LeetCode初级算法之数学问题:204 计数质数
题目信息
题目地址:https://leetcode-cn.com/problems/count-primes/
统计所有小于非负整数 n 的质数的数量。
示例1:
输入:n = 10
输出:4
解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
示例2:
输入:n = 0
输出:0
示例3:
输入:n = 1
输出:0
解法一:暴力枚举
依题意需要统计0至n当中质数的个数,自然的就想的到去遍历0至n的每个数字,再判段每个数字是否是质数,如果是计数加一如果不是则不变,最终返回计数结果。
对于判断是否是质数,我们都知道是有且只能被自己与1整除的数是质数(1不算),那么判断7是不是质数需要判断它能否被2至6里面的数整除么,其实不需要因为一个数不可能整除大于自己一半的数。也就是说判断数字number是否为质数看看2到number/2之间的整数能不能进行整除即可
了解之后我们先定义一个判断是否是质数的judge方法:
public boolean judge(int number){
// 遍历2到number/2之间的数字,看是否能被number整除
for(int i = 2; i<=number/2; i++){
if(number%i==0) return false;
}
return true;
}
有了judge方法之后,再配合遍历计数,得到结果:
public int countPrimes(int n) {
// 计数器初始化0
int result = 0;
for (int i = 2; i < n; i++){
// 如果judge判断是质数则计数器加一,否则不变
result = judge(i) ? ++result : result;
}
return result;
}
空间: 一个计数器变量,因此复杂度O(1),
时间: 需要遍历0-n的每个数,而每个数进行判断是不是质数又需要遍历0-i/2,复杂度是O(n^2)
提交结果:

image-20210706214113699
可以看的到大部分测试用例通过,证明求解结果是没有问题的。但在面对499979这样的大数字计算次数过多导致超时,因此还需看看怎么优化时间复杂度。
其实可以发现判定一个数number是否可以被2到number-1的里面的数整除,我下意识想的是可以减少一半的规模只用判断2到number/2即可。
但其实可以更缩小规模
12 = 2 * 6
12 = 3 * 4
比如像这个12,没必要除到6,6与2是重复的。一个数除以一个数得到一个整数number/x = y,那么它的两个因数x * y是一大一小,我们只需要把小的一边都除以一下判断是否可以整除即可。也就是开根号。
像判断23是否是质数,判断2到4.79....
也就是只需要判断对2、3、4是否能整除即可,而不是像之前要从2到11。
public Boolean judge(int number){
// 边界条件0和1直接返回
if(number == 0 || number == 1) return false;
// 遍历2到根号number之间的数字,看是否能被number整除
for (int i = 2; i*i<=number; i++){
if(number%i==0) return false;
}
return true;
}
修改i <= number/2 为 i * i <=number,时间复杂度降低一个根号:O(nlogn),结果依然还是不够,仍然会超时。
解法二:厄拉多塞筛法
解法一的时候我们是通过两个遍历求解问题:一是遍历每个数字拿去进行判断,二是当前数字判断它是否是质数的过程需要遍历数字范围内的数进行除运算,时间复杂度很高,好在判断它是否是质数时我们从2到number-1的数字里面缩小了一半(平方)的范围。
尽管如此但仍然不够,判断质数的过程已经是最优化了。那么能优化的只能是第一个步骤也就是遍历每个数字拿去判断。
- 是否可以不需要每个都遍历去判断?
- 在连续的数字里面质数出现是否有规律?
- 是否这个数是质数的话那么谁谁谁都是质数?也就不需要都拿去判断了
当时在纸上画了一些,没太找到什么规律可以帮助我解决这个,在网上看了这个厄拉多塞筛法加上数组进行应用确实很妙。
就是说一个质数的倍数它一定不是质数,比如x是质数但2x、3x、4x这些肯定不是质数,2x起码可以整除2、3x起码可以整除3。

但确实没想到来解决这个问题。主要的点是当我们从质数2开始一个一个遍历的时候,遍历的速度不会超过排除的速度,因此可以认为遍历到的当前数字没有被排除的话就是质数。下面手动枚举几个就可以看出:
2 3 4 5 6 7 8 9
比如现在找2-9的质数:
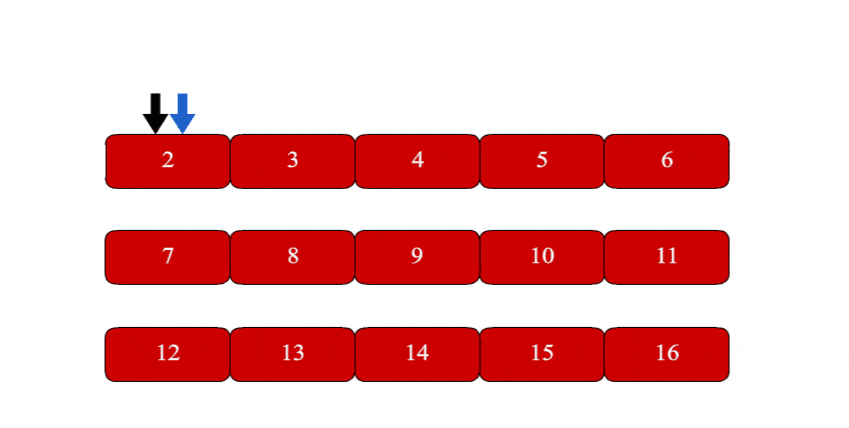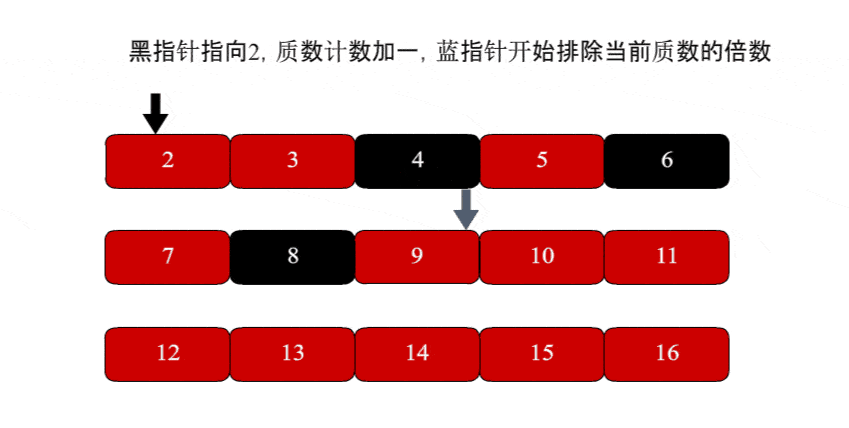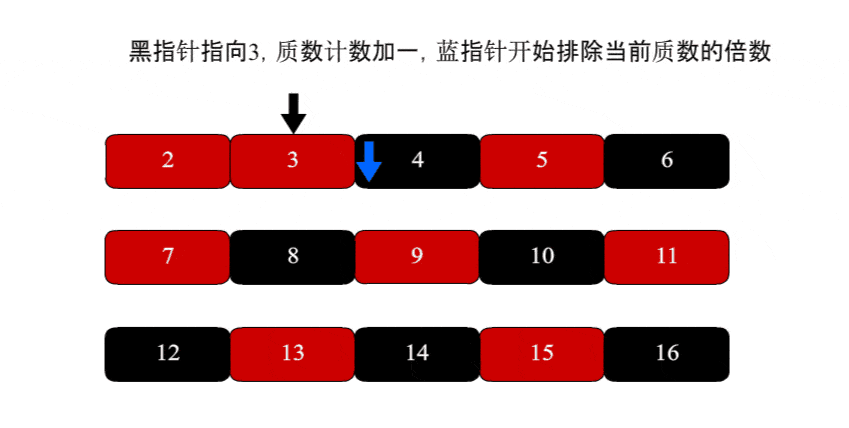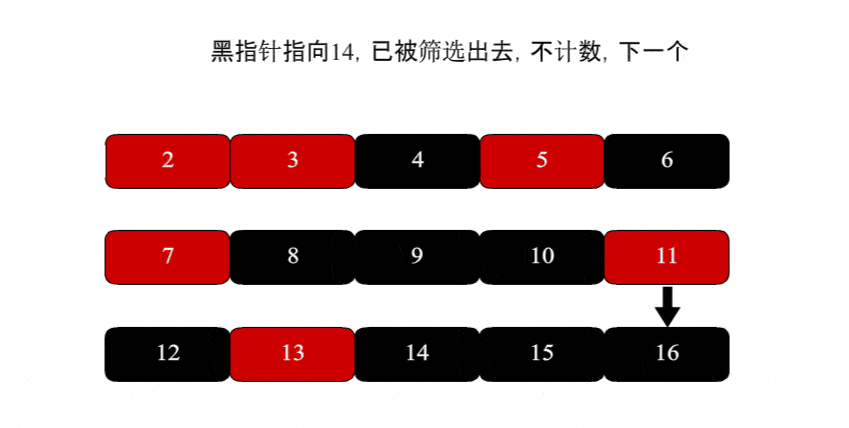
从质数2开始,质数计数加一,并排除4、6、8不是质数。
遍历到3质数,质数计数加一,并排除6、9不是质数。
遍历到4,发现已被排除
遍历到5质数,质数计数加一
遍历到6,发现已被排除
遍历到7质数,质数计数加一
遍历到8,发现已被排除
遍历到9,发现已被排除
最终质数计数结果是4
还能看出有一点是需要优化的,每个数从它的两倍开始排除:2倍、3倍、4倍等等。可以发现2排除的数,3也排除了。也就是有些数在前面已经排除了,这边在做排除的时候不应该再去做多余的步骤,这就是优化的点。想想可以知道,3从2倍数走起。肯定在之前就被2的3倍走了。要不重复只能从比自己大的倍数走起,前面的早就被其他小的数字已经排除了。所以就像质数5再去排除不应该去排除2ⅹ5和3ⅹ5,因为它们早就被之前的数排除了。我们排除应该从自己的平方开始。
这里还是画个动图:
实现上其实就是两个循环,一个是遍历每个数字,另一个是对每个数字进行加一倍把得到的数字排除。数据结构上使用字节数组进行标记,是质数标0,被排除就改为1
public int countPrimes(int n) {
// 计数器初始化0
int result = 0;
/**
* 定义数组,标记数字是否被排除
* 小于n的数字再排除0和1,共有n-1个需要判断
* 初始化数组默认都是0,等待从2开始的一次次标记
*/
int[] arr = new int[n];
// 遍历每个数
for (int i = 2; i < n; i++){
// 是质数,进行倍数排除,从平方开始
if(arr[i] == 0){
result++;
for(int j = i * i; j < n; j+=i){
arr[j] = 1;
}
}
}
return result;
}
这样就ok,测试一下发现居然在n=499979的时候出现数组越界:

image-20210721155707622
看程序没看出问题,毕竟 j < n才能取 arr[ j ],后来注意到越界的索引是 -2146737495 。是两个int的乘积超过了int也就是j类型的范围,j拿到一个负值进入循环。所以在得到 j 的时候给它升下级给个long类型,确认小于n之后,取值时再强转为int
这边顺便做一个空间优化,也就是数组只存 0或1,所以用空间小的byte数组来存
代码如下:
public int countPrimes(int n) {
int result = 0;
byte[] arr = new byte[n];
for (int i = 2; i < n; i++){
if(arr[i] == 0){
result++;
for(long j = (long)i * i; j < n; j+=i){
arr[(int)j] = 1;
}
}
}
return result;
}
虽然是两次循环,但实际在内循环处理的数在外循环就没有了,对于时间复杂度来应该是个多少倍的n
对于空间来说使用了字节数组,占用n个字节。复杂度O(n)
测试结果

image-20210721160944543
解法三:线性筛选法
在处理前面的埃氏筛选法也就是厄拉多的时候,其实就有疑问?我们通过筛选质数的平方之后的倍数得到的合数来避免前面的重复剔除
排除质数x构成的合数
x * x
x * ( x + 1 )
x * ( x + 2 )
x * ( x + 3 )
....
虽然它是避免了像2排除6,3也排除6的情况。因为3直接从9,12,15开始排除。但12仍然是既被2排除也被3排除。
解决了平方数之前数字的剔除重复,但之后的数字还是会有冲突会有重复剔除。
现在就想让每个合数被自己的很多对因数当中其中最小的因数给排除掉,别再被其他因数排除
| 合数 | 因数 |
|---|---|
| 4 | 2 |
| 6 | 2、3 |
| 8 | 2、4 |
| 9 | 3 |
| 10 | 2、5 |
| 12 | 2、3、4、6 |
采用线性筛选将每个数都参与排除,每次排除目前最近且和未来不冲突。它的要点是任何的合数它的一个最小因数一定是一个质数,因此将质数取出来对每个数进行乘积来进行排除。那么如何避免重复剔除呢?
下面列举一些:
2 排除 4
3 排除 6、9
4 排除 8 (4由2排除,因此它的3倍5倍都是应该被2解决)
5 排除 10、15、25
6 排除 12(6可以被2排除,不需要解除其他倍)
7 排除 14、21、35、49
8 排除 16(8是由2可以排除)
9 排除 18、27(9是被3可排除)
10 排除 20(10是被2排除的)
就像4排除8,为啥不排除12呢。因为4它最小因数是2。因此它的3倍或者5倍的数字也有因数2,也就是它后面会有一个数字的两倍是12由这个数字去排除。每次只排除最近的,是前面数字留下的,后面的给后面的数字留下。像9它最小因数是3,他应该把2x9与3x9排除。由2这个最小因数产生的18它的最近的就是9,而2不是9的最小因数它的最小因数是3,构成3排除且离9最近也就是3*9,之后不会有数字可以筛选出它了。
把最小因数筛选的数字往后传递,每次筛选出最近的一层,即可完成不重复且永远走在前面的筛选
代码如下:
public int countPrimes(int n) {
// 标记筛选
byte[] arr = new byte[n];
// 最小因数(质数)
List<Integer> numbers = new ArrayList<>();
for (int i = 2; i < n; i++){
if(arr[i] == 0) numbers.add(i);
for(int j = 0; j < numbers.size() && numbers.get(j) * i < n; j++){
arr[numbers.get(j) * i] = 1;
if(i % numbers.get(j) == 0) break;
}
}
return numbers.size();
}
这种方式的话,时间与空间复杂度就都是O(n)了

image-20210721184038153
看起来实际是比埃氏筛选法好像效率低一些,但这个结果也受到是一些运算符以及其他底层环境的影响导致。
总结
本题找到一个数以内的质数的数量,解法一大概就是第一反应也就是依题意的解法,虽然意识到这个解法是走了弯路但没有琢磨出筛选法,在网上看了埃氏筛选法确实是可以用来解题,虽然这个东西应该是每个人都知道的道理,但没有意识到把这个东西进行严格的推理。在这之后也能想到线性筛选,这两种就好似纵向与横向的推演。那么除了实现思路上,对于代码在空间与时间上的优化也是在最终实现思路之后的优化点。像筛选标记这种只需要去存0/1也就是只占一位,如果我们只存8个用int数组的话就占用了8x32位。Java里面没有位数组,最小的是字节占8位也就是8x8位。没有位数组那么能不能8个0/1只用8位的空间去存呢,我们可以不用数组只用一个字节数字byte它有8位每一位存一个0或1,这是可以考虑的点。第二个是时间上对于线性筛选法对比埃氏筛选法时间复杂度是有提升的只是说在Java里实现这个线性筛选的时候使用了一些像取余这样的运算符等等会影响到执行效率,这个时候我们在处理一些运算的时候可以往位运算上想想,有的可以换成位运算有的不可以。主要就是三点第一思路上在开发的学习与工作当中可能很多想法被束缚了,换成高中时期的状态应该会顺利一点,第二就是关于空间对于标记类型的需要考虑到位,第三就是运算可不可以通过位运算达到同样的结果来提升实际效率。
本文分享自微信公众号 - IT那个小笔记(qq1839646816)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号