CNN for Visual Recognition (02)
2015-01-12 16:38 Jack King 阅读(809) 评论(0) 收藏 举报图像分类
参考:http://cs231n.github.io/classification/
图像分类(Image Classification),是给输入图像赋予一个已知类别标签。图像分类是计算机视觉(Computer Vision)问题中一个基本问题,也是很要的一个问题。诸如物体检测、图像分割等可以利用图像分类来解决。
图像分类问题的主要难点在以下几个方面:
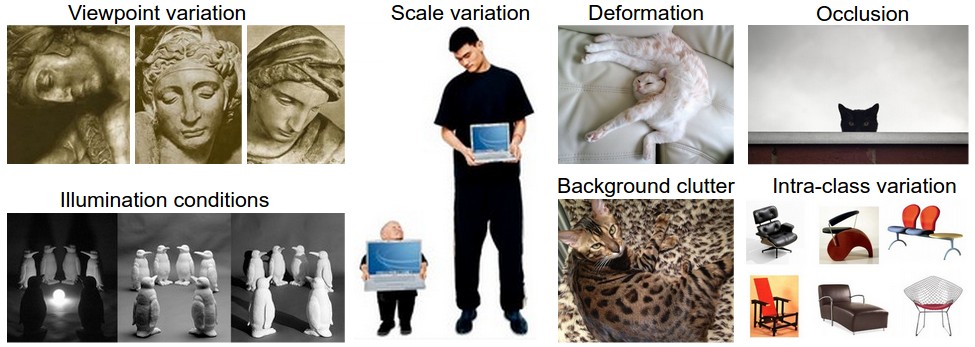
- 视角差异(viewpoint variation):拍摄角度
- 比例差异(Scale variation):缩放比例
- 形变(Deformation):主要为非刚性形变(non-rigid deformation)
- 遮挡(Occlusion):局部遮挡
- 光照差异(Illumination condition):光线情况不同
- 背景噪声(Background clutter):背景与前景接近
- 类内差异(intra-class variance):类内差异大于类间差异
(ref: http://cs231n.github.io/assets/challenges.jpeg)
数据驱动的方法(data-driven approach):
从机器学习角度讲,训练数据(training data)为学习过程提供先验知识。
解决图像分类流程(pipeline):
- 输入(input):包括图像和类别标签;
- 学习(learning):学习分类器(classifier)或是模型(model)进而预测输入图像标签;
- 评价(evaluation):比较预测标签和实际标签,评价分类器(模型)的性能。
最邻近分类(Nearest Neighbor Classifier):
(只是为了能够直观了解图像分类问题)
根据已有数据及标签(training data),预测输入图像(input image)为其最邻近图像的标签。进一步扩展可为K邻近方法,K邻接相对更加常用。相对而言,kNN在特征维度较低的时候,能力比较强的。
对于kNN而言有两个问题不好确定:
第一个就是k值的选择。K值较小时,对噪声敏感;k值较大,会削弱对decision boundary附近样本的判别能力。最简单的方法就是交叉验证,在验证集尝试不同取值;还有一些参考文件中使用\sqrt(N),其中N是每一类中样本的平均数(很明显对数据量很大的情况不适用)。
第二个就是对距离量度(distance metric)的选择。比较常用的是L1和L2距离。但是对一些问题,需要进行距离量度学习(distance metric learning)。比较常用的学习方法有LMNN(Large Margin Nearest Neighbor),ITML(Information-Theoretic Metric Learning)
关于使用kNN的一个小节:
- 对特征做正规化(normalization),即零均值、单位方差;
- 特征维数很高时降维,如PCA等;
- 在训练集上划分验证集;
- 交叉验证不同的k值及距离量度;
- 时间开销过大时考虑Approximate Nearest Neighbor (FLANN)代替(以降低准确率为代价)。
延伸阅读:
A Few Useful Things to Know about Machine Learning,英文
机器学习那些事,中文
Recognizing and Learning Object Categories, ICCV2005的一个short course。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号