系统IO
1.总体概述
UnixI/O函数
Linux系统中由内核提供的系统级的UnixI/O函数。
打开和关闭文件的函数(open 和 close),读写函数(read和write),显示修改当前文件的位置的函数(sleek),查看文件信息(也称文件的元数据)的函数(stat和fstat)
RIO函数
基于UnixI/O函数,通过反复执行读写操作,直到传送完所有的请求数据,自动处理不足值。
不足值:某些情况下,调用UnixI/O函数进行读写传递的字节比应用程序要求的少。
无缓冲输入输出函数(rio_readn 和rio_writen)
带缓冲的输入函数(rio_readinitb rio_readlineb rio_readnb)
标准I/O函数
C语言定义了一组高级输人输出函数,称为标准I/O库,为程序员提供了Unix的较高级别的替代。这个库(libc)提供了打开和关闭文件的函数(fopen 和 fclose)、和写字节的函数(fread和 fwrite)、读和写字符串的函数(fgets 和 fputs),以及复的格式化的 I/O 函数(scanf和 printf)。
三者之间的关系
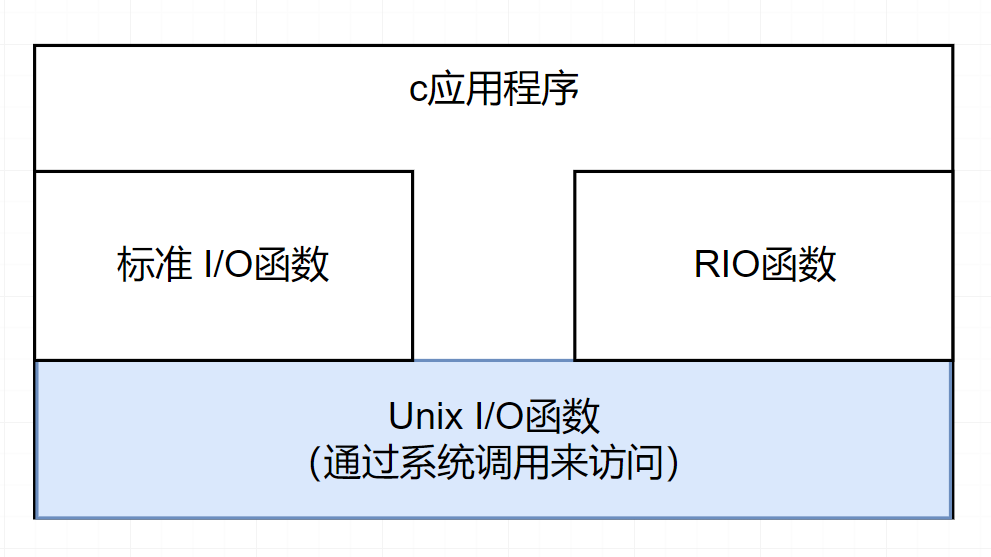
1.UnixI/O
Linux系统中所有的I/O设备都被映射为文件,所有的输入输出都被当作对相应文件的读和写来执行。
UnixI/O是Linux内核引出的一个简单、低级的应用接口,这使得所有的输入输出都能以一种统一且一致的方式来执行:
- 创建的每个进程开始时都有三个打开的文件:标准输入(描述符为0,STDIN FILENO)、标准输出(描述符为 1,STDOUT FILENO)和标准错误(描述符为 2,STDERR FILENO)。
- 打开文件。应用程序调用open函数打开相应的文件时,内核返回一个小的非负整数,叫做描述符。描述符是从描述符池中取出来的。每调用一次open函数就会分配一个描述符。每个进程都有一张描述符表,其中的每个描述符指向文件表中某一表项,文件表中记录着读写的偏移量。文件表中某一表项都有一个指针指向v-node表。详细见本章第5节。
- 改变当前的文件位置。对于每个打开的文件,内核保持着一个文件位置k,切始为0。这个文件位置是从文件开头起始的字节偏移量。应用程序能够通过执行 seek 操作,显示地设置文件的当前位置K;
- 读写文件。一个读操作就是从文件复制n>0个字节到内存,从当前文件位置k开始,然后将k增加到k+n。给定一个大小为m字节的文件,当 k>m时执行读操作会触发一个称为 end-of-file(EOF)的条件,应用程序能检测到这个条件。类似地,写操作就是从内存复制n>0个字节到一个文件,从当前文件位置k开始,然后更新k。
- 关闭文件。当应用完成了对文件的访问之后,它就通知内核关闭这个文件。内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池 中。无论一个进程因为何种原因终止时,内核都会关闭所有打开的文件并释放它们。
2.文件类型
每个 Linux文件都有一个类型(type)来表明它在系统中的角色。
- 普通文件(regular file)包含任意数据。
- 目录(directory)是包含一组链接(link)的文件,其中每个链接都将一个文件名(filename)映射到一个文件,这个文件可能是另一个目录。
- 套接字(socket)是用来与另一个进程进行跨网络通信的文件。
- 命名通道(named pipe)
- 符号链接(symbolic link)
- 字符和块设备(character and block device)
Linux内核将所有文件都组成一个目录层次结构(directory hierarchy)--类似树,由名为/(斜杠)的根目录确定。系统中的每个文件都是根目录的直接或间接的后代。
3.打开和关闭文件的函数
int open(char *filename, int flags,mode_t mode );
返回值:成功则为文件描述符,出错为-1
参数:
- flags 指明进程打算如何访问这个文件
O_RDONLY:只读。
O_WRONLY:只写。
O_RDWR:可读可写。
flags参数也可以是一个或者更多位掩码的或
O_CREAT:如果文件不存在,就创建它的一个截断的(truncated)(空)文件
O_TRUNC:如果文件已经存在,就截断它。
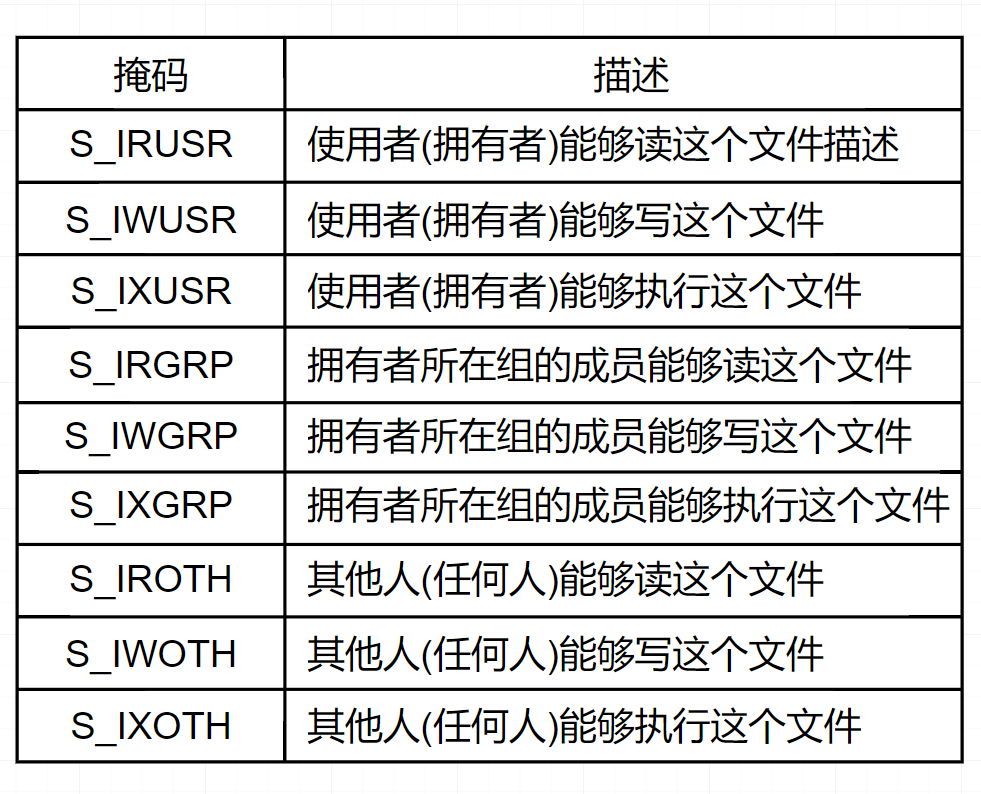
O_APPEND:在每次写操作前,设置文件位置到文件的结尾处。 - mode 指定新文件的访问权限位
![访问权限位]()
int close(int fd)
关闭一个已关闭的描述符会出错。
3.读写文件的函数
ssize_t read(int fd, void *buf,size_t n);
成功则为读的字节数,EOF为0,出错-1
ssize_t write(int fd, const *buf,size_t n);
成功则为写的字节数,出错-1
4.用RIO包健壮地读写
RIO通过反复执行读写操作,直到传送完所有的请求数据,自动处理不足值。
RIO 提供了两类不同的函数:
- 无缓冲的输入输出函数。这些函数直接在内存和文件之间传送数据,没有应用级缓冲。
- 带缓冲的输入函数。这些函数允许你高效地从文件中读取文本行和二进制数据。这些文件的内容缓存在应用级缓冲区内,类似于为 printf 这样的标准I/O函数提供的缓冲区。
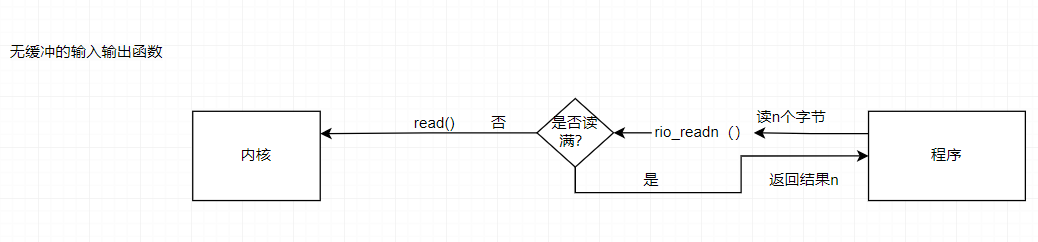
4.1无缓冲的输入输出函数
通过调用 rio readn 和 rio_writen 函数,应用程序可以在内存和文件之间直接传送数据。
ssizet rio_readn(int fd, void *usrbuf, size_t n);
ssize_t rio_writen(int fd, void *usrbuf, size_t n);
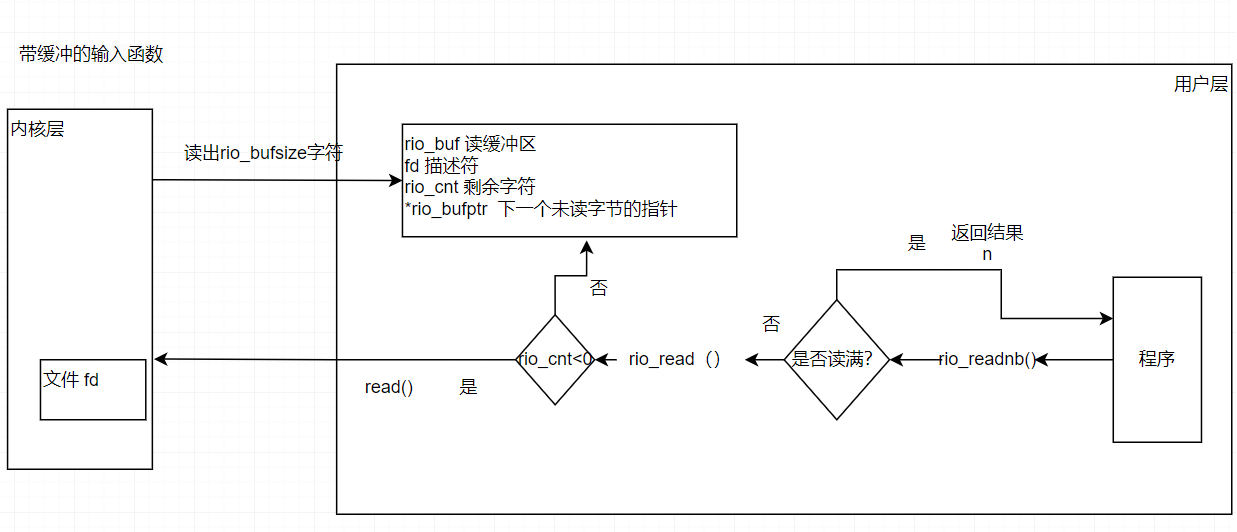
4.2带缓冲的输入函数
void rio_readinitb(rio_t *rp, int fd);
ssize_t rio_readlineb(rio_t *rp,void *usrbuf, size_t maxlen);
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n);
每打开一个描述符,都会调用一次rio_readinitb函数。rio_readinitb函数创建一个空的读缓冲区,并且将描述符fd和地址rp处的一个类型为rio_t的读缓冲区联系起来。
rio_readlineb 函数从文件 rp 读出下一个文本行(包括结尾的换行符),将它复制到内存位置usrbuf,并且用NULL(零)字符来结束这个文本行。rio_readlineb函数最多读 maxlen-1个字节,余下的一个字符留给结尾的NULL字符。超过maxlen-1字节的文行被截断,并用一个 NULL字符结束。
rio_readnb 函数从文件 rp 最多读n个字节到内存位置 usrbuf。
对同一描述符,对 rio_readlineb和rio readnb的调用可以任意交叉进行。然而,对这些带缓冲的函数的用却不应和无缓冲的 rio_readn 函数交叉使用。
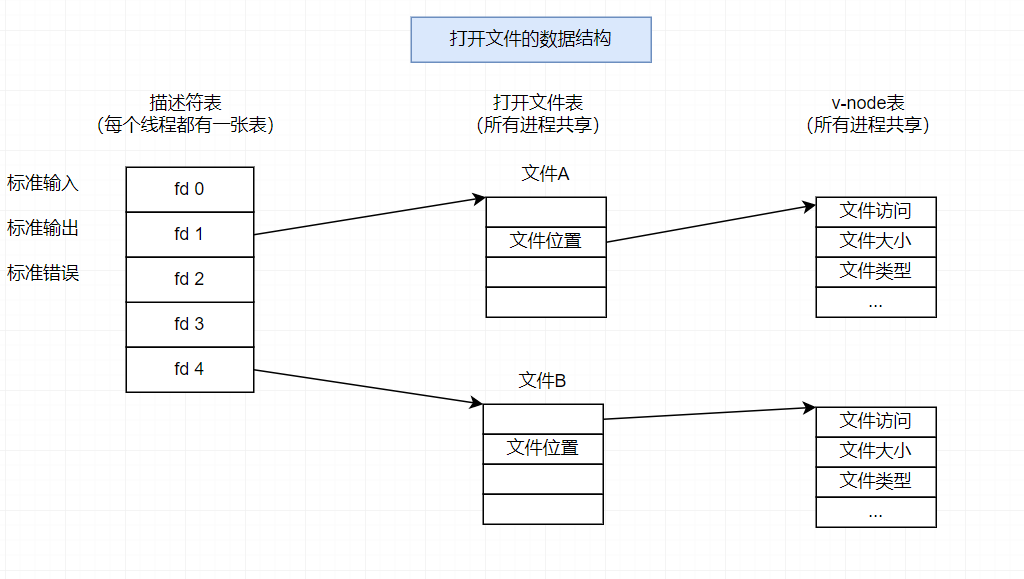
5.共享文件
内核用三个相关的数据结构来表示打开的文件:
- 描述符表(descripior table)。每个进程都有它独立的描述符表,它的表项是由进程打开的文件描述符来索引的。每个打开的描述符表项指向文件表中的一个表项。
- 文件表(file rable)。打开文件的集合是由一张文件表来表示的,所有的进程共享这张表。每个文件表的表项组成(针对我们的目的)包括当前的文件位置、引用计数(reference count)(即当前指向该表项的描述符表项数),以及一个指向vnode表中对应表项的指针。关闭一个描述符会减少相应的文件表表项中的引用计数。内核不会删除这个文件表表项,直到它的引用计数为零。
- v-node 表(v-node table)。同文件表一样,所有的进程共享这张vnode表,每个表项包含 stat 结构中的大多数信息,包括 st mode 和 st_size 成员。
![打开文件的数据结构]()
多个描述符也可以通过不同的文件表表项来引用同一个文件。
每个描述符都有它自己的文件位置,所以对不同描述符的读操作可以从文件的不同位置获取
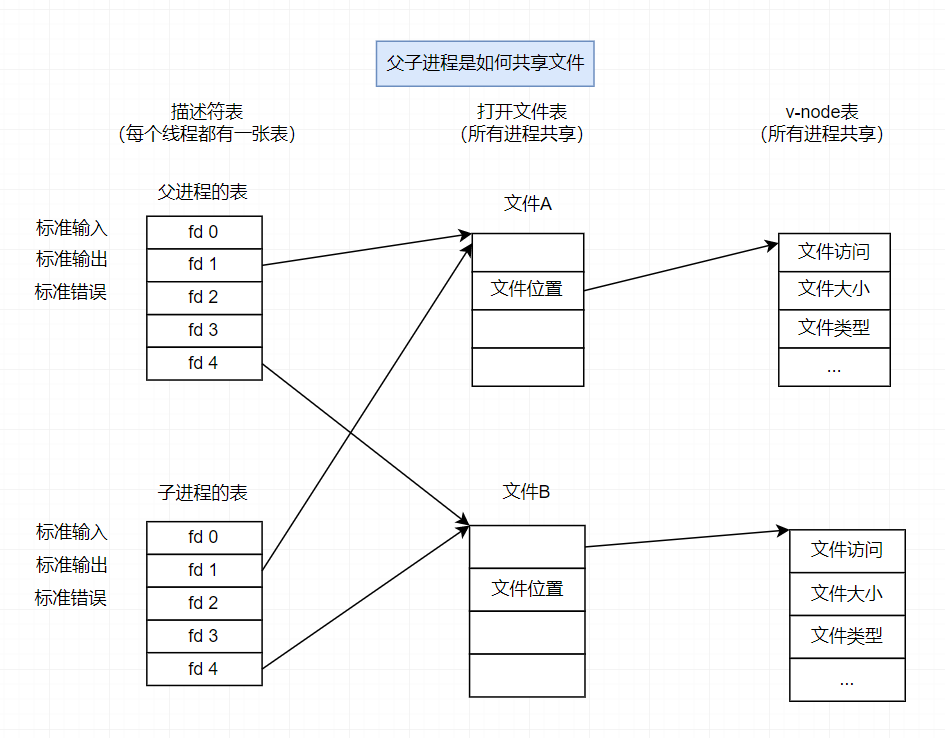
父进程调用 fork后。子进程有一个父进程描述符表的副本。父子进程共享相同的打开文件表集合,因此共享相同的文件位置。一个要重要的结果就是,在内核删除相应文件表表项之前,父子进程必须都关闭了它们的描述符。
6. I/O重定向
Linux shell 提供了 I/O 重定向操作符,允许用户将磁盘文件和标准输人输出联系起来。
只有标准输人输出操作符能重新指定磁盘文件。
int dup2(int oldfd, int newfd);
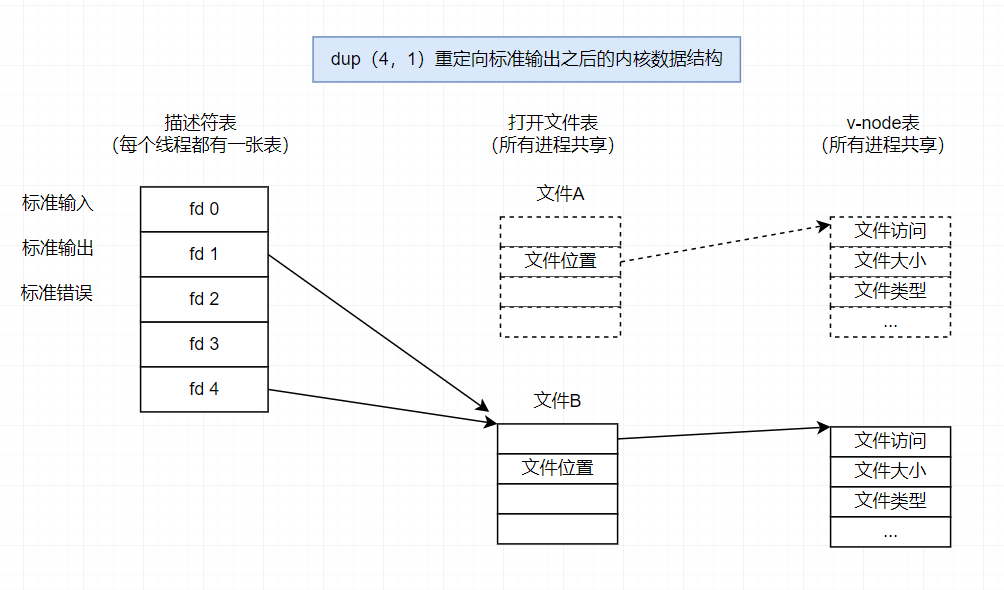
两个描述符现在都指向文件B;文件A已经被关闭了,并且它的文件表和v-node表表项也已经被删除了;文件B的引用计数已经增加了。从此以后,任何写到标准输出的数据都被重定向到文件B。
7. 标准I/O
标准I/O库将一个打开的文件模型化为一个流。对于程序员而言,一个流就是一个指向FILE类型的结构的指针。每个 ANSIC程序开始时都有三个打开的流 stdin、stdout和 stderr,分别对应于标准输入、标准输出和标准错误:
extern FILE *stdin; /* Standard input (descriptor 0) */
extern FILE *stdout; /* Standard output (descriptor 1) */
extern FILE *stderr; /* Standard error (descriptor 2) */
类型为 FILE 的流是对文件描述符和流缓冲区的抽象。流缓冲区的目的和 RIO 读缓冲区的一样:就是使开销较高的LinuxI/O系统调用的数量尽可能得小。
8. 综合:该如何使用I/O函数?
Unix I/O模型是在操作系统内核中实现的。较高级别的 RIO 和标准I/O数都是基于(使用)Unix I/O函数来实现的。RIO 函数是为Unix I/O开发的 read 和 write健壮的包装函数,它们自动处理不足值,并且为读文本行提供一种高效的带缓冲的方法。标准 1/O 函数提供了 Unix I/O 函数的一个更加完整的带缓冲的替代品,包括格式化I/O例程,如printf和 scanf。
基本指导原则:
- 只要有可能就使用标准I/O
- 不要用scanf 或 rio_readlinb来读二进制文件,这样的函数时专门设计来读取文本文件的
- 对网络套接字I/O使用RIO函数。
标准I/O流,从某种意义上而言是全双工的,程序能够在同一个流上执行输人和输出。然而,对流的限制和对套接字的限制,有时候会互相冲突:
- 限制一:跟在输出函数之后的输入函数。如果中间没有插人对 fflush,fseek、 fsetpos或者 rewind 的调用,一个输人函数不能跟随在一个输出函数之后。 fflush 函数清空与流相关的缓冲区。后三个函数使用 Unix I/O lseek函数来重置当前的文件位置。
- 限制二:跟在输入函数之后的输出函数。如果中间没有插人对 fseek、fsetpos或者 rewind 的调用,一个输出函数不能跟随在一个输人函数之后,除非该输人函数遇到了一个文件结束。
这些限制给网络应用带来了一个问题,因为对套接字使用 lseek 函数是非法的。对流I/O的第一个限制能够通过采用在每个输人操作前刷新缓冲区这样的规则来满足。然而,要满足第二个限制的唯一办法是,对同一个打开的套接字描述符打开两个流,一个用来读,一个用来写:
FILE *fpin, *fpout;
fpin = fdopen(sockfd,"r");
fpout = fdopen(sockfd, "w");
但是这种方法也有问题,因为它要求应用程序在两个流上都要调用 fclose,这样才能释放与每个流相关联的内存资源,避免内存泄漏:
fclose(fpin); fclose(fpout);
这些操作中的每一个都试图关闭同一个底层的套接字描述符,所以第二个 close 操作就会失败。对顺序的程序来说,这并不是问题,但是在一个线程化的程序中关闭一个已经关闭了的描述符是会导致灾难的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号