(十) 数据库查询处理之排序(sorting)
1. 为什么我们需要对数据排序
- 可以支持对于重复元素的清除(支持DISTINCT)
- 可以支持GROUP BY 操作
- 对于关系运算中的一些运算能够得到高效的实现
2. 引入外部排序算法
对于不能全部放在内存中的关系的排序。就需要引入外排序,其中最常用的技术就是外部归并排序。
外部排序分为两个阶段
Phase1 - Sorting
对主存中的数据块进行排序,然后将排序后的数据块写回磁盘。
Phase2 - Merging
将已排序的子文件合并成一个较大的文件
2.1 N-way 外部归并排序
从2路归并排序开始。来引出N路归并排序算法
可以见下图


对于简单的二路归并。我们有两个buffer可以用。一个用来放输入进行排序得到归并块。而另一个则用来放输出
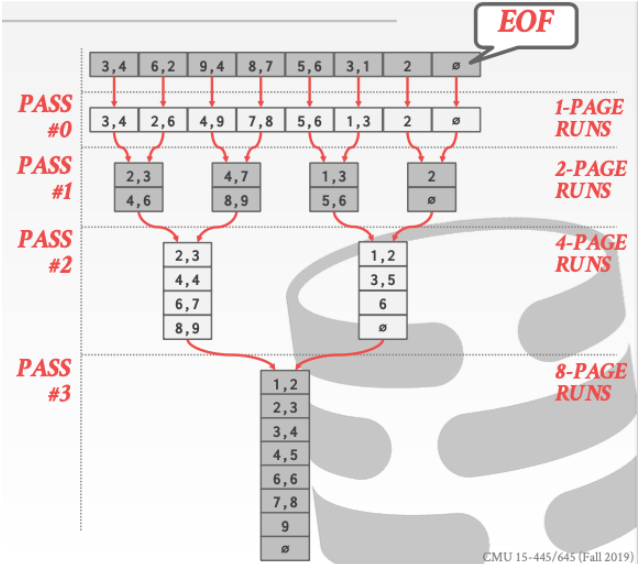
下面来分析一下二路归并的时间复杂度
在每一个阶段我们都需要把归并块从磁盘中读入。然后在写回磁盘因此总共的I/O次数就是阶段数 * 2
阶段数可以很容易的得到为

可以很容易的发现上面的问题主要出现在。由于我们的输入缓冲区只能放一个page。所以这导致了我们不停的进行换入换出导致了io次数变得非常多。优化方法就是加大缓冲区大小。减少阶段数。这就需要我们归并路数增大。
使用B buffer pages 这样我们的输入缓冲区就可以放B - 1个page。这样我们的阶段数就可以减少了。

2.2 利用索引进行加速
如果我们的table中已经有了B+树索引。那么我们可以利用它进行优化。
这里有两种情况需要被考虑
-
聚簇索引
数据的物理地址顺序和索引的顺序是一致的。
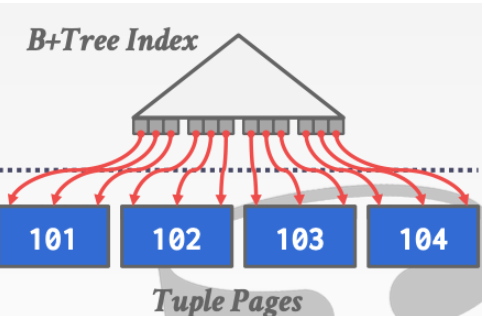
这种方法比外部排序要好,因为它没有额外的计算。比如不需要进行sort。不需要进行归并。而且所有的磁盘访问都是顺序的。
-
非聚簇索引
数据的物理地址顺序和索引的顺序是不一致的。
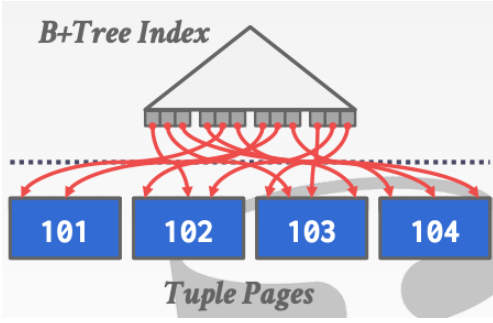
如果是这样的索引。就利用外部排序就好。
2.3 AGGREGATIONS
将多个元组折叠为单个标量值。有两种实现方法
1. 排序
排序之后相同的元素就会在排在一起。这样就可以去除冗余元素

2. hash
但是如果我们不要求数据是有序的。这样我们排序就相当于浪费了时间。因为排序起码要花费nlogn的时间。比如GROUP BY
和DISTINCT操作。在这种情况下。hashing就是一个更好的选择
1. Partition
假设我们有B buffers。其中B - 1个buffer用来partitions而1个buffer用来存储输出data。
第一阶段就是利用一个hash函数。把tuple哈希到不同的桶中。

2. Rehash
由于阶段1之后。拥有相同cid值的tuple都被映射到了相同的桶内。这个阶段我们对不同的桶在进行一次hash。就可以完成我们的去重操作。
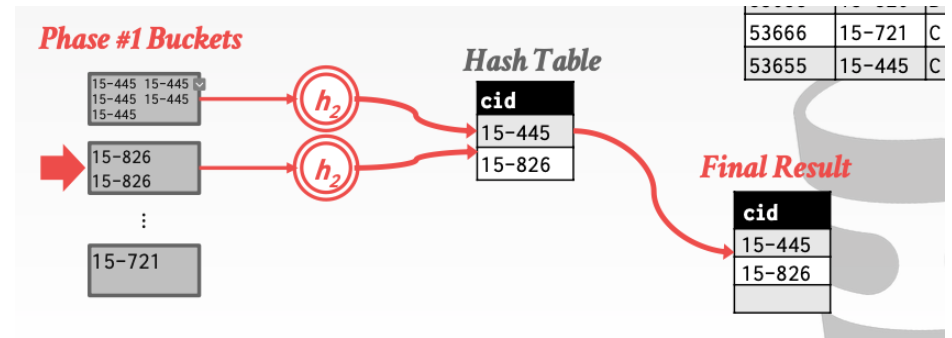
当然利用hash操作不仅可以进行去重还可以进行其他的操作。如MAX、MIN、AVG、COUNT、SUM等
下面这张图演示了count操作和sum操作。
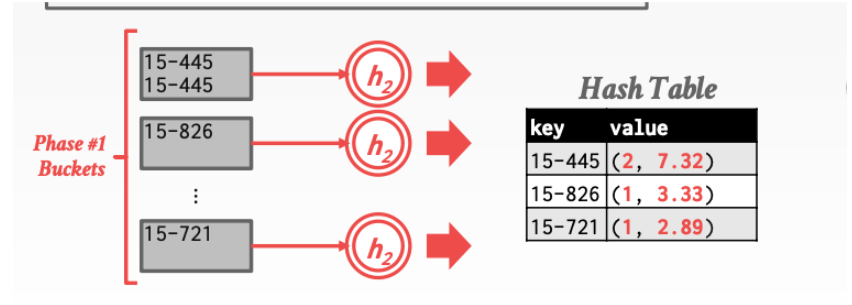
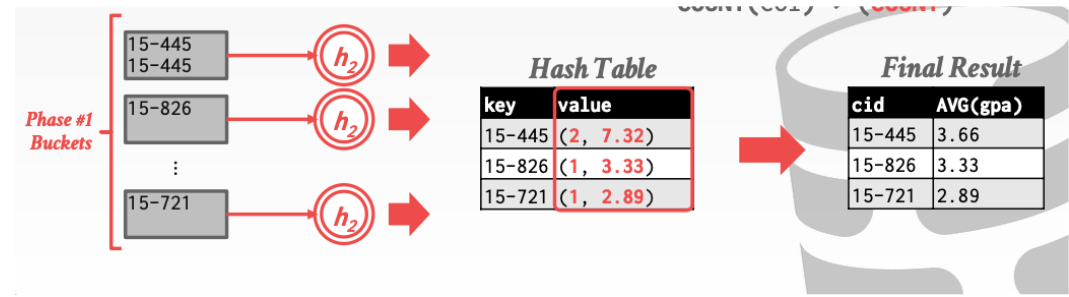
这张图演示了avg操作就是利用 sum / count
这个算是结合cmu15-445课程和对应的教材、ppt进行的总结。顺序从10开始是因为现在正好看到这里。而之前忘了整理了。会在后面所有的都看完之后进行整理的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号