MapReduce
MapReduce程序开发
1、Demo:WordCount单词计数
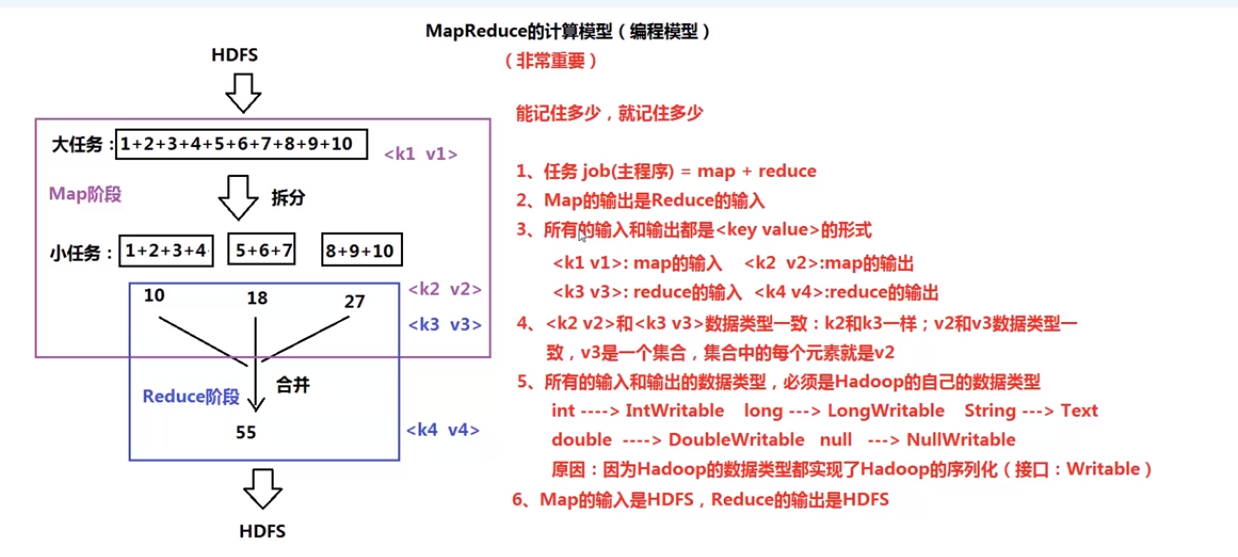
分析WordCount程序数据处理的过程(非常重要)
2、开发自己的WordCount程序
开发一个MapReduce:求每个部门的工资总额
3、MapReduce的一些高级特性
(1)序列化:类似Java的序列化
(2)排序:默认排序:数字 升序
字符串 字典顺序
对象的排序:按照员工的薪水排序
(3)分区:Partition,默认情况下,MapReduce只有一个分区,意思是:只有一个输出文件
(4)合并:Combiner,在Mapper端,先做一次Reducer,用于减少输出到Reducer中的数据,从而提高效率
(5)MapReduce的核心:Shuffle(洗牌)
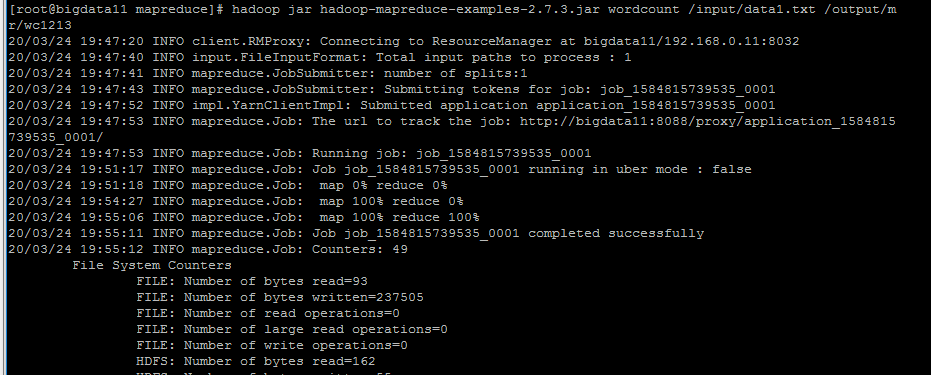
WordCount例子
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
执行:
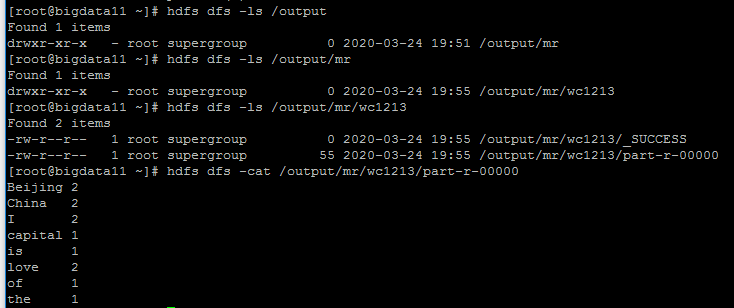
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/mr/wc1213
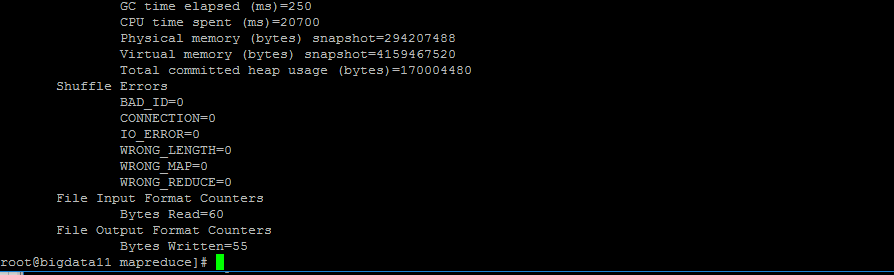
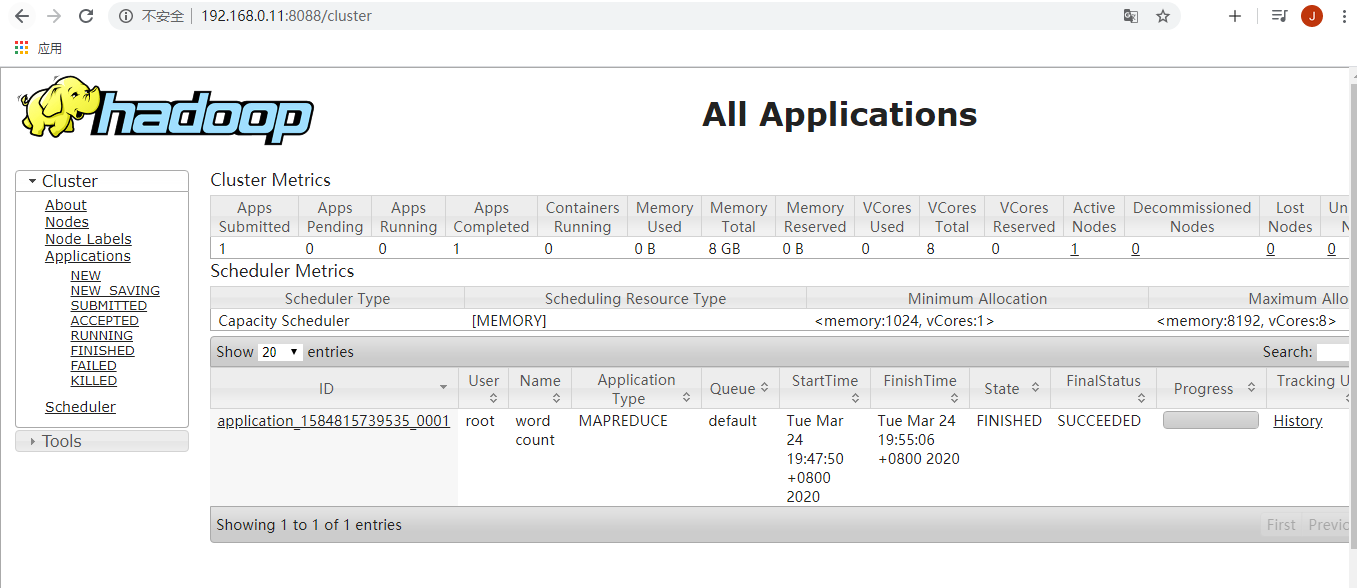
运行结果:
WordCount程序数据处理的过程

开发自己的WordCount程序
搭建开发环境
需要包含的jar:
/root/training/hadoop-2.7.3/share/hadoop/common
/root/training/hadoop-2.7.3/share/hadoop/common/lib
/root/training/hadoop-2.7.3/share/hadoop/mapreduce
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/lib
在eclipse中新建一个java project
在工程中新建一个lib文件夹,并将需要的jar包放进去。
将所以jar包加到path当中。
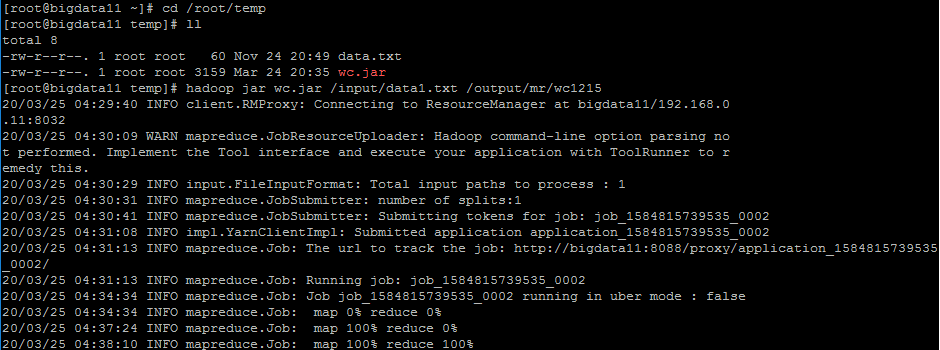
实验环境搭建好后新建项目和java文件,将代码写好后打包成jar包。




将打包好的jar包上传到Linux中。
在Linux中启动环境: start-all.sh
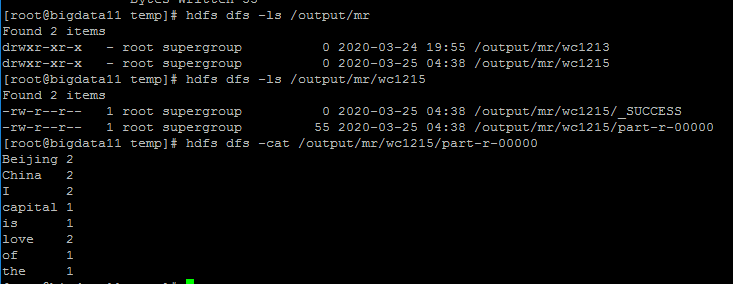
执行自己的Wordcount程序
等待程序运行完成后查看结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号