实现“代码可视化”需要了解的前置知识-编译器前端
1. 前言
“代码可视化”的概念定义和业界案例在前文中已经进行了讲述,综述可阅读浅析“代码可视化”,更多相关知识可查看专栏“代码可视化”。本文梳理了“代码可视化”功能开发需要前置了解的编译器前端部分知识,因能力有限若有解释不清和错误的地方敬请谅解,如果想更深入正规的学习相关知识可以查看文后扩展阅读。
2. 编译器(Compiler)
主要了解前端和中端相关理论知识,后端部分和目标机器代码、特定机器架构相关一般很少用到可视化中。本文主要讲述前端部分内容,中端部分后面再另写文章。
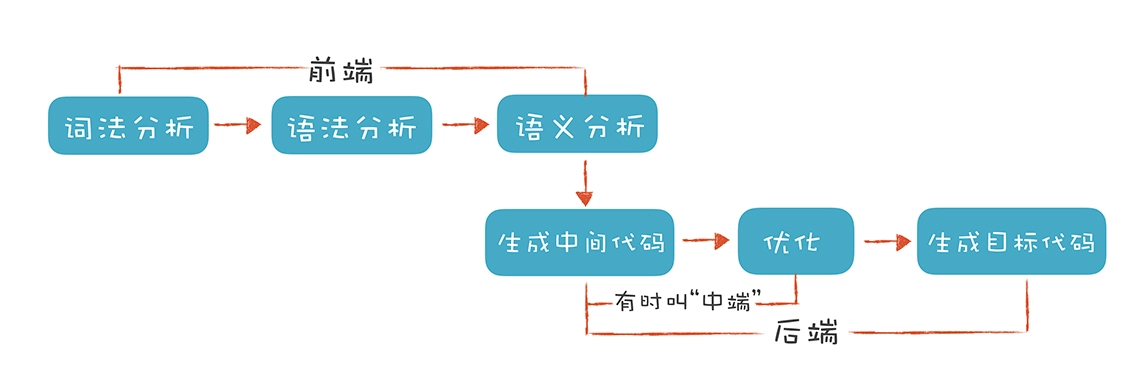
2.1 编译器工作步骤
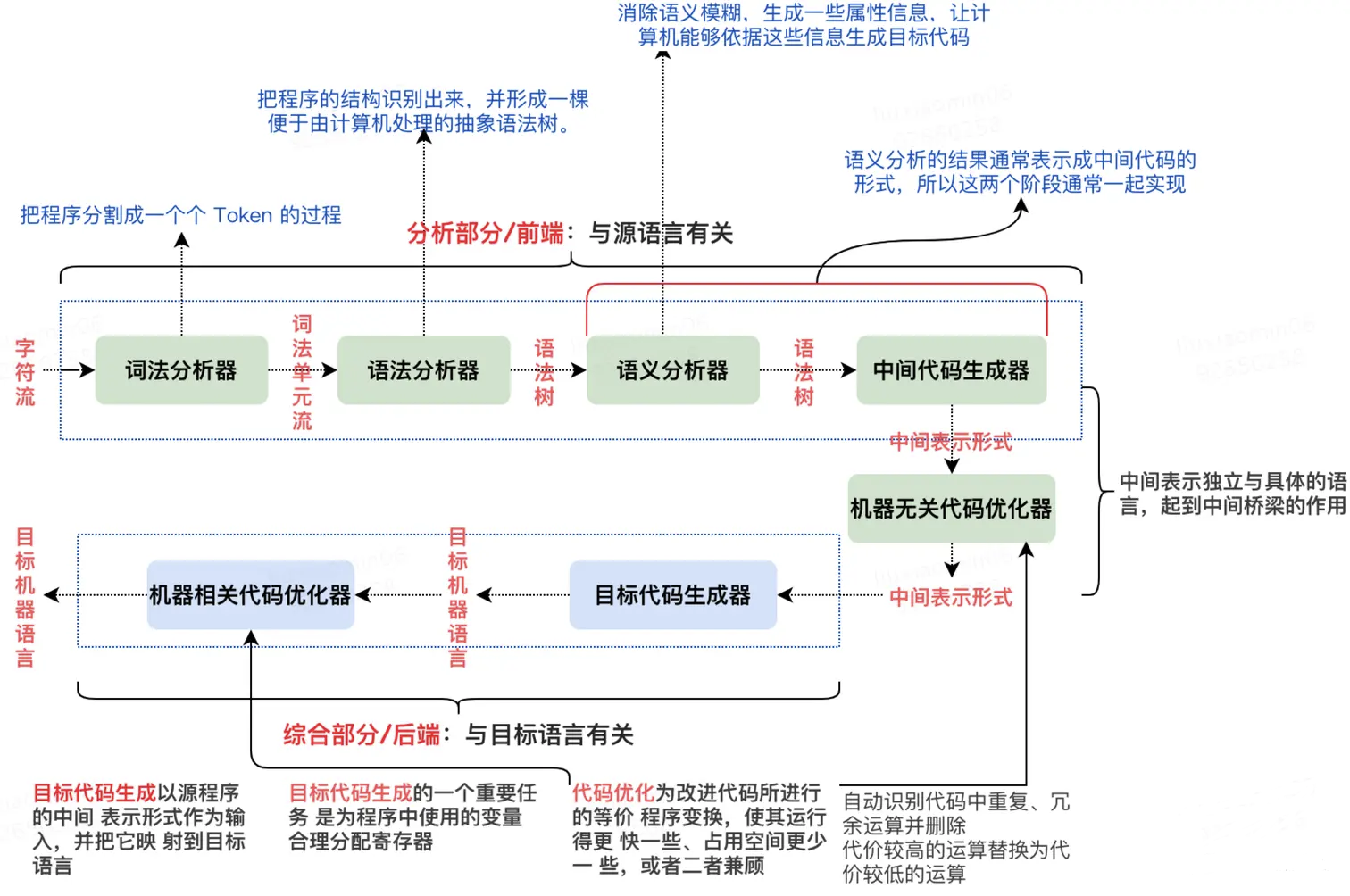
2.2 编译器前端
2.2.1 词法分析(Lexical Analysis,or Scanning)
2.2.1.1 理论知识
词法分析又称扫描(scanning),通过读入组成源程序的字符流,将它们组织成为有意义的词素(lexeme)的序列。词素是源程序中的最小语言单位,如关键字、标识符、常数、操作符和分隔符等。对于每个词素,词法分析器将产生对应的词法单元(token)作为输出。
token:<种别码,属性值>

词法分析器的核心逻辑基于有限自动机(Finite Automata),可以理解为有限个状态的自动执行机器,用来将扫描得到的字符映射到有限个的可能性上。类型包括:
整个自动构造过程见下图,大致了解一下即可,如果想深入学习各种算法细节可自行查阅资料。

2.2.1.2 实践一下
接下来我们练练手,使用Antlr对Java源码进行词法分析。Antlr是一个开源工具,支持根据规则文件生成词法分析器和语法分析器,它自身是用 Java 实现的,Mac上可以使用Homebrew安装或者直接使用idea插件antlr-v4。同时grammars-v4上提供了很多供参考的规则,我们这里也直接使用其中针对Java8定义的词法分析规则练手。
# 截取内容
- 关键字定义
ABSTRACT : 'abstract';
ASSERT : 'assert';
BOOLEAN : 'boolean';
BREAK : 'break';
BYTE : 'byte';
CASE : 'case';
CATCH : 'catch';
CHAR : 'char';
...
- 字符串字面量定义
StringLiteral: '"' StringCharacters? '"';
fragment StringCharacters: StringCharacter+;
fragment StringCharacter: ~["\\\r\n] | EscapeSequence;
...public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World");
}
}# ① 编译词法规则
antlr Java8Lexer.g4
# ② 编译上一步生成的java文件(注意需要把Antlr的JAR文件设置到CLASSPATH环境变量,否则会报错)
javac Java8Lexer.java
# ③ 调用生成的词法分析器获取分析结果
grun Java8Lexer tokens -tokens ./examples/helloworld.java
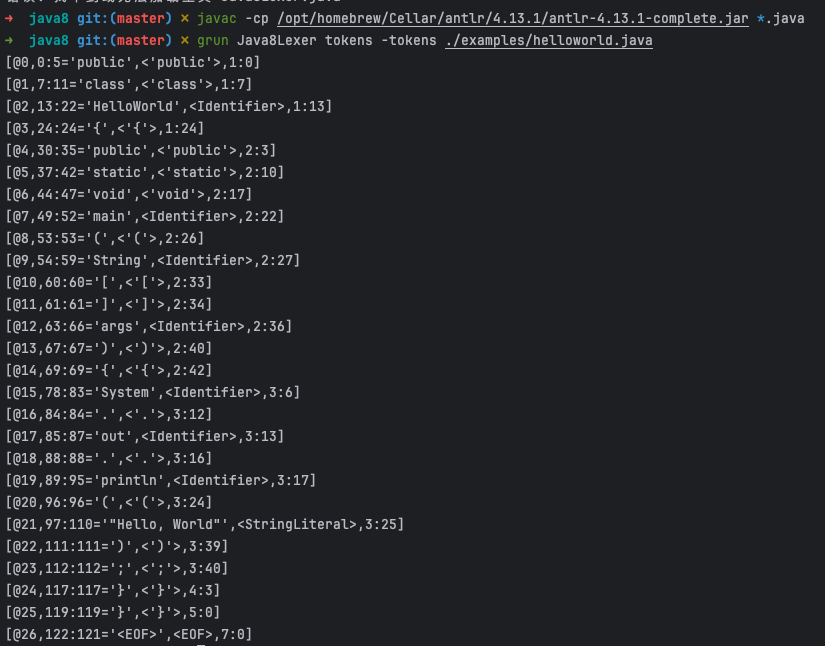
2.2.2 语法分析(Syntactic Analysis, or Parsing)
2.2.2.1 理论知识
语法分析又称解析(parsing),它在词法分析后执行。它将tokens组织成语法结构,通常是一棵抽象语法树(Abstract Syntax Tree, AST),这棵树表示了源代码的语法结构。语法分析器需要根据一组预定义的语法规则来分析词法单元序列。这些规则通常以上下文无关文法(Context-Free Grammar, CFG)的形式定义,其中每个规则定义了语言中的一个结构如何由其他结构组成。

这里先简单说一下CFG,如果想深入学习可以再查查资料。一个上下文无关文法由以下四个部分组成:
-----举个栗子-------
S → a S b
S → ε
-------解释--------
·非终结符是S。
·终结符是a和b。
·产生式规则有两条:S → a S b 表示 S 可以被 a S b 替换,S → ε 表示 S 可以被空字符串替换(ε 表示空字符串)。
·开始符号是S。
这个文法生成的语言是所有a和b的平衡字符串,例如:ab、aabb、aaabbb 等。语法分析的核心能力是给定文法G和句子s,回答s是否能够从G推导出来。实现的方式可以大致分为自底向上和自顶向下的语法分析:
2.2.2.2 实践一下
了解了基本概念后我们还是练练手,使用Antlr对Java源码进行语法分析。这次就不使用grammars-v4中定义的语法规则了,因为编程语言的语法规则比较复杂最后生成的AST可读性比较差。
grammar PlayScript;
import CommonLexer; //导入词法定义
/*下面的内容加到所生成的Java源文件的头部,如包名称,import语句等。*/
@header {
package antlrtest;
}
expression
: assignmentExpression
| expression ',' assignmentExpression
;
assignmentExpression
: additiveExpression
| Identifier assignmentOperator additiveExpression
;
assignmentOperator
: '='
| '*='
| '/='
| '%='
| '+='
| '-='
;
additiveExpression
: multiplicativeExpression
| additiveExpression '+' multiplicativeExpression
| additiveExpression '-' multiplicativeExpression
;
multiplicativeExpression
: primaryExpression
| multiplicativeExpression '*' primaryExpression
| multiplicativeExpression '/' primaryExpression
| multiplicativeExpression '%' primaryExpression
;# ① 编译语法规则
antlr PlayScript.g4
# ② 编译上一步生成的java文件(注意需要把Antlr的JAR文件设置到CLASSPATH环境变量,否则会报错)
javac *.java
# ③ 调用生成的语法分析器获取分析结果(输入表达式后使用^D触发AST图生成)
grun antlrtest.PlayScript expression -gui
age + 10 * 2 + 10
^D

2.2.3 语义分析(Semantic Analyzer)
2.2.3.1 理论知识
语义分析(semantic analyzer)使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。它同时也收集类型信息,并把这些信息存放在语法树或符号表中,以便在随后的中间代码生成过程中使用。语义规则一般包括但不限于:
由于每种语言都有其独特的语义规则和特性,例如类型系统、作用域规则、合法的操作符重载等都是语言特定的。因此,语义分析必须针对每种语言的规范来设计。
2.2.3.2 实践一下
由于不同语言的语义分析实现差异较大,没有通用的语义分析器生成工具。因此我们直接来阅读一下Java编译器中的相关源码,了解一下实现逻辑。javac中语义分析的源码位于com.sun.tools.javac.code和com.sun.tools.javac.comp包中。
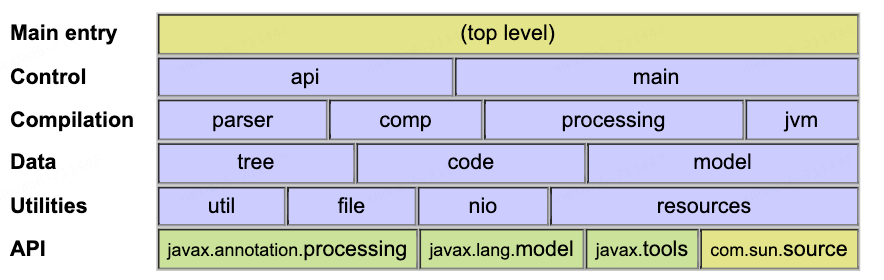
以下列举了一些语义分析的类,源码就不贴了,可以在langtools下载阅读:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号