集合-续
Set接口
来自java.util是和List一样属于Collection的子接口,
方法都是来自Collection
Set集合中的对象不会记录顺序只是简单的把元素添加进集合
因此它不能添加重复元素,它的比较流程如下
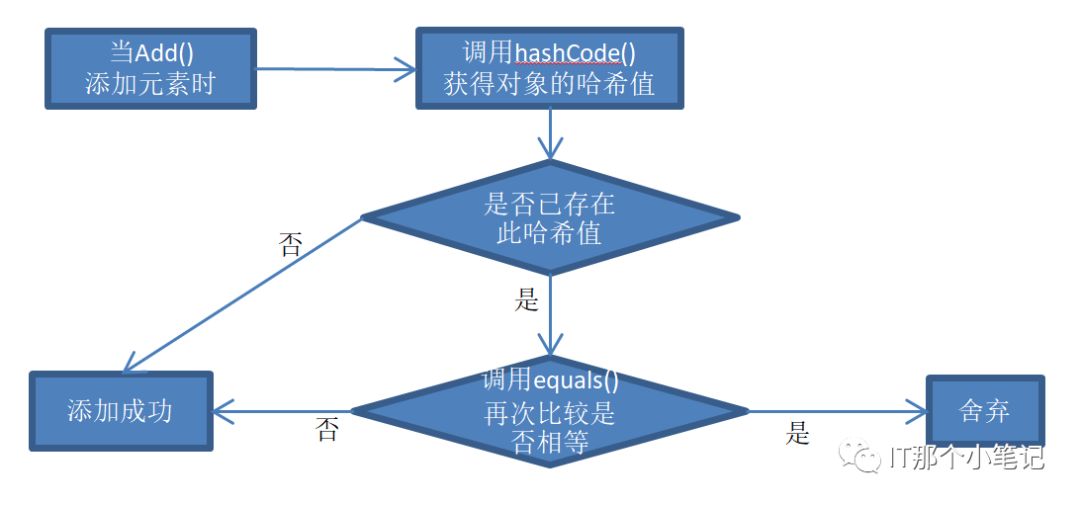
因此在添加自定义对象想达到想要的去重效果就要重写HashCode()与equals()方法
原HashCode()方法定义在Object,每次创建对象都会带有一个hash值,对应内存地址的一个编号。因此不同的对象的都不一样,我们在添加一个自定义对象去重时就需要在添加同一个类型对象时,去比较属性是不是一样来决定是否加进去。也就需要将hashCode()重写为是一个类型就是返回相同的值,再用equals来比较内容,不是一个类型就不用比较内容了直接添加。
class Animal{String name;Animal(String name){this.name = name;}@Overridepublic String toString() {// 重写toString打印内容return "Animal [name=" + name + "]";}@Overridepublic int hashCode() {// 判断是否是一类型final int prime = 31;int result = 1;result = prime * result + ((name == null) ? 0 : name.hashCode());return result;}@Overridepublic boolean equals(Object obj) {// 重写equals()比较内容是否相等if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;Animal other = (Animal) obj;if (name == null) {if (other.name != null)return false;} else if (!name.equals(other.name))return false;return true;}}class test{String name;// 定义个和Animal相同的字段test(String name){this.name = name;}public static void main(String[] args) {Set s = new HashSet();s.add(new Animal("狗"));s.add(new Animal("猫"));s.add(new Animal("狗"));s.add(new test("狗"));System.out.println(s);}}// 结果就验证了上图的流程,添加上了三个元素。结果:[], first.a.test@15db9742, Animal [name=猫]]
HashSet类
Set接口的实现类,也没有什么特有方法
它的子类LinkedHashSet是链表结构所以是逻辑有序的每个元素的后继是对应添加时的顺序
下面做两个小练习
小练习1:生成10个100以内不重复的随机数
小练习2:去重(对键盘输入的字符)
import java.util.HashSet;import java.util.Random;class test{public static void main(String[] args) {Random r = new Random();HashSet<Integer> h = new HashSet<Integer>();for(int i=0; i<10;i++) {h.add(r.nextInt(100));}System.out.println(h);}}[]
import java.util.HashSet;import java.util.Scanner;class test{public static void main(String[] args) {Scanner sc = new Scanner(System.in);String sr = sc.nextLine();HashSet<Character> h = new HashSet<Character>();for(int i = 0; i<sr.length(); i++) {h.add(sr.charAt(i));// 遍历添加字符串}System.out.println(h);}}输入: sdadaq3dada结果: [a, q, s, 3, d]
TreeSet类
Set接口的实现类
import java.util.TreeSet;class test{public static void main(String[] args) {TreeSet t =new TreeSet();t.add("f");t.add("a");t.add("3");t.add("1");t.add("b");System.out.println(t);TreeSet t1 = new TreeSet();t1.add(2);t1.add(8);t1.add(4);t1.add(1);System.out.println(t1);}}/*上面代码中添加的一个是Character,一个是Integer,它们这两个类也是实现接口并且重写了CompareTo()才可以被添加*/结果:[][]
它会对添加到里面的元素进行排序通过类的比较方法
所以就算没有指明泛型也只能添加一种类型。
这样才能比较,不然运行报错
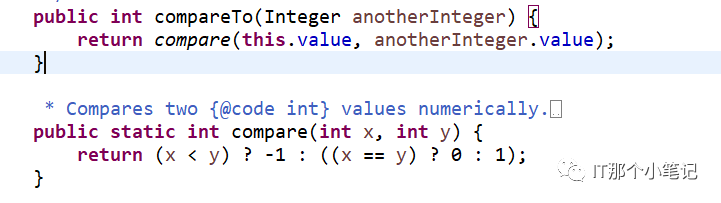
添加的元素都是保证同一种类型,比较时会调用重写的CompareTo()方法
所以要添加进TreeSet的类型,此类就必须得实现Comparable并且重写CompareTo()方法
或者单独定义一个类实现Comparator做比较器,在创建TreeSet集合时将比较器对象传入构造器中。
排序是以二叉树的形式,compareTo会有int类型的返回值如果是正数表示大放右边,负就表示小放左边,如果是0则相同不能添加成功。最后以中序遍历得到顺序
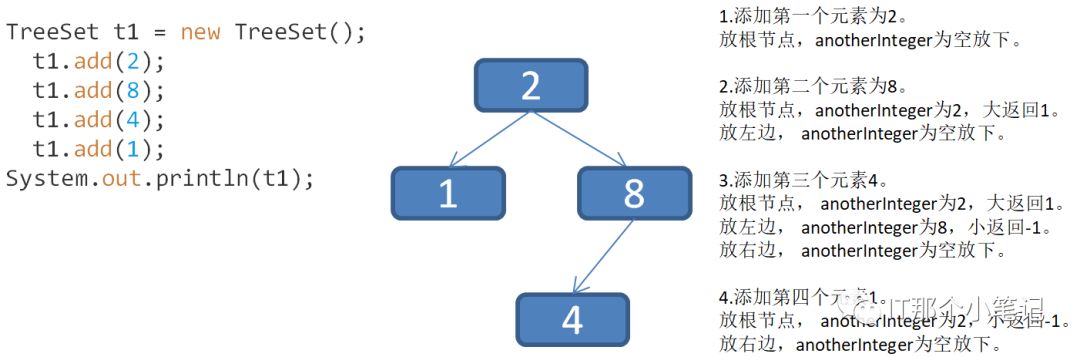
知道怎么排之后现在就来做一个自定义的类完成添加到TreeSet当中
定义一个人类按照年龄排序
import java.util.TreeSet;class Person implements Comparable<Person>{String name ;int age;public Person(String name,int age) {this.age = age;this.name = name;}public String toString() {return "Person [name=" + name + ", age=" + age + "]";}public int compareTo(Person another) {// TODO Auto-generated method stubif(this.age>another.age) {// 大于则返回正,放右return 1;}else if(this.age<another.age) {// 小则返回负,放左return -1;}else {// 相同时并不想只是因为年龄相同就返回0添加不上if(this.name.equals(another.name)) {//就再进行判断如果名字也相同才是我们不想让他添加上的return 0;}else{// 仅仅只是年龄相同的return 1;}}}}class test{public static void main(String[] args) {TreeSet<Person> t = new TreeSet<Person>();t.add(new Person("张三", 15));t.add(new Person("李四", 17));t.add(new Person("王五", 24));t.add(new Person("马六", 13));t.add(new Person("张三", 15));System.out.println(t);}}结果:[Person [name=马六, age=13], Person [name=张三, age=15], Person [name=李四, age=17], Person [name=王五, age=24]]
Map集合
Map集合没有继承Collection接口,它提供的时key到value的映射。一个Map中不能包含相同的key,一个key只能有一个value与之对应。key还决定了存储对象在映射中的存储位置,但并不是由key对象本身决定的,而是通过一种“散列技术”进行处理,产生一个散列码的整数值来确定存储对象在映射中的存储位置
常用方法试例:
import java.util.HashMap;import java.util.Map;class test{public static void main(String[] args) {Map<String, Integer> m = new HashMap<>();m.put("第一个", 1);// 添加元素m.put("第二个", 2);m.put("第三个", 3);m.put("第四个", 4);m.put("第一个",6);// 修改System.out.println(m);System.out.println(m.containsKey("第一个"));// 是否有key叫“第一个”System.out.println(m.containsValue(3));// 是否有为3的valueSystem.out.println(m.get("第一个"));// 得到指定key的valueSystem.out.println(m.keySet());// 得到key的集合System.out.println(m.values());// 得到value的集合System.out.println(m.size());// 元素的数量m.remove("第三个");// 移除指定key的元素System.out.println(m);}}结果:{第二个=2, 第四个=4, 第三个=3, 第一个=6}truetrue6[第二个, 第四个, 第三个, 第一个][2, 4, 3, 6]4{第二个=2, 第四个=4, 第一个=6}
它的实现类HashMap,TreeMap等的使用和HashSet,TreeSet一样,怎样去重怎样排序怎样遍历等等
本文分享自微信公众号 - IT那个小笔记(qq1839646816)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号