Java面试必会
-
Bean的作用域
- 在Spring的
元素的scope属性设置bean的作用域,用来决定bean是单实例还是多实例的 - 默认情况下Spirng为每个在IOC容器里声明的bean创建唯一一个实例,整个IOC都能共享该实例,且所有getBean() 调用和 bean 引用都将返回这个唯一bean实例,该作用域被称为singleton,是所有bean的默认作用域

- bean的作用域
- singleton:默认值。当ioc一创建就会创建bean实例,而且是单例,每次得到的都是同一个
- prototype:原型的。当IOC一创建不再实例化该bean,每次调用getBean再实例化bean,而且每个实例都不同
- request:每次请求实例化一个bean
- session:在一次会话中共享一个bean
事务的四大特性ACID
1.原子性(Atomicity)
这里指系统只能处于操作之前或操作之后的状态,而不是介于两者之间的状态。sql执行时要么成功要么一起失败,不允许中间被打断
ACID原子性的定义特征是:能够在错误时中止事务,丢弃该事务进行的所有写入变更的能力。2.一致性(Consistency)
一致性就是说,事务必须使数据库从一个一致的状态转换到另一个一致的状态。也就是说一个事务在执行前和执行后都必须处于一个一致性的状态。
举个栗子,假设Gavin和Carrie的钱加起来一共是500,那么不管他们之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是500,这就是事务的一致性。
3.隔离性(Isolation)
- 在Spring的
大多数数据库都会同时被多个客户端访问。如果它们各自读写数据库的不同部分,这是没有问题的,但是如果它们访问相同的数据库记录,则可能会遇到并发问题(竞争条件(race conditions))。 ACID意义上的隔离性意味着,同时执行的事务是相互隔离的:它们不能相互冒犯。
4.持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变是永久的,即便实在数据库系统遇到故障的请胯下也不会丢失提交事务的操作。为我们提供了一个安全的地方存贮出具,而不用担心丢失。
事务的传播行为
-
一个方法运行在了一个开启了事务的方法中,当前方法是使用原来的事务还是开启一个新的事务
-

-
7种传播行为:
- REQUIRED:如果有事务在运行,就在这个事务运行,否则启动新的事务并运行
- REQUERES_NEWS:当前方法启动新事物并运行,如果有事务正在运行就将它挂起
- SUPPORTS:如果有事务在运行就在这个事务内运行,否则就不运行在事务
-
NOT_SUPPORTED: 不在事务中运行,如果有运行的事务就挂起
- MANDATORY:当前方法必须运行在事务内部,如果没有事务就抛出异常
-
NEVER: 当前方法不应该运行在事务中,如果有运行的事务就抛出异常
- NETSTED:如果有事务在运行,当前方法就在这个事务的嵌套事务内运行,否则就启动新事务并运行。
数据库事务并发问题
- 脏读: 一个事务读取到了另一个事务更新修改但还未提交的值
- 不可重复读:第一次读和第二次读的数据不一样,原因是这中间有另一个事务修改了数据
- 幻读:一个事务读取表中的数据,第二次读取该表示多出了几行数据,这中间有另一个事务向表中插入新的行
隔离级别
- 读未提交:READ UNCOMMITTED:允许事务1读取事务2未提交的数据
- 读已提交:READ COMMITTED:事务1只能读取到事务2已提交的修改
- 可重复读:REPEATABLE READ:事务执行期间禁止其他事务对这个字段进行更新,Mysql默认隔离级别
- 串行化:SERIALIZABLE:确保可以多次从一个表中读取到相同的行
SpringMVC下解决Post和Get请求中文乱码问题
- 解决Post请求:修改web.xml,注册Filter;设置CharacterEncodingFilter.class里的encoding和forceEncoding

拦截请求
<filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern>-
解决Get请求乱码问题
-
方法1:在server.xml中修改如下配置
<connector URIEncoding="UTF-8" />
SpringMVC工作流程
-
-
处理模型数据方式一:将方法的返回值设置为ModelAndView
-
方法的返回值是String,在方法的入参中传入Map、Model或ModelMap,SpringMVC最终转换为一个ModelAndView对象
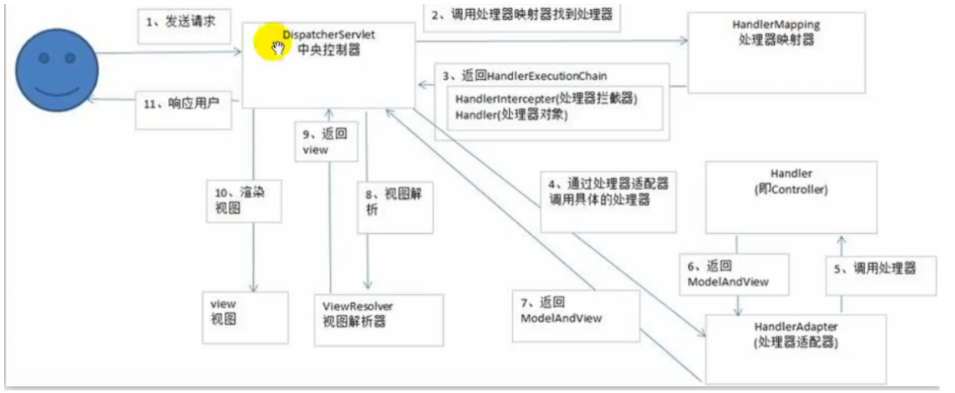
- 前台发送请求到中央控制器DispatchServlet,后者调用处理器映射器HandlerMapping处理得到拦截器HandlerExecutionChain(包含所有拦截器和处理器)返回给DispatchServlet
- DispatcherServlet通过处理器适配器HandlerAdapter调用相应的处理器Handler(即Controller)处理请求后返回ModelAndView给DispatcherServlet
- DispatcharServlet通过视图解析器(InternalResource)ViewResolver对ModelAndView进行视图解析后得到视图view
- 最后DispatcharServlet调用view里的render方法来渲染视图,响应给客户端
SpringMVC源码Debug过程(分析DispatcherServlet.class)
-
涉及的类:DispatcherServlet|View|AbstractView|InternalResourceView
-
945:DispatcherServlet.doDispatch(HttpServletRequest, HttpServletResponse) // 执行转发调度
-
916\1101:mappedHandler = getHandler(processedRequest); // 通过处理器映射器HandlerMapping得到总处理器对象HandlerExecutionChain(包含所有拦截器和处理器)
-
923行: HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler()) // 通过处理器映射器HandlerMapping处理得到适配器HandlerAdapter
-
945行:mv = ha.handler(processRequest, response, mappedHandler); // 处理器执行用户的目标方法得到modelAndView
-
1012行:render(mv, request, response); // 通过视图解析器(InternalResource)ViewResolver解析modelAndView进行视图解析并返回view
-
1225: view.render(mv.getModelInternal(), request, response); // 渲染视图
- (AbstractView.class)226行: renderMergedOutputModel(mergedModel, request, response); // 输出模型数据响应给用户
- InternalResourceView(180行):exposeModelAsRequestAttributes(model, requestToExpose); // 暴露模型数据放到request域中
- (AbstractView.class)374行:request.setAttribute(modelName, modelValue); // model放到request域中
-
InternalResourceView(189): RequestDispatcher rd = getRequestDispatcher(requestToExpose,dispatcher); // 获取转发器
-
InternalResourceView(189):rd.forward(requestToExpose, response); // 进行请求转发
MyBatis解决:当实体类属性名和数据库表中字段名不一致
-
- 写sql语句时起别名:select last_name lastName from S // 在数据库表字段不分大小写
-
- 在mybatis-config.xml开启驼峰命名规则:
<setting name="mapUnderscoreToCamelCase" value="true"/> -
在Mapper映射文件中使用resultMap来自定义高级映射规则
<resultMap type="/*包名*/" id="myMap"> <id column="last_name" property="lastName"> // 将数据库表字段与属性名一一对应 </resultMap>centos6/7常用服务命令
service/systemctl-
service/systemctl start/restart/stop/reload/status 服务名 -
查看服务命令(centos7)
systemctl list-unit-filessystemctl --type service
-
查看服务命令(centos6):
chkconfig --list|grep xxx -
(centos7)自启动:
systemctl enbale/disable 服务名- (centos6)自启动:
chkconfig --level 5 服务名 on/off
- (centos6)自启动:
git分支命令和实际应用
Redis持久化
-
Redis提供两种持久化方式:RDB(Redis Database)和AOF(Append Of File)
-
RDB: 在指定时间间隔内将内存中的数据集快照写入磁盘,恢复时将快照文件读到内存,即全量存储
- 优点: 节省磁盘空间,恢复速度快
- 缺点: 在到达指定的存储点之前如果redis挂掉,将丢失上一次快照到存储点之间所有修改。数据量庞大比较消耗性能

-
AOF:以日志的形式记录所有写操作,是增量操作,只追加文件,不修改文件
- 优点:丢失数据概率更低,备份机制稳健,可读的日志文本,通过操作AOF可以处理误操作
- 缺点:占用更多磁盘空间,恢复速度慢,有更大的性能压力,存在个别bug造成不能恢复
15. Mysql什么时候建索引
-
频繁作为查询条件的字段应该创建索引
-
查询中与其他表关联的字段,外键关系建立索引
-
单键/组合索引的选择问题,组合索引性价比更高
-
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
-
查询中统计或者分组字段,排序GROUP BY 比 ORDER BY 更烧性能
-
不要创建索引:
- 表记录太少,经常增删改的表或字段
- Where条件里用不到的字段不创建索引,过滤性不好(如性别,结果太多)的不适合建索引
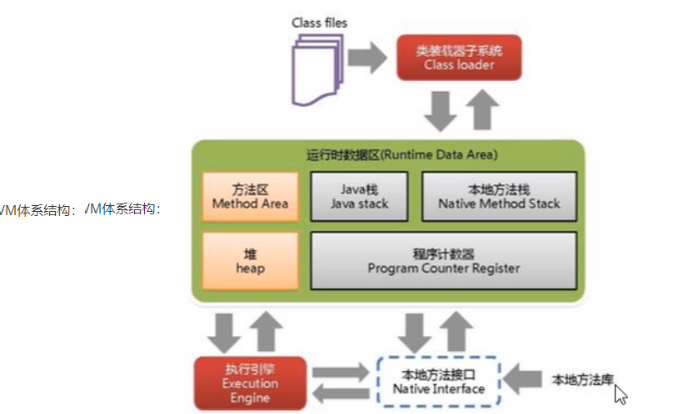
16.JVM垃圾回收机制,GC发生在JVM哪部分,有几种GC,它们的算法是什么?
JVM体系结构:
-
垃圾回收机制GC发生在堆heap中,
-
GC:分代收集算法,次数上频繁收集Young区(Minor GC),较少收集Old区(Full GC),基本不动Perm区(永久区)
-
四大算法:
- 引用计数法:一般不采用。有对象没引用,GC就不进行垃圾回收,每次对对象赋值都要维护引用计数器,较难处理循环引用
- 复制算法Copying:年轻代Young区使用Minor GC,采用的就是复制算法。从一片内存拷贝到另一片内存空间,因此没有内存碎片,且没有标记和清除过程,效率高,但耗费空间, 需要双倍空间。
- 标记清除Mark-Sweep:在Old区采用,一般由标记清除或者标记清除与标记整理的混合使用。过程:从根节点开始扫描并对存活的对象进行标记,然后扫描并回收未被标记的对象,使用free-list可以记录区域。缺点:产生内存碎片,耗时。优点:无需额外空间。
- 标记清除压缩Mark-Sweep-Compact:采用于Old区。先进行一次标记清除的过程,然后再扫描并将存活对象滑动到一端。还可以进行多次CG后才Compact压缩。优点:无内存碎片,但耗费时间.
Redis在项目中的使用场景
- String: Redis可存放incrby命令所计算出的访问次数,一个IP频繁访问服务器时,可能有风险
- Hash:存储用户信息:Hget(userKey,id); Hset(userKey,id,102),如果使用Get(userKey),会将所有信息反序列化,需要进行不必要的IO
- List:实现最新消息的排行,还可以利用List的push() 将任务存放在list中,同时使用pop()将任务取出,redis-list可用于模拟消息队列,常用于电商的秒杀
- Set:可以自动排重,比如在微博中将每个人的好友存在于集合Set中,这样求两个人的共同好友操作,只需要求交集即可。
- Zset:以某一个条件为权重进行排序,例如:商品详情的综合排名,还可以按照价格进行排名
Elasticsearch 和 solr
- 都是基于Lucene搜索服务器基础上开发,都是基于分词技术构建的倒排索引的方式进行查询
- 在实时建立索引时,solr会产生io阻塞,es不会;在不断动态添加数据时solr效率变低,es无影响
- solr利用zookeeper进行分布式管理,而es自带该功能,solr需要部署到web服务器上,solr本质是一个动态web项目
- solr支持更多格式数据,如xml,json,csv等,而es仅支持文件格式
- 单纯对已有数据进行检索时solr效率更好,而es对动态数据检索时效率更高
单点登录
-
一处登录多处使用, 前提:单点登录多使用在分布式系统中
-
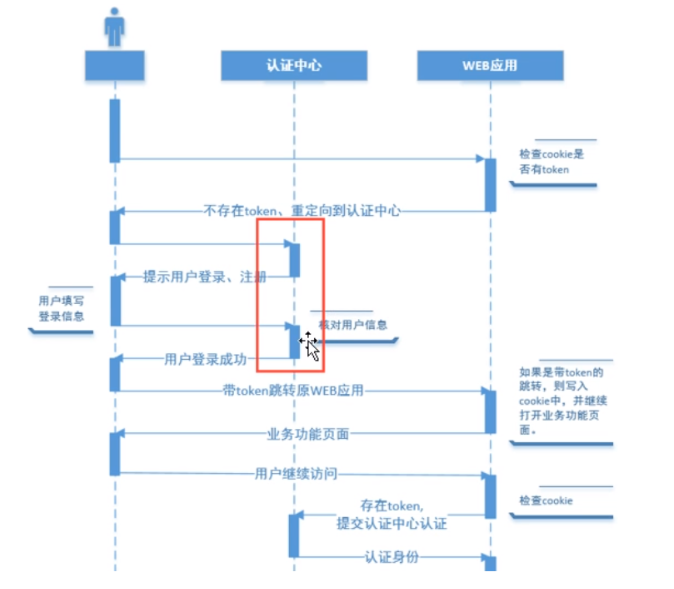
购物车实现过程
- 一个用户必须对应一个购物车,单点登录一定在购物车之前
- 添加购物车:
- 未登录:购物车数据保存在Redis/Cookie/local storage中
- 已登录:Redis(Hash:hset(user:userId:cart , skuId, value))和数据库中
- 展示购物车:
- 未登录:直接从cookie/Redis/local storage中获取数据
- 已登录:显示redis(以前保存的数据) + cookie(登录前保存的购物车)中的购物车数据
消息队列
- 高并发是分布式系统中最大的特点,使用i消息队列可以解决异步通信
- 消息的不确定性(弊端):可以采用延迟队列,轮询技术来解决该问题,可以使用activemq
-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号