
“消灭”LLM幻觉的利器 - RAG介绍
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网
1 LLM的问题
1.1 幻觉
LLM是预训练模型,已有一些知识储备,我们提的问题跟他的知识储备不相符时,就会产生幻觉,也就是看上去正确的回答。
1.2 新鲜度
LLM预训练后,不能感知到实时更新的业界发展数据,还有企业内部私域数据。
1.3 数据安全
LLM训练依赖很多训练数据集,为保证LLM效果更好,训练集质量及数据量越多,对LLM训练最终效果更好,但又期望LLM帮解决一些垂类问题,又希望在数据安全有些防范,如企业内部敏感数据不能暴露,让公有LLM去进行训练。
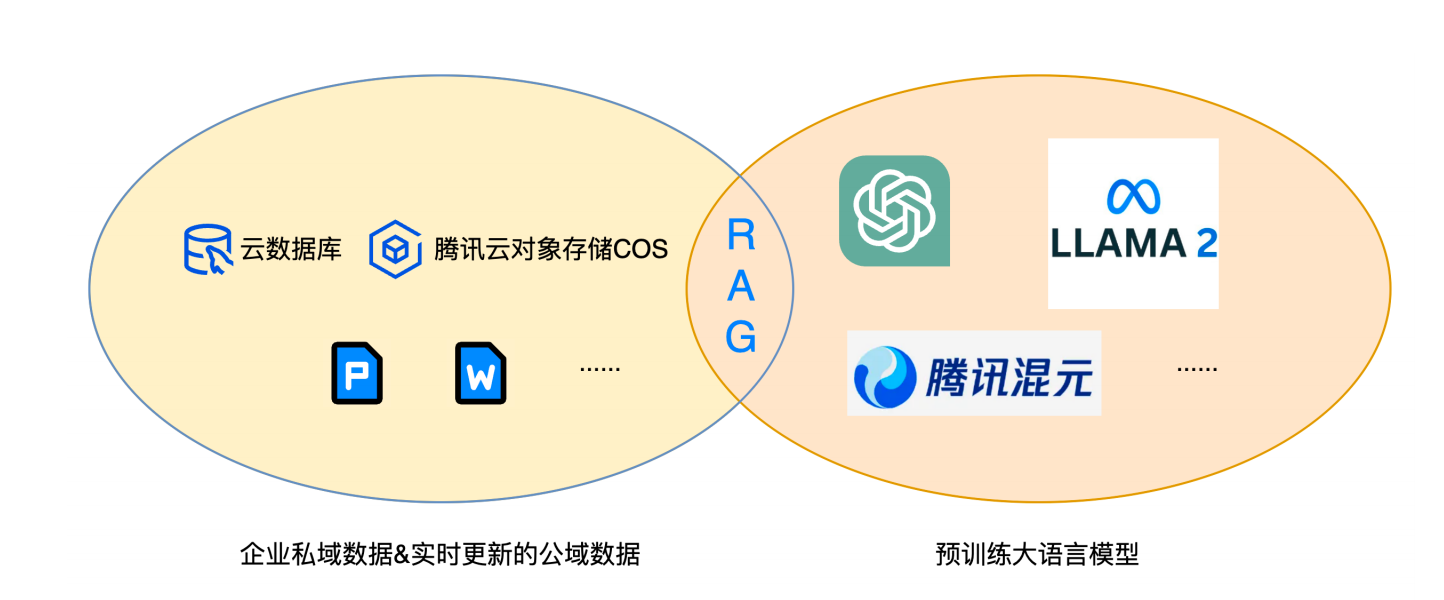
2 RAG是啥?
为解决LLM刚提到问题,提出RAG,将企业内部私域数据及实时更新的一些公域数据,通过一些处理后,变成可进行相似性搜索的向量数据,然后存储到向量数据库。
和LLM交互时,用户提问。先在我们的相同数据库中进行相似性检索,检索与提问相关的知识内容,检索后交给LLM,连同用户的提问一起让 LLM 去生成回复。
RAG帮助我们个人及用户去把企业内部的一些知识数据,很快构建出一个庞大知识库,然后结合目前已有LLM能力,可快速制作智能问答机器人应用。
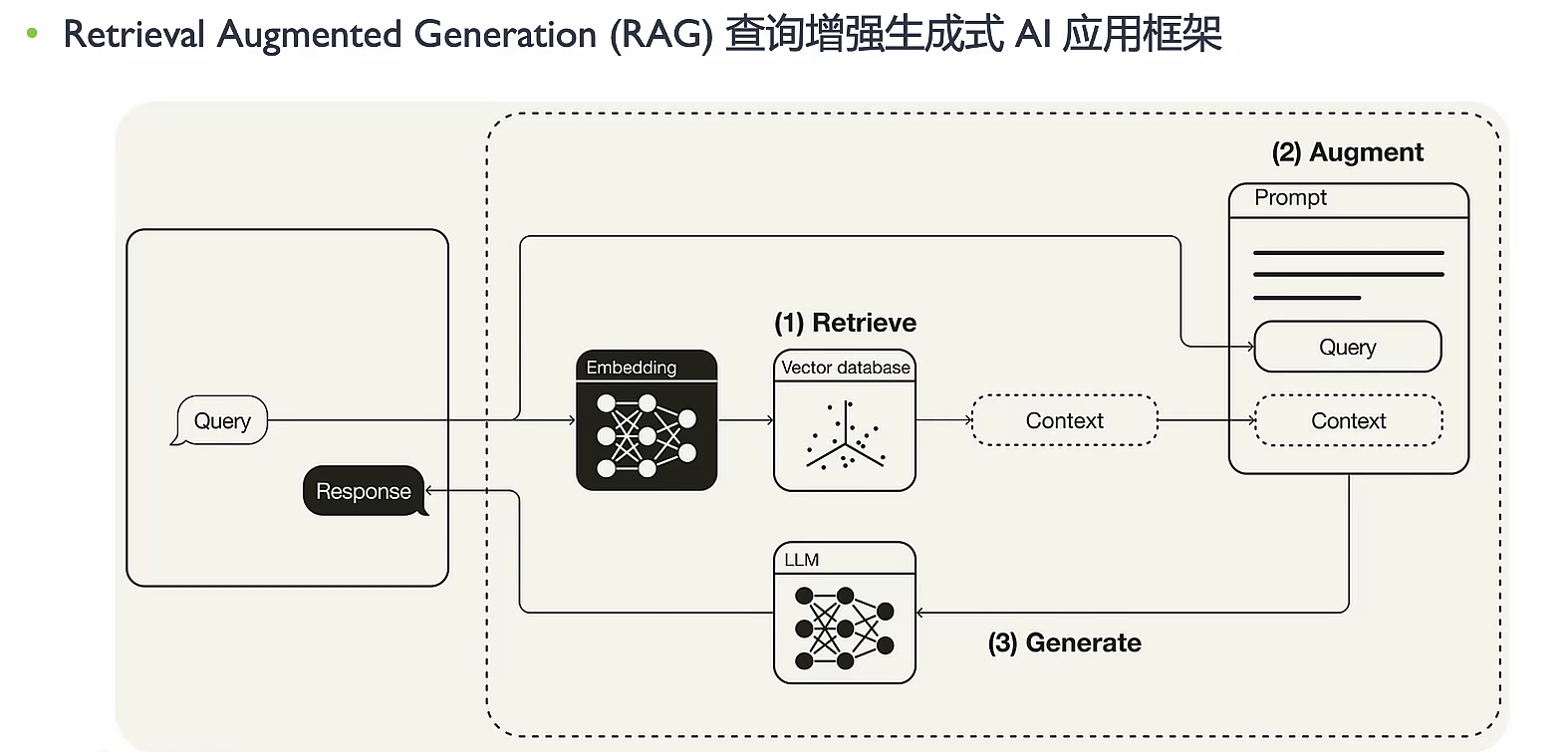
小结
为LLM提供来自外部知识源的额外信息的概念。这允许它们生成更准确和有上下文的答案,同时减少幻觉
- 检索:外部相似搜索
- 增强:提示词更新
- 生成:更详细的提示词输入LLM
3 RAG应用咋构建?
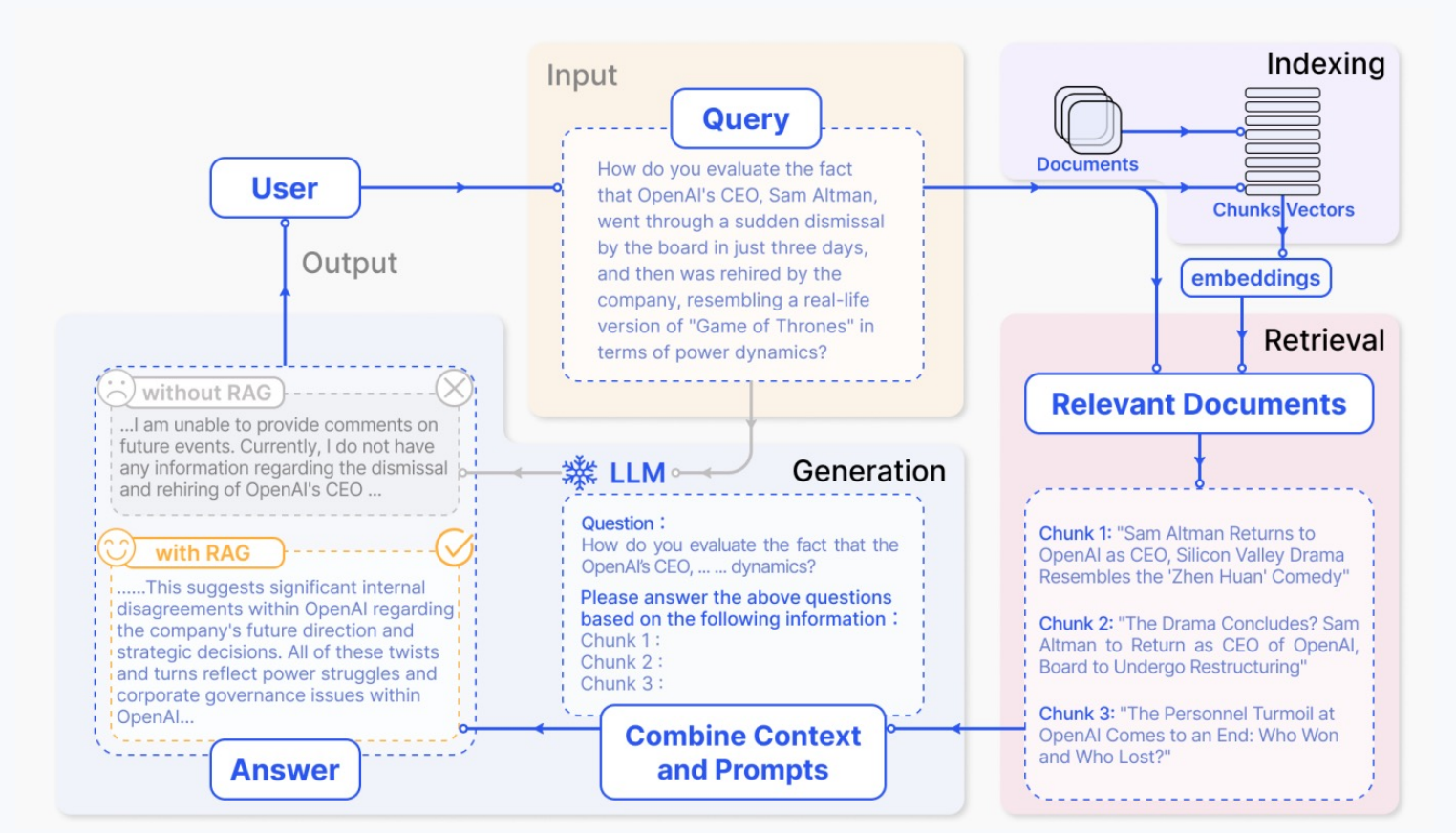
3.1 无RAG的传统AI问答
就像这样:
public class TraditionalAI {
private StaticKnowledge knowledgeBase; // 训练时固化的知识
public String answer(String question) {
// 只能基于内置知识回答
return knowledgeBase.search(question);
}
}
就像一个只依赖内存的Java应用:
- AI模型就像一个巨大的静态数据结构,所有知识都"硬编码"在模型参数中
- 当用户问问题时,AI只能基于训练时学到的知识回答
- 图中显示:对于OpenAI CEO的问题,没有RAG的系统回答"我无法提供评论...目前我没有关于CEO解雇和重新雇佣的信息"
// 类比:没有RAG就像这样
public class TraditionalAI {
private StaticKnowledge knowledgeBase; // 训练时固化的知识
public String answer(String question) {
// 只能基于内置知识回答
return knowledgeBase.search(question);
}
}
3.2 有RAG的知识库问答系统
RAG步骤:
-
知识切片成Chunk
-
向量化Chunk入库
前两步都是去知识库生成。
-
Query检索知识Chunk
-
构建Prompts
-
调用LLM生成回答
后三步都是知识库生成后,在检索方面需要做的。
就像一个连接了实时数据库的Java应用:
① 索引阶段(Indexing)
// 类比:文档预处理和索引
public class DocumentIndexer {
public void indexDocuments(List<Document> docs) {
for (Document doc : docs) {
// 1. 切分文档为chunks
List<String> chunks = splitIntoChunks(doc);
// 2. 生成向量embeddings
for (String chunk : chunks) {
Vector embedding = embeddingModel.encode(chunk);
vectorDB.store(chunk, embedding);
}
}
}
}
② 检索阶段(Retrieval)
public class RAGSystem {
private VectorDatabase vectorDB;
private LLM llm;
public String answer(String question) {
// 1. 将问题转换为向量
Vector questionVector = embeddingModel.encode(question);
// 2. 从向量数据库检索相关文档
List<String> relevantChunks = vectorDB.similaritySearch(
questionVector, topK = 3
);
// 3. 结合检索到的信息和问题生成答案
String context = String.join("\n", relevantChunks);
String prompt = buildPrompt(question, context);
return llm.generate(prompt);
}
}
3.3 关键技术差异
向量化检索
// RAG的核心:语义相似性搜索
public List<String> findRelevantInfo(String query) {
Vector queryVector = embeddingModel.encode(query);
// 不是关键词匹配,而是语义相似度
return vectorDB.cosineSearch(queryVector, threshold = 0.8);
}
动态上下文注入
public String generateAnswer(String question, List<String> context) {
String prompt = String.format(
"基于以下信息回答问题:\n%s\n\n问题:%s",
String.join("\n", context),
question
);
return llm.complete(prompt);
}
3.4 效果对比
没有RAG:
- ❌ 无法回答训练数据之后的新信息
- ❌ 知识更新需要重新训练模型
- ❌ 无法处理私有/企业内部数据
有RAG:
- ✅ 能够回答基于最新文档的问题
- ✅ 图中显示:系统检索到相关的OpenAI新闻chunks,生成了详细分析
- ✅ 可以随时更新知识库而不需要重训模型
- ✅ 支持企业私有数据查询
简单类比:
- 没有RAG = 一个只能背书本的学生
- 有RAG = 一个可以随时查阅图书馆和互联网的学生
这就是为什么RAG成为企业AI应用的主流架构 - 它让AI能够访问和利用实时、私有的数据源。
- 使用RAG链路后,用户先去构建好的知识库,即向量数据库里进行相似性检索,再带出一部分知识文档。这部分知识文档会跟用户的query结合
- 再通过prompt技术组装成一个最终完成的一个输入给到LLM,让LLM回复
最关键就是知识库生成这步,主要涉及把知识文档去做内容提取及拆分。还要进行量化,入库。
4 基于Langchain构建 RAG 应用
4.1 Langchain中RAG实现
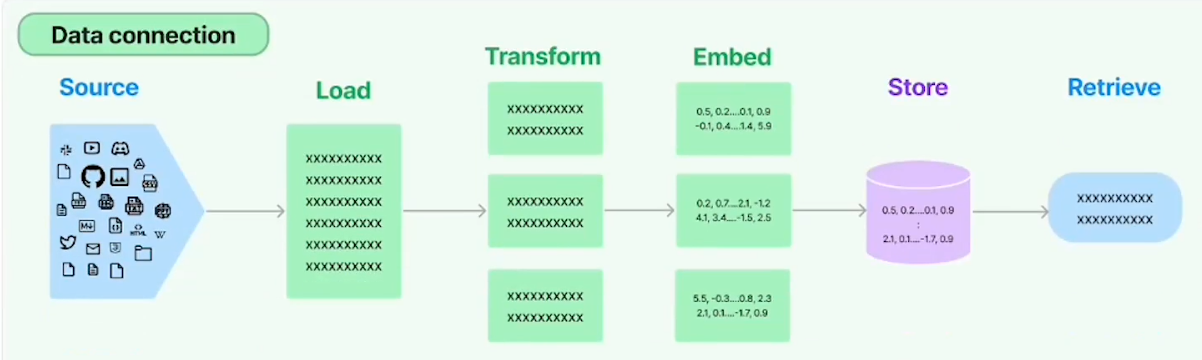
各种文档 - 各种 loader - 文本切片 - 嵌入向量化 - 向量存储 - 各种检索链。
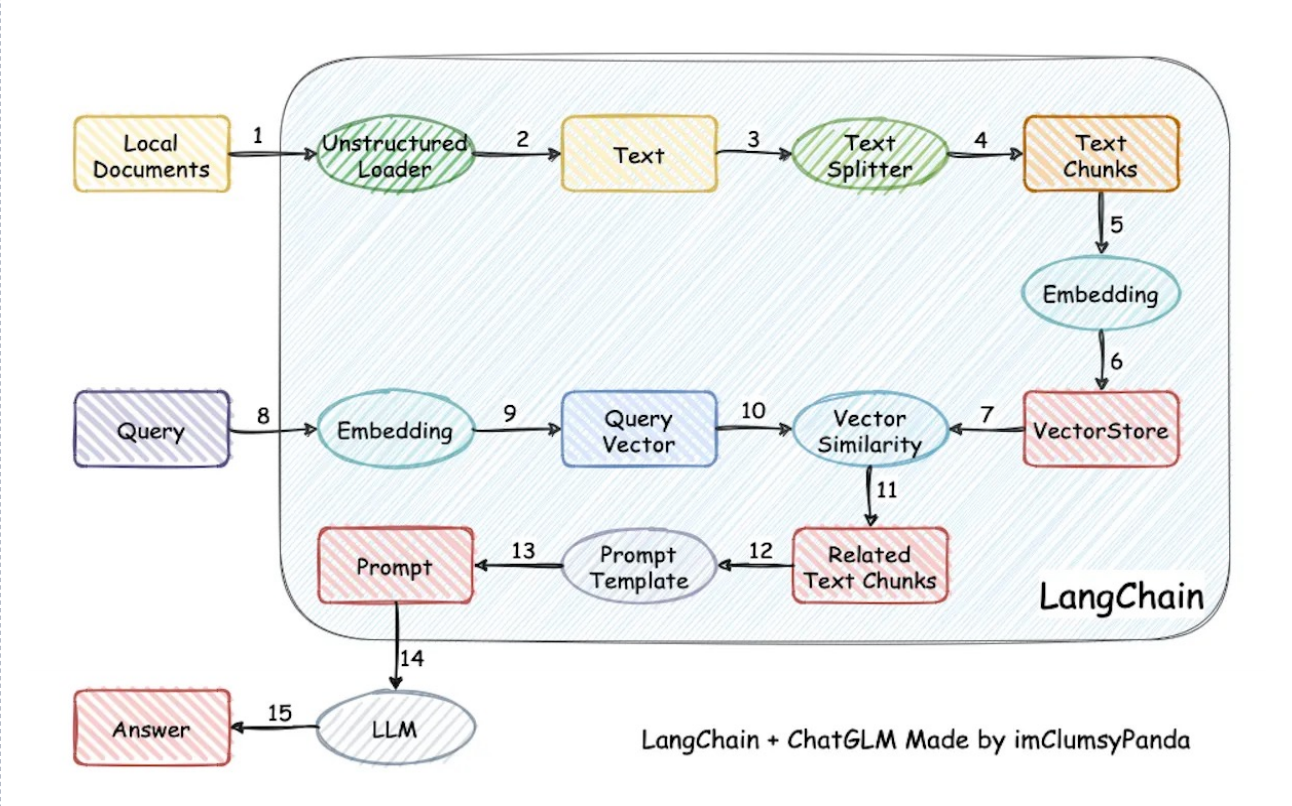
4.2 设计思想
RAG五步拆成不同组件,再由不同节点处理。让用户去编写业务逻辑代码,再把这整个过程串起。
4.3 优势
- 可快速构建一个demo,助开发者理解RAG应用
- 庞大社区支持,如一些插件或它的一个版本更新迭代都很快
4.4 痛点
本质上通用性很强。为保证强通用性,效果层面不一定做到最好,需企业或个人投入较大精力,把整体的RAG在召回层的效果提升到最佳。
5 bad case
构建整个RAG应用过程中会遇到的问题解决方案。
5.1 拒答
用户提问:请问A产品分析报告多久分析一次?
召回的相关知识:A产品的分析报告信息近30天的数据分析结果。
因为用户的问题,在相关知识没明确提到,只是有一定相似度,但跟我们用户问题不直接相关。这样的相关知识及用户问题,组装后交给LLM回答,本质上是人为制造干扰。
对此,有个工程化实践叫拒答。
5.2 消歧
提问:A课程适合多大年龄小孩。
知识库召回两条数据:
- 其中一条是期望的一个知识,就在A课程文档,有一段话跟提问相关
- 但还会召回其他的一个干扰知识。如其他文档里一些内容,像该课程适合3到7岁的小孩,适合6到8岁的女孩。这种知识内容也会被召回
期望的召回内容携带一部分干扰信息,这干扰信息没有A课程这关键字,然后也不会召回。在这两个知识内容交给大源模型处理,他也无法理解哪个字内容正确。
更希望在召回层,就有较好手段处理。工程化实践里,会对用户提问进行改写,增强query的一个效果。
也用到类似BM25这种倒排索引,提升关键字的权重。如干扰知识里没生成这个关键字,其相似度分数较低,就不会召回。
5.3 分类
可能有用户的提问类似:服务器连接不上,应当如何解决?
现在给知识库里面注入的文档,都是类似连接服务器应该有哪些步骤。
将这些知识内容召回,交给LLM也能引导用户。但不能直切要害,用户更希望,我现在连接不上,有啥排查手段。更好的还是通过提供一些专门QA文档,增强整个知识召回内容准确性。
用户可能问一些跟他实例相关的问题。如CPU占用变高或内存变高,实际响应可能是技术支持文档里的一些处理方案,就是我现在内存变更咋处理。但用户想知道为啥变高。有一个意图识别模型,判断用户他想要的问题具体是一个什么类的,需不需要用到RAG,也会判断他是否需要用到诊断引擎。类似问题2,需要用到诊断引擎,那我们会调用其他RAG无关的诊断相关技术为用户排查问题,并且给用户反馈一个结果。
6 咋提升RAG应用效果?
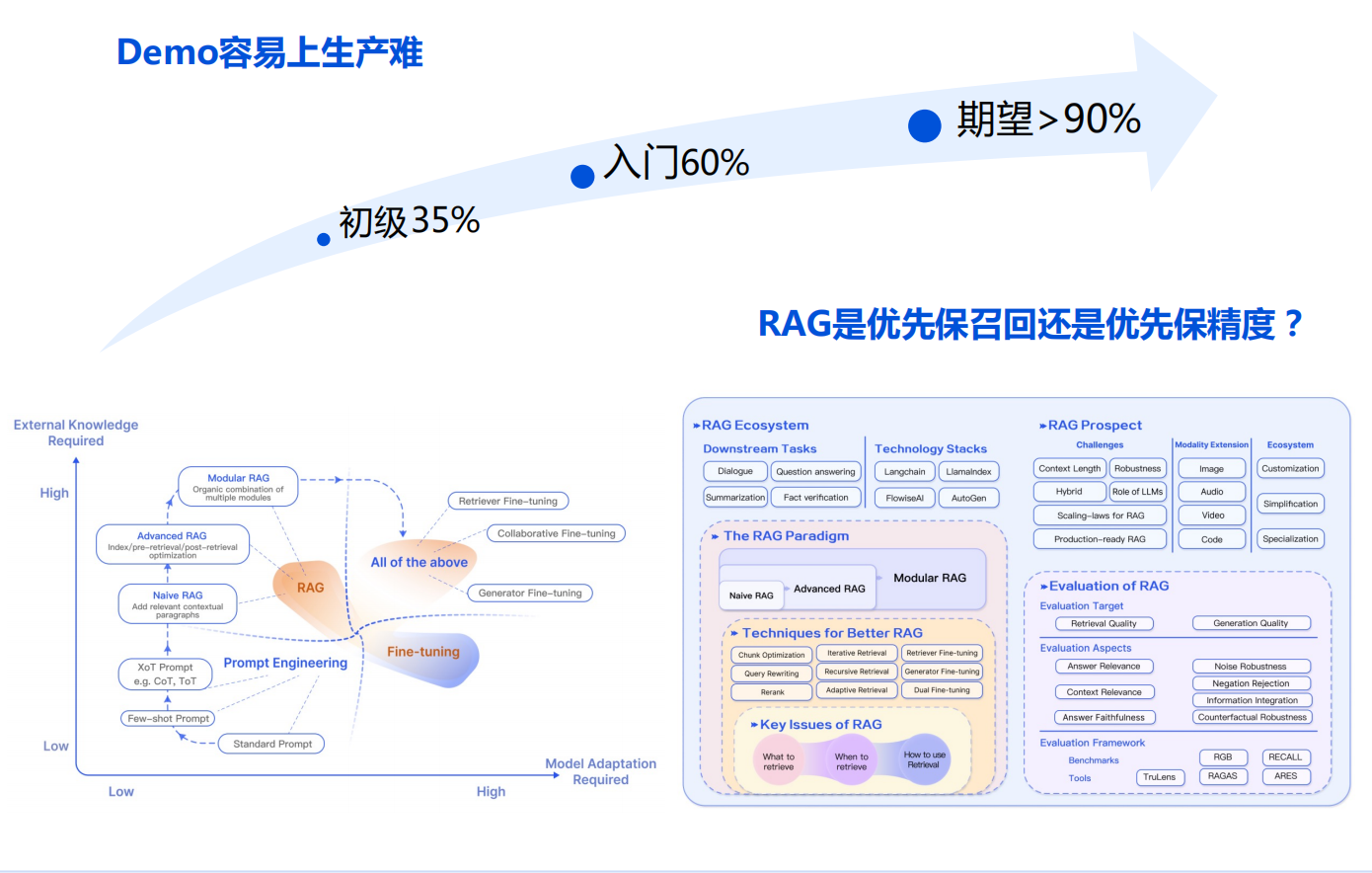
demo易,但上手难,主要因为LangChain、LLamIndex框架盛行。很快接入就是初级的一个状态,可能只做到35%。
想提高整体准确率,在拆分那儿会拆更合理、提取内容时,把整个内容提取更好。做向量化时,去选择我们的向量,更好的一个embedding模型。
最终跟LLM交流时,选择效果更好的LLM,把这效果提升到更高。
但60%的准确率还是达不到生产期望。希望准确率90%,在RAG应用构建各阶段,都有很多工程化手段。
目前RAG整体应用在界内的比较关注的一个地方就是在召回。因为涉及知识文档,思考方向:
- 优先保证召回率
- 优先保证精度
RAG召回是希望获得更多和用户提问相关的知识内容,还是只需更关键的知识内容排在最顶。某云厂商相关数据库AI套件选择前路,期望召回更多跟用户相关的提问的内容。
精度尽量保证召回内容在top3、top5位置出现,因为召回的一些内容确实有一部分干扰信息。但目前LLM能力尚可,对这种干扰性信息的排除能力较好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号