vgg学习笔记
vgg
Vgg简介:
全称:Very deep Convolutional Networks for large-scale image recognition(用于大规模图像识别的非常深的卷积网络)
在2014年获得Imagenet竞赛中Localization Task(定位任务)第一名和Classification Task(分类任务)第二名

提出两个算法,分别为vgg16和vgg19
所有卷积使用3x3的小卷积
用两层3x3卷积可以代替原来的5x5卷积,且会带来更多好处
vgg模型的特点:
非常臃肿,计算量大,参数量多,准确率也不是特别高。
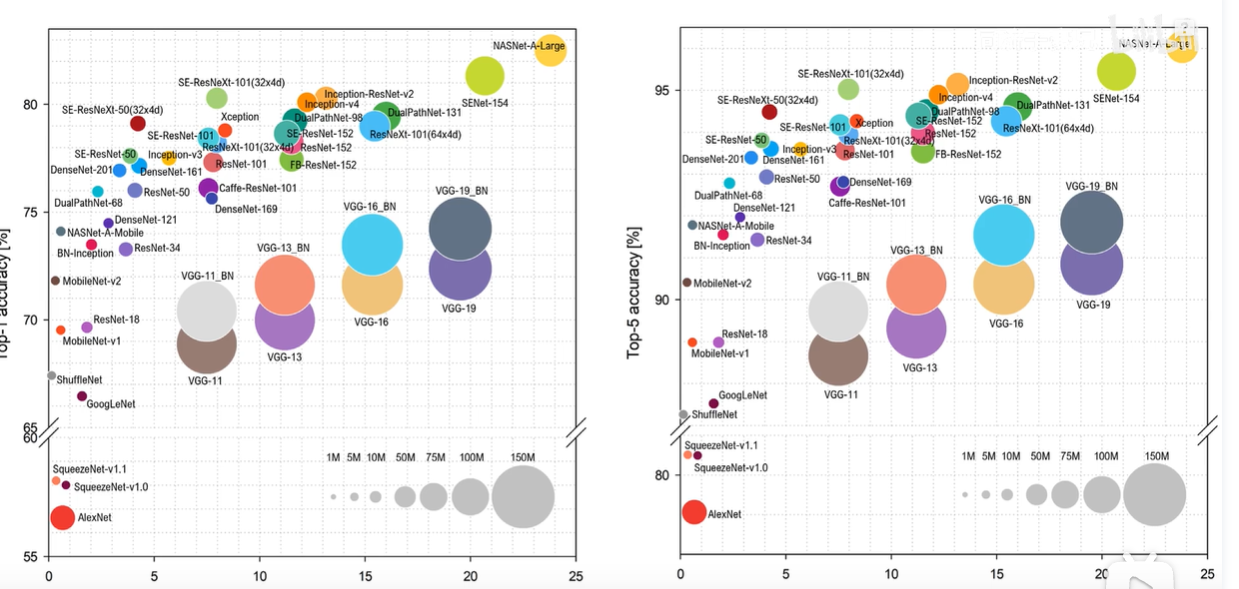
横轴为计算量,纵轴为top—5准确率,可以看出vgg的表现并不是很优秀。
两个3x3的卷积核相当于一个5x5的感受野
三个3x3的卷积核相当于一个7x7的感受野
卷积核越小,参数越少
卷积核越小,参数越少
例如:假设输入输出channel(通道数量)为C,三个3x3的卷积核的参数个数为3x3xCxCx3=27C2个,而一个7x7卷积核参数个数为:7x7xCxC=49C2个。
使用小的卷积核的问题是,其感受野必然变小。所以,VGG中就使用连续的3×3卷积核,来增大感受野。VGG认为2个连续的3×3卷积核能够替代一个5×5卷积核,三个连续的3×3能够代替一个7×7。
感受野:在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小。
vgg网络结构图:

黑色框:代表卷积及relu激活函数
红色框:最大下采样
蓝色框:全连接层加relu激活函数
黄色框:softmax处理
先经过两个3x3的卷积层,再最大下采样操作2x2的池化层,两层3x3大小的卷积核,最大下采样,大小变成原来的一半。。。。。。
三层全连接层,全连接层1和2,节点为4096,全连接层3,节点为1000个,最后是一个softmax层
softmax作用:将预测结果转化为概率分布
论文作者总结:
1.LRN层(局部响应归一化)的作用不大
VGGNet不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间
防止过拟合:采用在FC层中间采用dropout层
2.越深的网络效果越好
3.大一些的卷积核可以学到更大的空间特征
AlexNet中用到了一些非常大的卷积核,比如11×11、5×5卷积核,之前人们的观念是,卷积核越大,receptive field(感受野)越大,看到的图片信息越多,因此获得的特征越好。虽说如此,但是大的卷积核会导致计算量的暴增,不利于模型深度的增加,计算性能也会降低。于是在VGG(最早使用)、Inception网络中,利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号