pytorch笔记----反向传播
反向传播
深度学习神经网络训练的过程就是对权重的更新
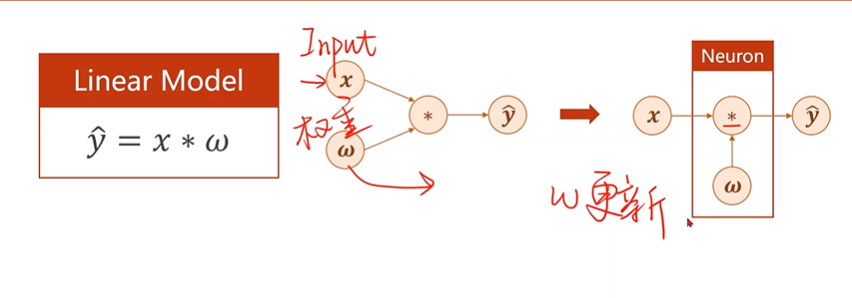
更新权重的过程:损失对权重的导数
\[\frac{\partial loss}{\partial w}
\]
对于线性函数,无论经过多少层迭代,最终结果都是一个线性的函数,所以我们需要用一个非线性函数及激活函数,将每一层的结果做非线性代换,增加其复杂度。
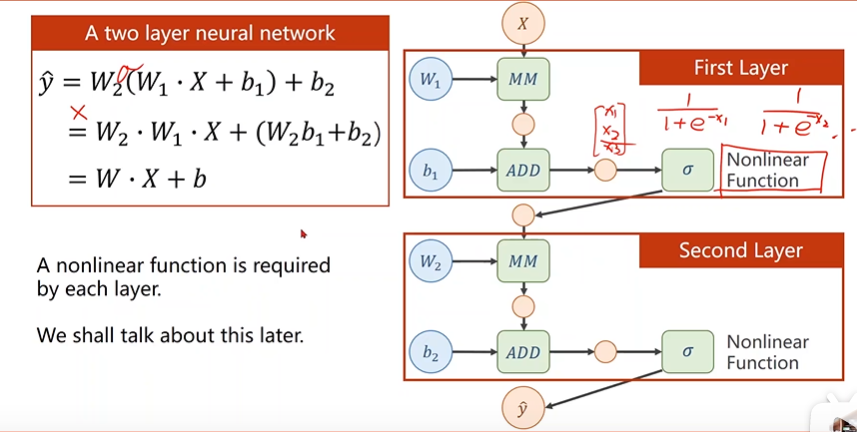
在pytorch里面,使用Tensor去存值,可以是向量,标量,矩阵之类的数据,Tensor包括data和grad两个成员,Data用来保存w(权重),Grad用来保存损失函数对权重的导数。
张量(tensor):
Tensor实际上就是一个多维数组
而Tensor的目的是能够创造更高维度的矩阵、向量
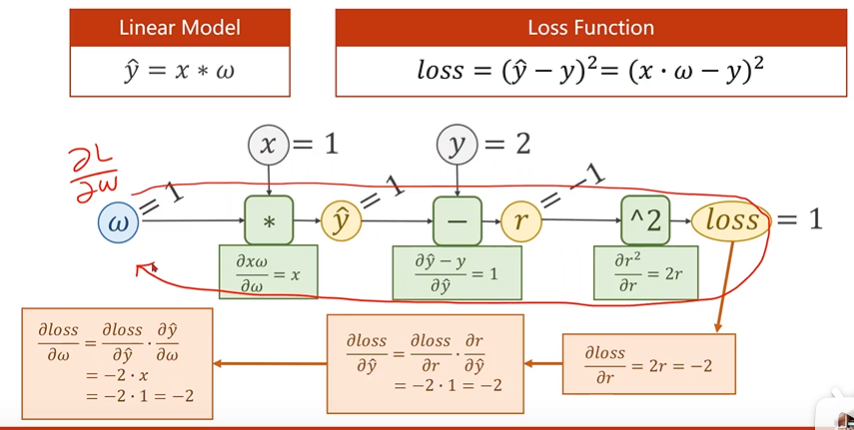
反向传播过程图
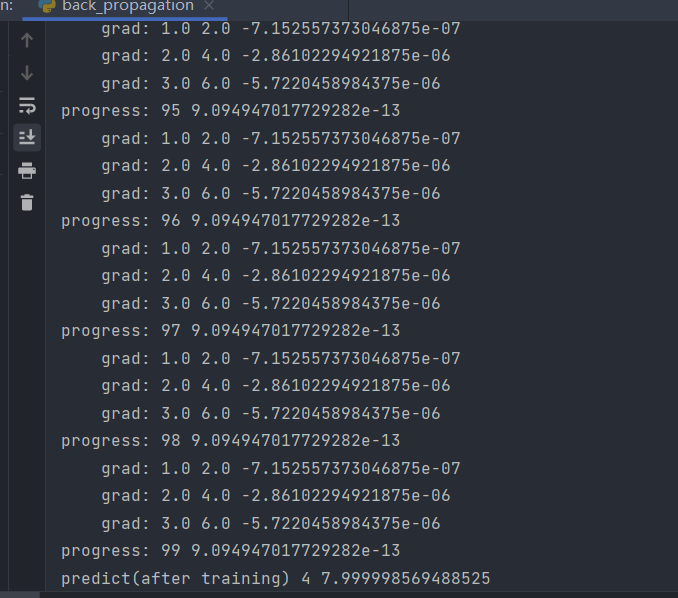
代码示例:
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.tensor([1.0]) # w的初值为1.0
w.requires_grad = True # 需要的计算梯度
def forward(x):
return x*w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)**2
print("predict (before training)", 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss
l.backward() # backward,compute grad for Tensor whose requires_grad set to True
print('\tgrad:', x, y, w.grad.item())
w.data = w.data - 0.01 * w.grad.data # 权重更新时,需要用到标量,注意grad也是一个tensor
w.grad.data.zero_() # after update, remember set the grad to zero
print("progress:", epoch, l.item()) # after update, remember set the grad to zero
print("predict(after training)", 4, forward(4).item())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号