windows下大数据开发环境搭建(4)——Spark环境搭建
一、所需环境
· Python 2.6+
二、Spark下载与解压
http://spark.apache.org/downloads.html
按照以下截图提示,点击下载Spark的tgz压缩包。


下载完成后将Spark用7zip工具解压,放到一个不带空格的根目录下,我将起放在C盘的spark文件夹下:C:\spark\spark-2.4.4-bin-hadoop2.7
三、环境变量配置
SCALA_HOME: C:\spark\spark-2.4.4-bin-hadoop2.7 Path: C:\spark\spark-2.4.4-bin-hadoop2.7\bin
四、winutils.exe文件补充
需要从https://github.com/steveloughran/winutils 或 https://gitee.com/likespace/winutils 此处下载与你的hadoop版本对应或版本更高的winutils.exe文件,并保存到Hadoop的bin目录下。
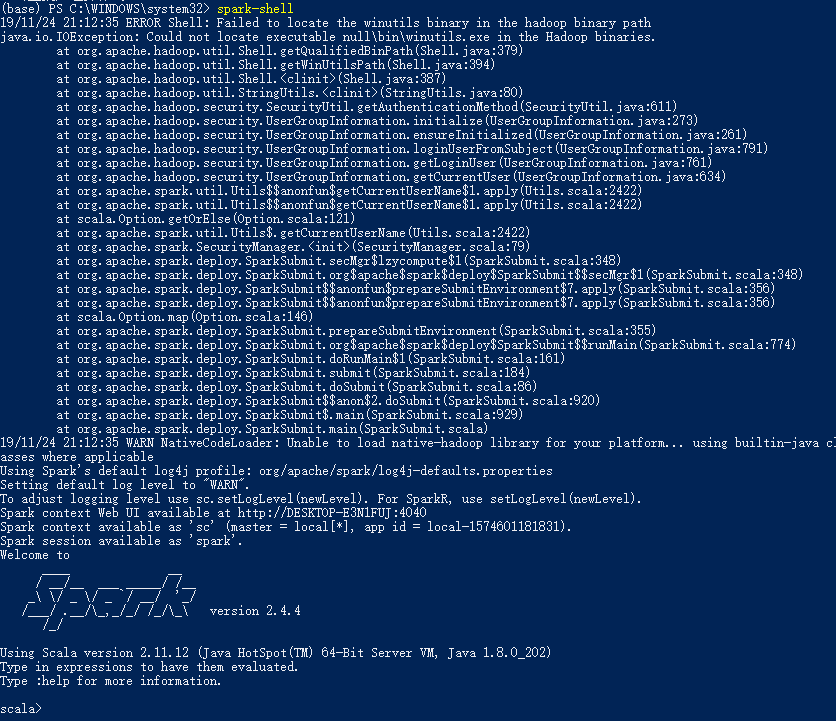
如果没有winutils.exe文件,执行spark-shell将会出现如下错误:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
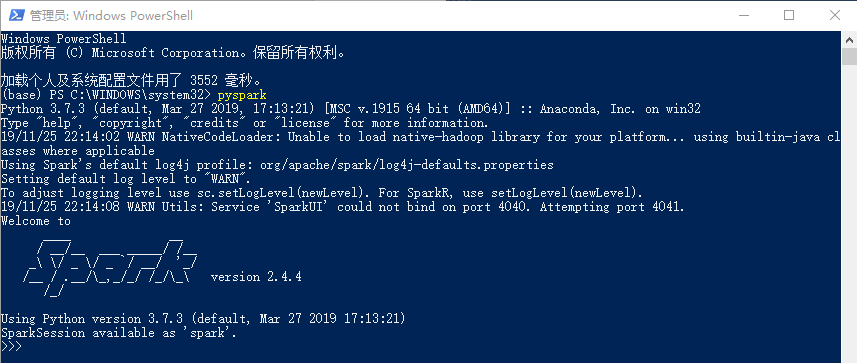
五、命令行检验
1.启动scala shell模式
spark-shell

2.启动python shell模式
pyspark
3.查看Spark context Web UI
http://127.0.0.1:4040

4..退出shell
ctrl + D

至此,我们已经成功在windows环境下搭建起Spark开发环境,可以使用Spark愉快地继续自己的大数据之旅了!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号