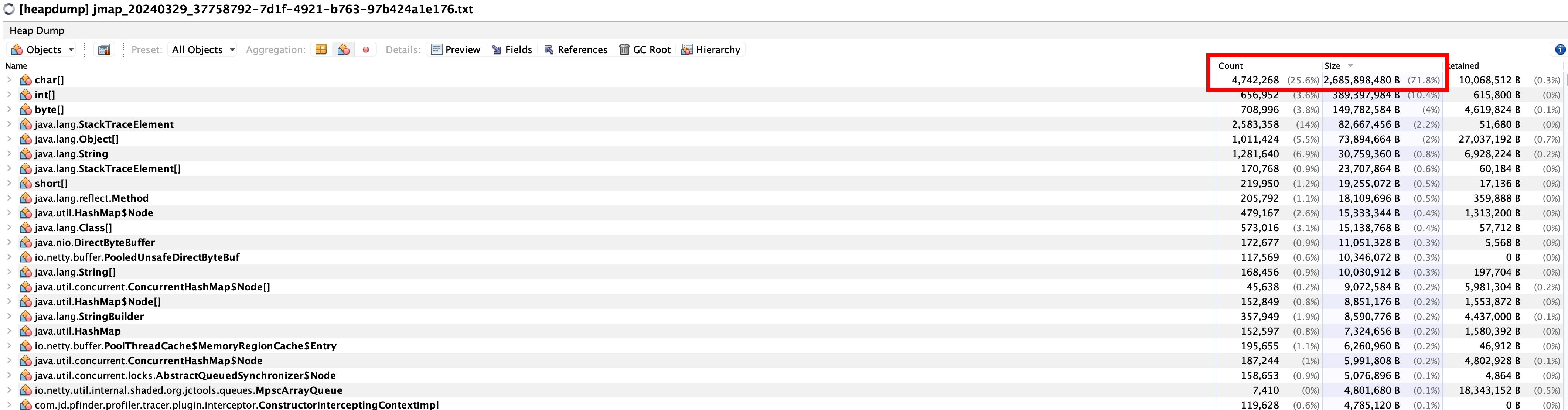
继续回头看了很多遍dump出的堆文件,在多次看着char[]占用71%的堆空间情况下,终于忍不住点开了char[],在看到满屏的日志信息后,顿感眼前一片光明,难道真的是大日志导致的堆内存空间上涨啊。。。
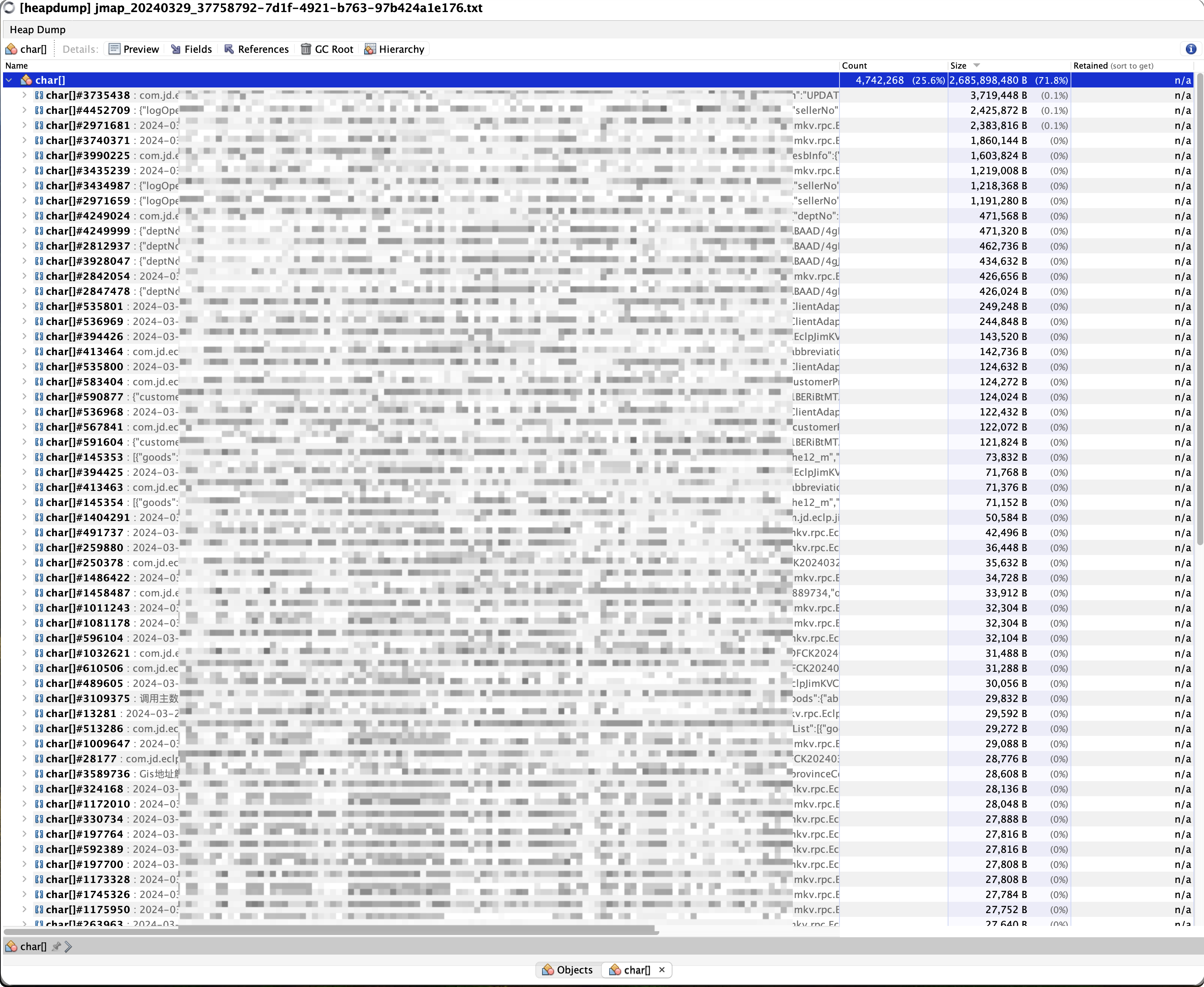
粗略的计算了下,第一大的char[]占据了3M的空间,而且char有474万个实例之多,果然是大日志搞的鬼。
随后进行了更进一步排查,为啥在开启异步日志后会出现这么大量的char[]数组出现呢?
咱们知道JVM是分代进行垃圾回收的,对象实例在一次YGC后如果还存活的话会被放在Survival区,并多次YGC后虚拟机会将还存活的对象实例从Young区挪到Old区。
从前面的堆内存图并结合JVM的分代垃圾回收知识,我们看出在每次YGC后总会有一小部分的对象实例被挪到了年老代里。
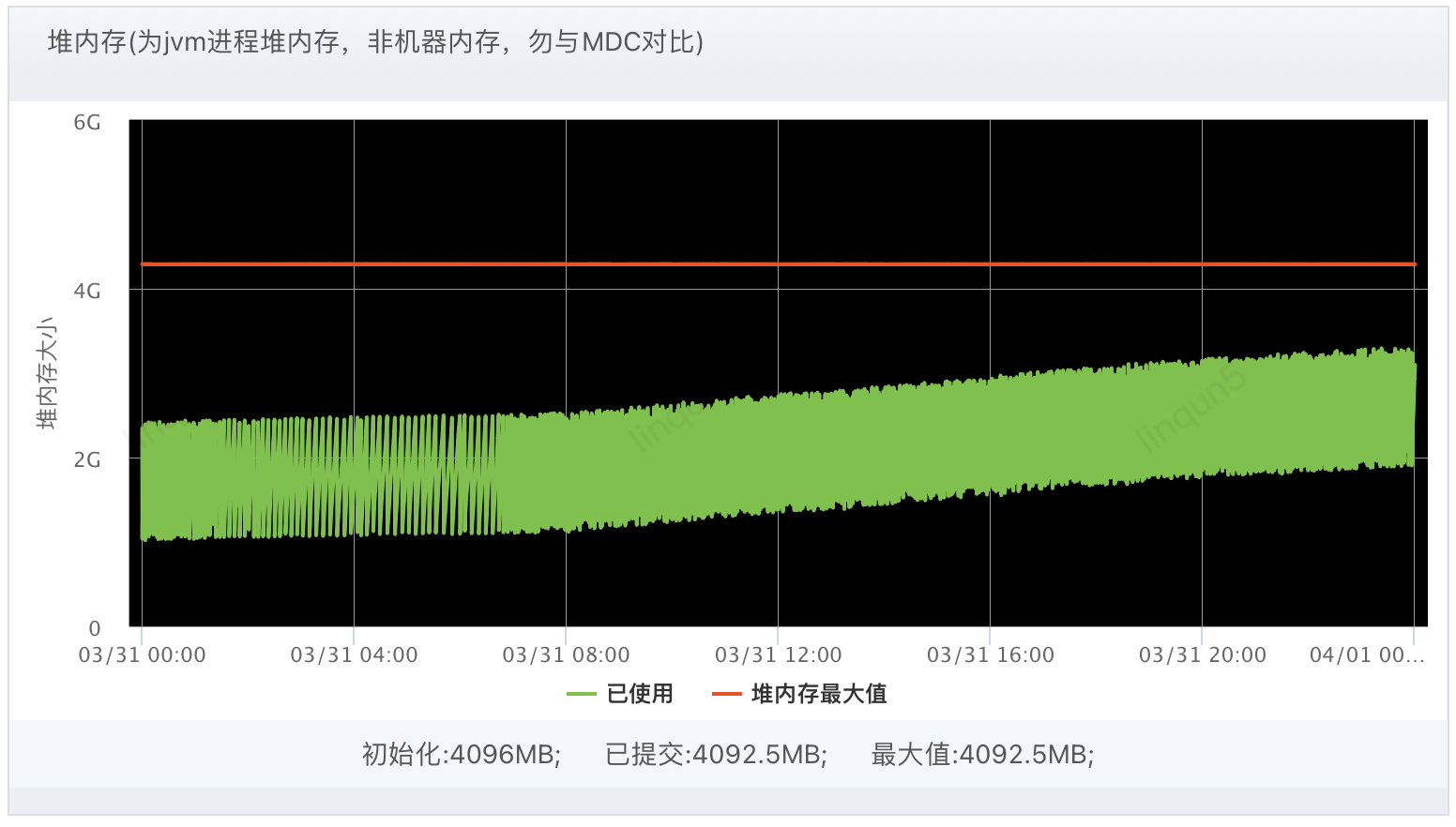
那为什么同步日志的时候没有出现这种情况呢,也就是说没有对象实例在多次YGC后还是存活的。
我们开始在log4j异步日志原理和log4j、disruptor的源码里找答案。
关于log4j异步日志原理大家可以在网上搜索相关文章,这里不做冗余介绍了,我们直接从异步日志用到的RingBuffer和RingBufferLogEvent里开始查找相关信息。
在org.apache.logging.log4j.core.async.RingBufferLogEvent#clear方法里我们看到对messageText(存储要打印的日志内容)进行了trim操作,往下追了几层,在java.util.Arrays#copyOf(char[], int)里进行了new char操作,也就是对于超过org.apache.logging.log4j.core.util.Constants#MAX_REUSABLE_MESSAGE_SIZE的日志内容进行了截断,而截断是通过底层java.util.Arrays#copyOf(char[], int)一个字符数组来实现的。

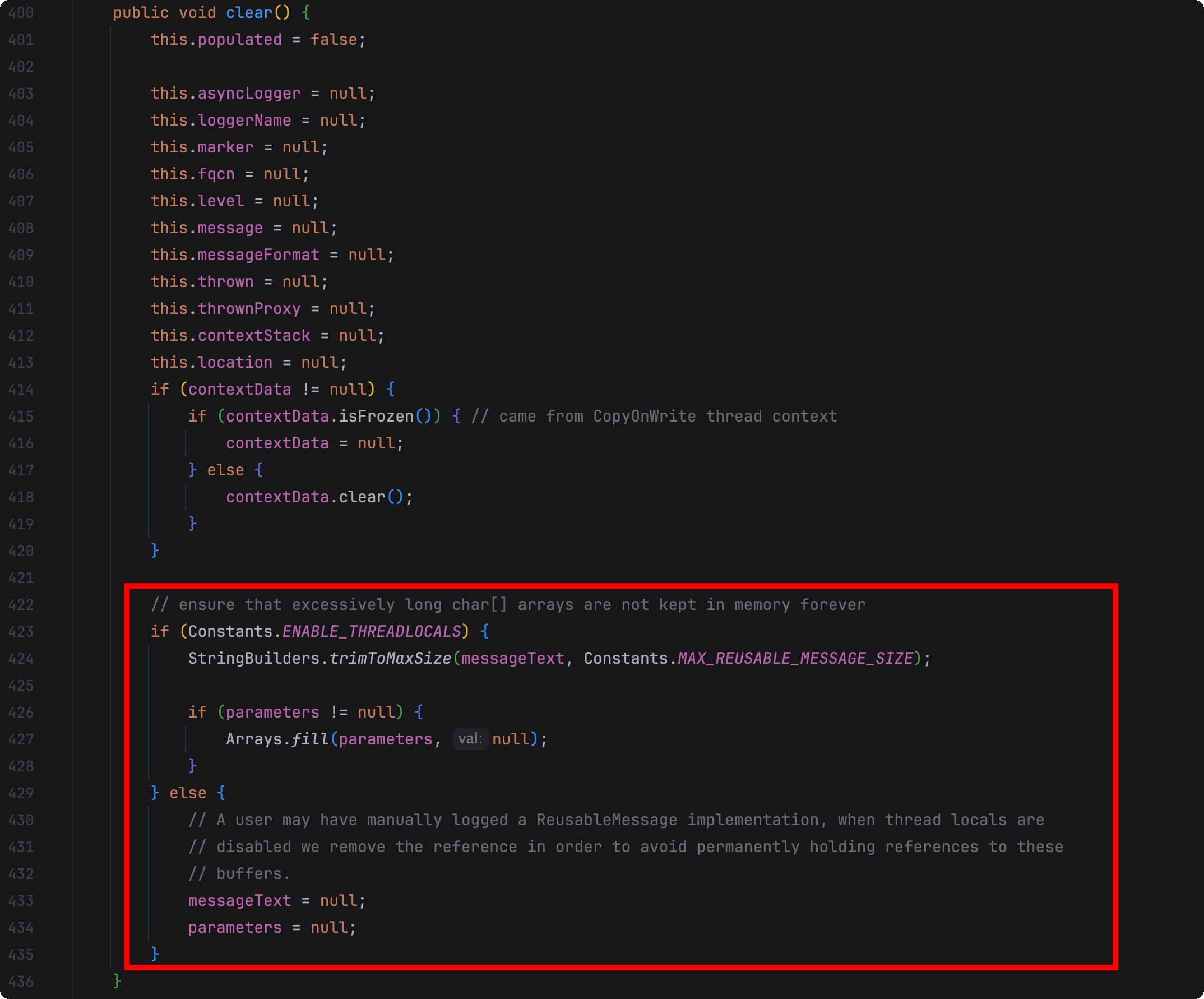



这里有两个前置条件才会进行new char[]操作
首先是org.apache.logging.log4j.core.util.Constants#ENABLE_THREADLOCALS要为True,我们来看看它的相关源码。


这里因为不是web应用,所以IS_WEB_APP=false,同时也没有配置log4j2.enable.threadlocals,默认为true。
所以这里org.apache.logging.log4j.core.util.Constants#ENABLE_THREADLOCALS=ture确认无疑。
我们再来看看org.apache.logging.log4j.core.util.Constants#MAX_REUSABLE_MESSAGE_SIZE的值。

可以看到如果没有设置log4j.maxReusableMsgSize的值,MAX_REUSABLE_MESSAGE_SIZE默认值是等于518。
也就是日志大小在大于518个字符的时候是会被截断,而截断是通过Arrays.copyOf的方式new char[]实现的。
我们决定关闭log4j2.enable.threadlocals,将其设置为false来验证是否是messageText被截断导致的堆内存上涨现象。
log4j2.enable.threadlocals=false
上线后第二天的堆内存监控图,可以看出确实没有出现堆内存上涨的情况。

3.4、方向四:无垃圾稳态日志
截止到目前堆内存上涨的问题似乎找到了原因,而且也通过配置threadlocals解决了问题,为什么说似乎呢,后面会有解释,先来看看在前面的排查过程中我们还发现了什么?

红框里的“LOG4J2-1270 no-GC”,这似乎是用户提交的一个issue,难道真的有bug?又一次带着大大的问号【?】去log4j的官网进行了搜索,https://issues.apache.org/jira/browse/LOG4J2-1270,这是有关“LOG4J2-1270”的issue,但并没有发现有用的信息。
倒是红框里最后的“no-GC”是log4j异步日志的一个特性,详细的可以访问log4j日志的官网查看,地址是https://logging.apache.org/log4j/2.x/manual/garbagefree.html。
《Garbage-free Steady State Logging》确实和前面看到的源码相符,在ENABLE_THREADLOCALS=ture的情况下除了会重用RingBufferLogEvent等外,RingBufferLogEvent里的messageText和parameters也是会被重用的,不然就会被messageText = null;和parameters = null;。
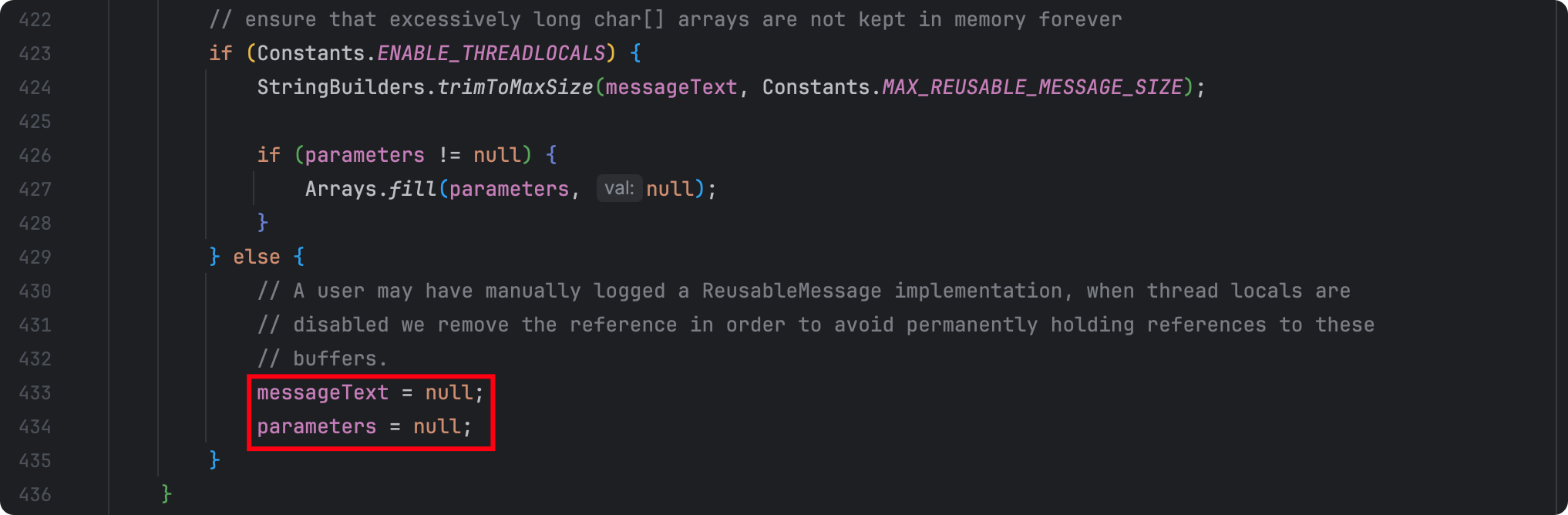
但是这里说的是“no-GC”,而现在的现象是出现了Garbage,并且是用FGC的,源码422行的备注
// ensure that excessively long char[] arrays are not kept in memory forever
翻译过来也是说的“确保过长的char[]数组不会永远保存在内存中”,似乎是哪里对不上了?
我们回到messageText上来,仔细想想异步日志虽然是重用RingBufferLogEvent,但每次在日志输出给磁盘IO后如果日志长度大于518个字符是要被new出来的char[]替掉的,也就是日志内容大于518个字符的char[]数组是活不过多次YGC的,是不可能进入到年老代的。
似乎和我们的《Garbage-free Steady State Logging》是对应的,请允许我再一次用似乎这个词,因为和现象确实是朝着两个方向走。
我们决定写一个本地测试类,来验证StringBuilders.trimToMaxSize在截断字符数组后是否会在多次GC后依然存活于堆内存中。
以下是测试类的代码,首先创建一个512长度的StringBuilder,通过循环append放入32个A和480个B,sleep30秒用来操作dump堆内存文件,再将messageText进行截断,再次操作dump,分别分析两次dump出的文件,观察char[]数组的内容。
public static void main(String[] args) throws InterruptedException {
StringBuilder messageText = new StringBuilder(512);
for (int i = 0; i < 32; i++) {
messageText.append('A');
}
for (int i = 0; i < 480; i++) {
messageText.append('B');
}
Thread.sleep(1000 * 30);
StringBuilders.trimToMaxSize(messageText, 256);
Thread.sleep(1000 *