第5章 优化程序性能
第5章 优化程序性能
5.1优化编译器的能力和局限性
在第三章中讨论过,用-og会用一组比较基本的优化,-O2优化级别已经成为了比较被接受的标准,但还是主要考虑-O1编译出的代码
编译器必须很小心的对程序进行优化。
像是这个例子中,twiddle1与twiddle2看似有相同的行为,但是如果xp , yp 指向同一个内存地址,产生的结果就会不一样。这个被称为内存别名使用(memory aliasing)
5.2表示程序性能
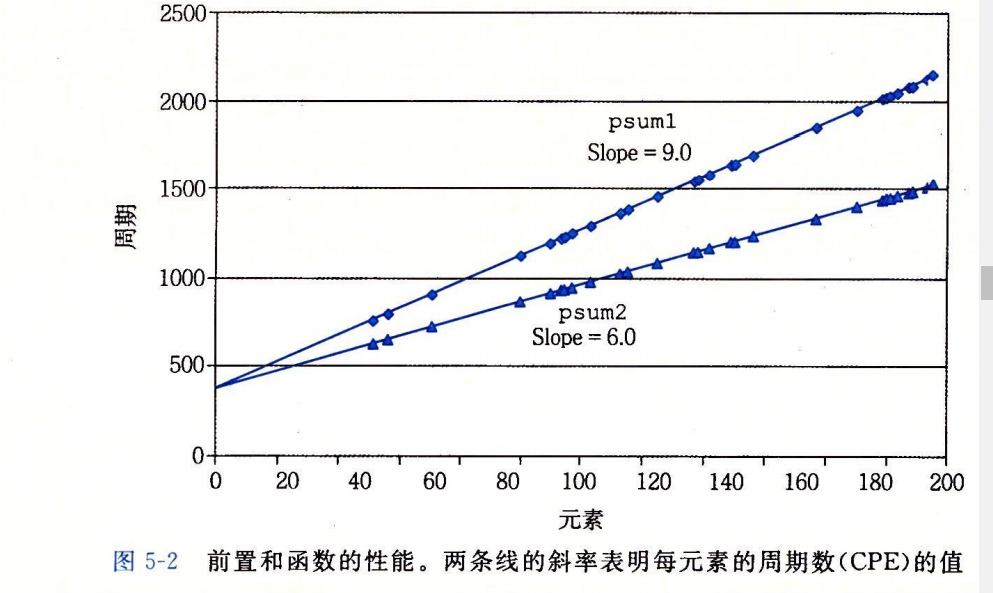
我们引入度量标准每元素的周期数(Cycles Per Element ,CPE)作为一种表示程序性能和帮助我们优化它的一种方法.
有三个概念比较容易混淆:
1.指令周期:指一条指令从取指到执行完成的时间
2.CPU周期:指一条指令被分为不同阶段,完成每个阶段需要的时间
3.时钟周期:这是一个基本时间单位,可以理解为阀门开关的时间。
处理器的活动顺序是由时钟控制的,时钟提供了某个频率的规律信号,通常用千兆赫兹来表示(GHZ),即十亿周期每秒来表示。用时钟周期来表示,度量值表示的是执行了多少条指令。

像是这两个函数,韩舒而运用了循环展开(loop unrolling)的技术,每次迭代计算两个元素。
5.3程序示例
//一个生成向量、访问向量元素以及确定向量长度的基本过程 typedef struct{ long len; data_t *data; }vec_rec , *vec_ptr; typedef long data_t; vec_ptr new_vec(long len){ vec_ptr result = (vec_ptr) malloc(sizeof(vec_rec)); data_t *data = NULL; if(!result){ return NULL; } result->len = len; if(len > 0){ data = (data_t *)calloc(len,sizeof(data_t)); if(!data){ free((void *) result); return NULL; } } result->data = data; return result; } int get_vec_element(vec_ptr v,long index , data_t *dest){ if(index < 0 || index >= v->len){ return 0; } *dest = v->data[index]; return 1; } long vec_length(vec_ptr v){ return v->len; }
下面我们定义一个对向量进行操作的函数
//我们可以用不同定义来对向量元素进行求和或者求乘积 #define IDENT 0 #define OP + Or #define IDENT 1 #define OP * void combine1(vec_ptr v , data_t *dest){ *dest = IDENT; for(long i = 1 ; i < v->len ; i++){ long val; get_vec_element(v,i,&val); *dest = *dest OP val; } }
我们如果用-o1优化,就会显著的提高程序性能
5.4 消除循环的低效率
在combine1中我们调用函数vec_length作为for循环的测试条件,也就是说循环一次就要进行一次vec_length的计算,大大延缓了程序的进行。
所以我们通过代码移动(code motion)来进行优化
5.5 消除过程调用
在combine1中,每次获取元素都要进行边际检测。大大减缓了程序速度。因此我们在combine3中,直接先获得第一个数组的指针。后面通过数组引用的方法来获得索引数据。

5.6 消除不必要的内存引用
在之前的combine中我们每次进行循环计算就要对dest进行内存访问,这也是不必要的,因此我们创造一个temp变量来进行中间计算

5.7 理解现代处理器
5.7.1整体操作
我们要进一步的理解现代处理器的设计。假想的处理器设计是不太严格地基于近期的intel处理器结构。这些处理器成为超标量,意思是他可以在每个时钟周期执行多个操作,而且是乱序的。整个设计有两个主要部分:指令控制单元和执行单元。
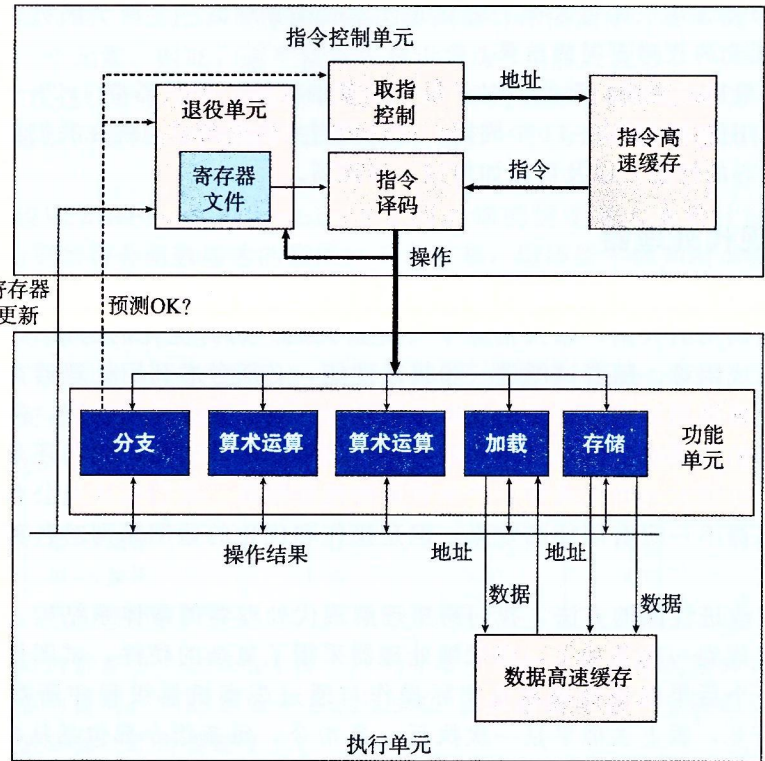
ICU从指令高速缓存中读取指令。当程序遇到分支的时候,它会采用一种分支预测的技术,处理器会猜测是否会选择分支,使用投机执行的技术开始取出预测的分支将要跳到的地方。指令译码逻辑接受实际的程序指令,并将他们转换成一组基本操作,完成某个简单的计算任务,例如两个数相加。
5.7.2 功能单元的性能
延迟(latency):完成运算需要的时间
发射时间(issue time) :表示两个连续的同类型运算之间需要的最小时钟周期数
容量(capacity):表示能够执行该运算的功能单元的数量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号