Hadoop——搭建伪分布模式
2019-11-24
11:26:52
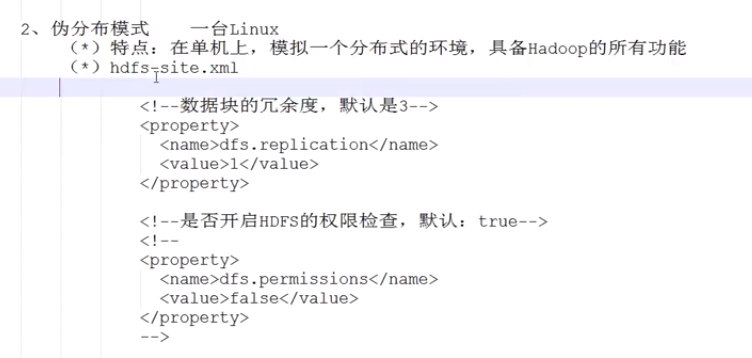
dfs.replication 代表数据节点冗余度。 默认是3,如果只有1个数据节点则配置为1

代表默认目录
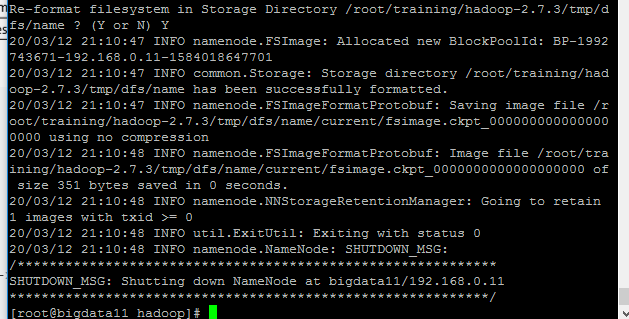
格式化后显示:

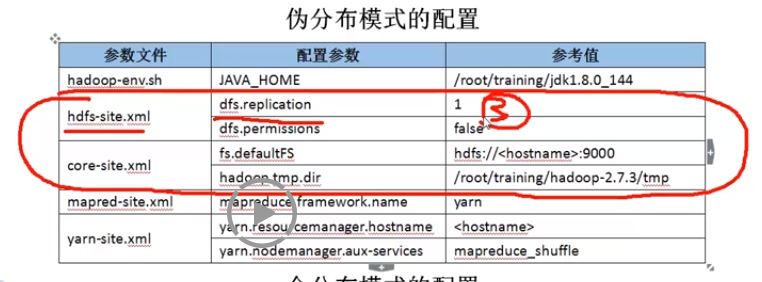
伪分布模式
特点:在单机上,模拟一个分布式的环境,具备Hadoop的所有功能。
配置:
需要配置的信息:
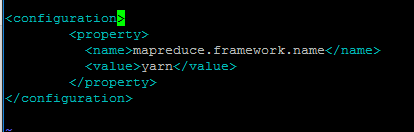
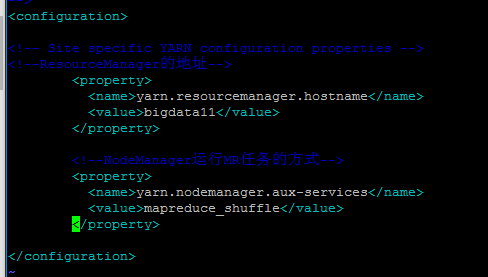
hdfs-site.xml <!--数据块的冗余度,默认是3--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--是否开启HDFS的权限检查,默认:true--> <!-- <property> <name>dfs.permissions</name> <value>false</value> </property> --> core-site.xml <!--NameNode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata11:9000</value> </property> <!--HDFS数据保存的目录,默认是Linux的tmp目录--> <property> <name>hadoop.tmp.dir</name> <value>/root/training/hadoop-2.7.3/tmp</value> </property> mapred-site.xml <!--MR程序运行的容器是Yarn--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> yarn-site.xml <!--ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata11</value> </property> <!--NodeManager运行MR任务的方式--> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
1.进入hadoop的配置文件目录
2.将配置信息放入文件里的configuration下



3.对NameNode进行格式化:hdfs namenode -format
4.启动:start-all.sh
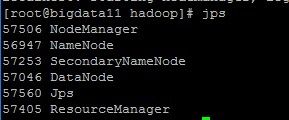
5.查看进程是否启动:JPS




datanode没有显示,如何处理?
https://blog.csdn.net/ugug654/article/details/77801286


 浙公网安备 33010602011771号
浙公网安备 33010602011771号