通过并行数据以及TS学习来增强ASR的鲁棒性
ICASSP 2019 SLP-P11.11 IMPROVING NOISE ROBUSTNESS OF AUTOMATIC SPEECH RECOGNITION VIA PARALLEL DATA AND TEACHER-STUDENT LEARNING
简述
Teacher模型对三音素的离散概率分布用于指导Student模型。由于一般的ASR系统包含数千个三音素,处理一帧将计算数千的三音素的概率。并且,大多数输出概率向量中只有少数维数有较大的值,其余维数的值都非常小并且带噪,这会迷惑Student模型。
因此,使用逻辑选择方法,只保留输出后验概率向量中前k个最高的维数。这样只有最可信的信息被保留下来,用于知道学生模型。这一方法也能够减少将教师输出传递给学生模型的带宽。
算法
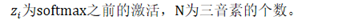

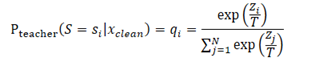
其中T为分布中用于控制平滑度的Temperature
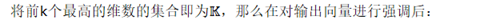
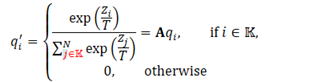
这样能大大减少存储软目标所需存储空间以及训练时的IO。
对向量进行增强也能提升学生模型对教师模型的置信度。

3层LSTM,3010输出维数,64维fBank特征
800小时过阵列转录数据,7200小时过阵列无转录数据
目标场景为室内带多媒体噪声环境。
以0-30dB抽取500-900ms RT60的RIR进行加混响
- 使用800小时干净过阵列数据训练Teacher模型
- 对未转录的干净数据集加噪
- 未转录干净数据过教师模型,未转录噪声数据过学生模型,学生模型的准则函数为其输出与教师模型输出的KL散度(交叉熵)。
- 梯度下降
CE,与仅使用800小时带转录干净数据训练的教师模型相比,
多条件训练(TS)的WER下降4.26%
该文献的方法WER下降6.82%(Temporature=1,且最优)
实验结果与结论
CE+sMBR,与使用1600小时干净带转录数据训练的教师模型相比,使用4800小时无转录数据+800小时转录数据,以该文献提出的方法训练的学生模型,能提升19.58%
原文
Mošner, Ladislav, Minhua Wu, Anirudh Raju, Sree Hari Krishnan Parthasarathi, Kenichi Kumatani, Shiva Sundaram, Roland Maas, and Björn Hoffmeister. "Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning." arXiv preprint arXiv:1901.02348 (2019).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号