

实验代码和结果分析
# 实验代码和结果分析
1、查重算法
cheatR中算法
txt数据格式:元组(字典(词项:词项在文中出现的频率),文档总数)
def compare_txt(txt1, txt2):
"""
cheatR中的计算方法: 相同词项总频率/词项总数,其中相同词项的频率 = min(a,b)*2
"""
same_words = txt1[0].keys() & txt2[0].keys()
#取相同词项
#print(same_words)
total = txt1[1]+txt2[1]
freq = 0
for word in same_words:
temp = 2*(txt1[0][word] if txt1[0][word] < txt2[0][word] else txt2[0][word])
freq += temp
#相同词项总频率
return freq/total
Jaccard算法
txt数据格式:元组(字典(词项:词项在文中出现的频率),文档内词项总数)
def jaccard(txt1, txt2):
same_words = txt1[0].keys() & txt2[0].keys()
total_words = txt1[0].keys() | txt2[0].keys()
return len(same_words) / len(total_words)
TF_IDF&余弦相似度算法
files_spilt数据格式:字典(文件名: 元组(字典(词项:词项在文中出现的频率),文档内词项总数))
def sum_df(files_spilt):
"""
计算文档集中有某词项的个数,遍历所有文档,统计个数
返回 词项:出现此词项的文件名 的字典
"""
word_df = {}
#存储词项的df值
for file in files_spilt.keys():
for word in files_spilt[file][0].keys():
#word:文档中的词项
word_find = set()
#统计出现word的文件名
if word in word_df.keys():
word_df[word].add(file)
else:
word_find.add(file)
word_df[word] = word_find
return word_df
word_df:根据词项生成的倒排索引(词项:出现此词项的文档),length:文档的数目
def cos_compare_txt(word_df, txt1, txt2, length):
"""
余弦相似度比较方法
"""
sum_word = txt1[0].keys() | txt2[0].keys()
#sum_word统计两篇文中所有出现的词项
temp = {}
#格式 词项: weight列表(weight1,weight2)
format_sum1 = 0
format_sum2 = 0
#用于余弦归一化操作
for word in sum_word:
weight_list = []
df = len(word_df[word])
idf = (math.log((length/df), 10))
#idf = 1
#print(idf)
#idf = log(N/df)
#tf-idf = (1+logtf)*idf
if word in txt1[0].keys():
tf1 = txt1[0][word]
#词频
else:
tf1 = 0
if word in txt2[0].keys():
tf2 = txt2[0][word]
else:
tf2 = 0
if tf1 > 0:
weight1 = (1+ math.log(tf1, 10))*idf
#权重计算
else:
weight1 = 0
format_sum1 += weight1*weight1
weight_list.append(weight1)
if tf2 > 0:
weight2 = (1 + math.log(tf2, 10))*idf
else:
weight2 = 0
format_sum2 += weight2*weight2
weight_list.append(weight2)
temp[word] = weight_list
# print(temp)
connection = 0
format_sum1 = format_sum1 ** 0.5
format_sum2 = format_sum2 ** 0.5
for word in temp.keys():
t1 = temp[word][0]
t2 = temp[word][1]
if format_sum1 != 0:
c1 = t1/format_sum1
else:
c1 = 0
if format_sum2 != 0:
c2 = t2/format_sum2
else:
c2 = 0
#余弦归一化
connection += c1 * c2
#相似度计算
return connection
2、结果分析
取100份文档
- 不设置n-grams(1)
cheat-R
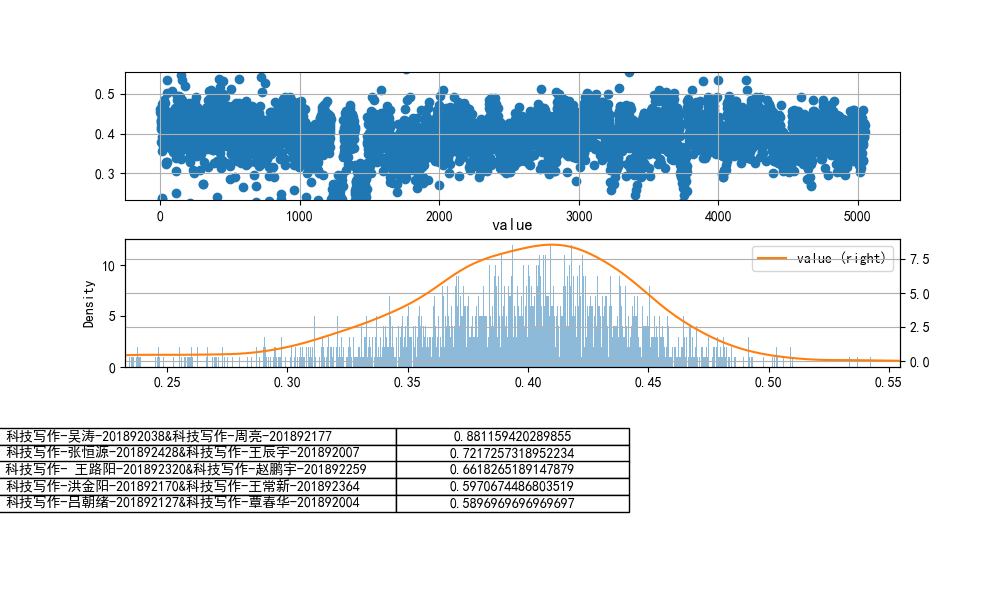
tf-idf余弦相似度
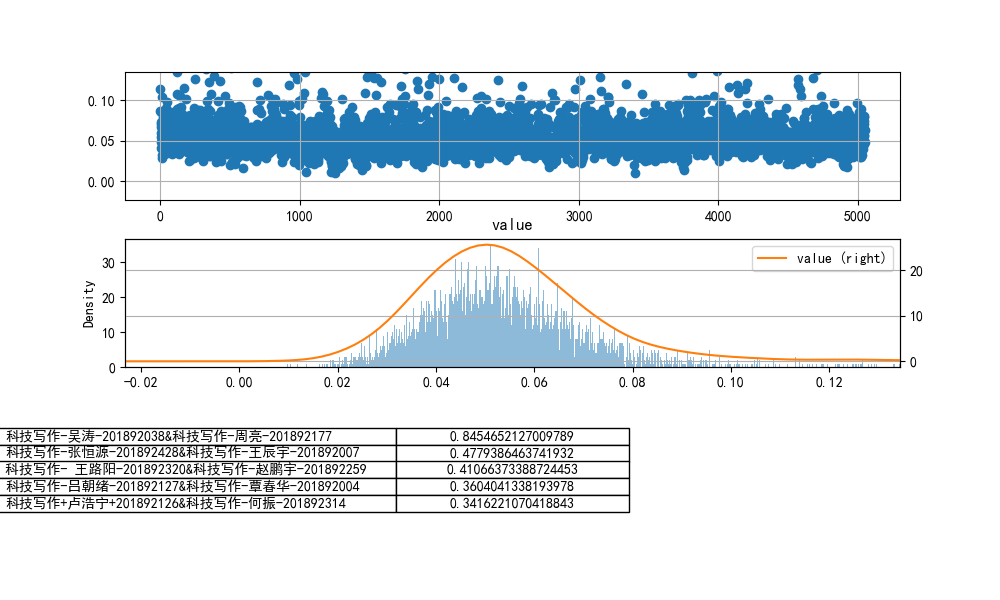
jaccard
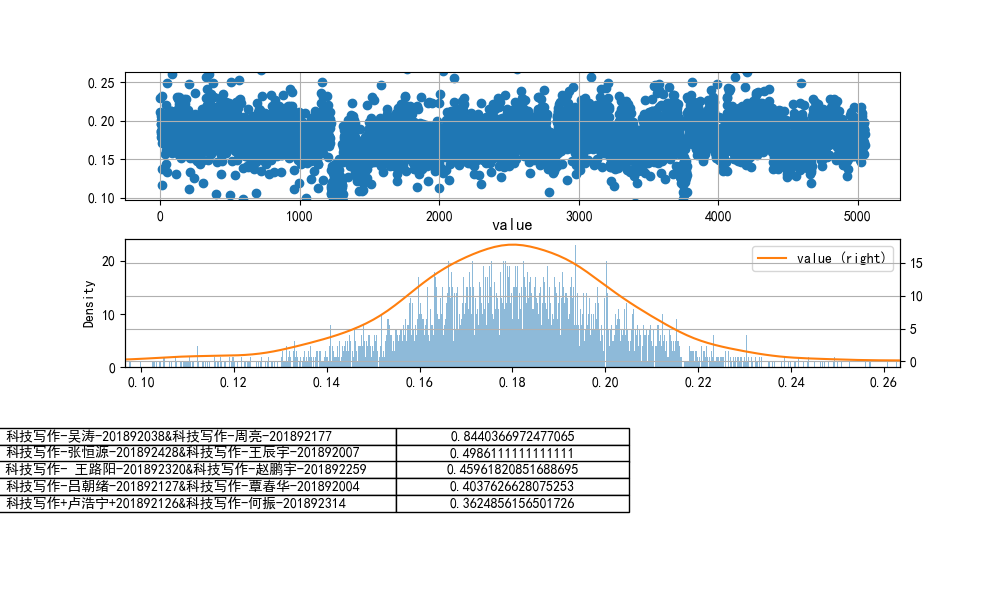
- 设置n-grams取(1,2)
cheat-R
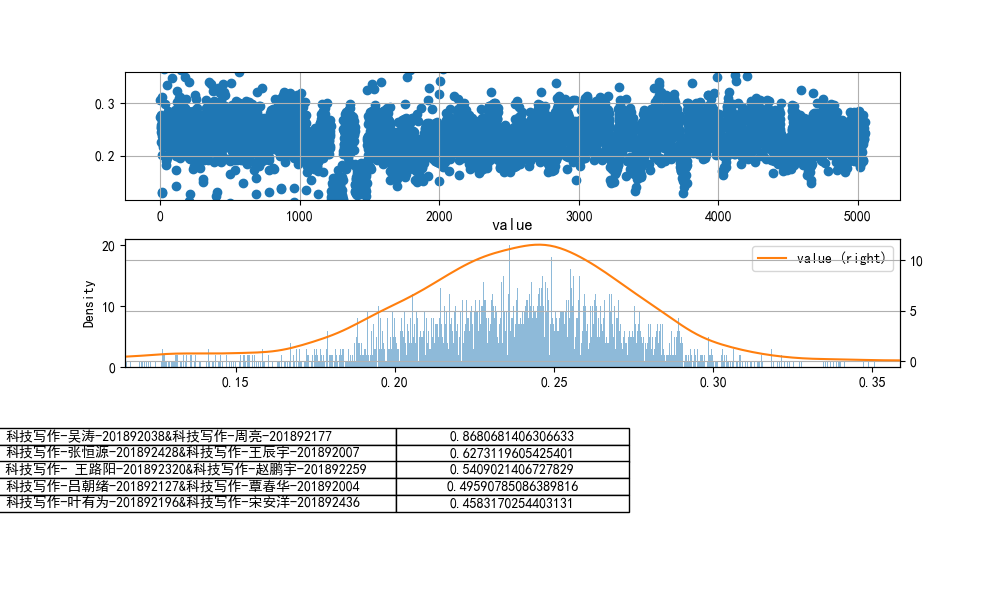
tf-idf余弦相似度
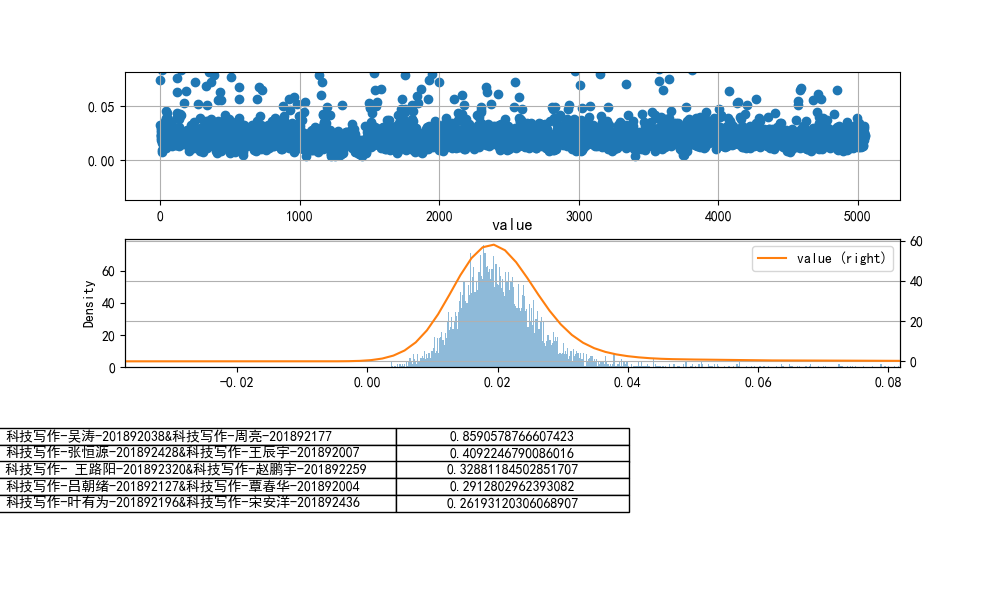
jaccard
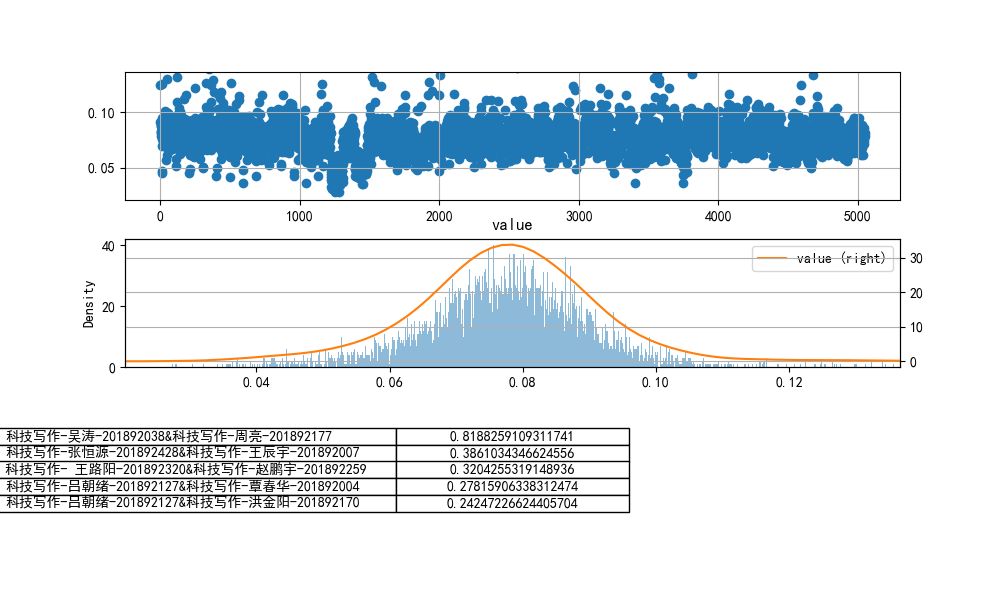
- 设置n-grams取(2,3)
cheat-R
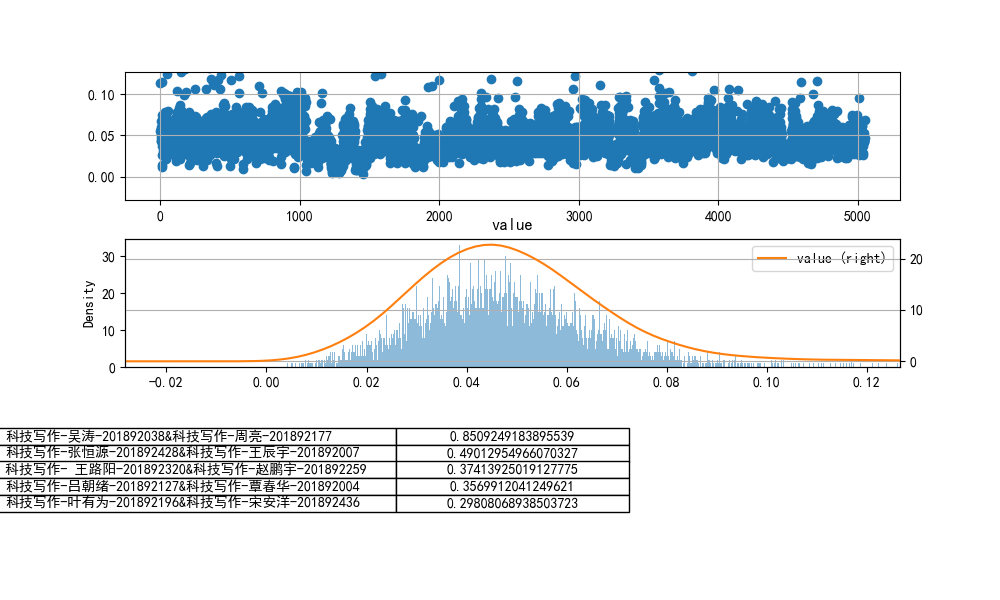
tf-idf余弦相似度
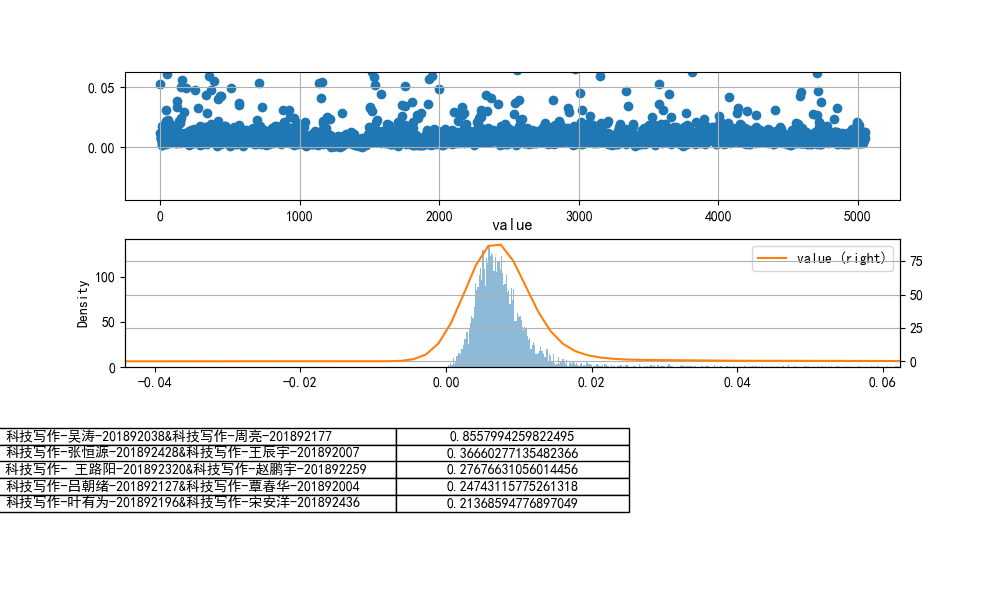
jaccard
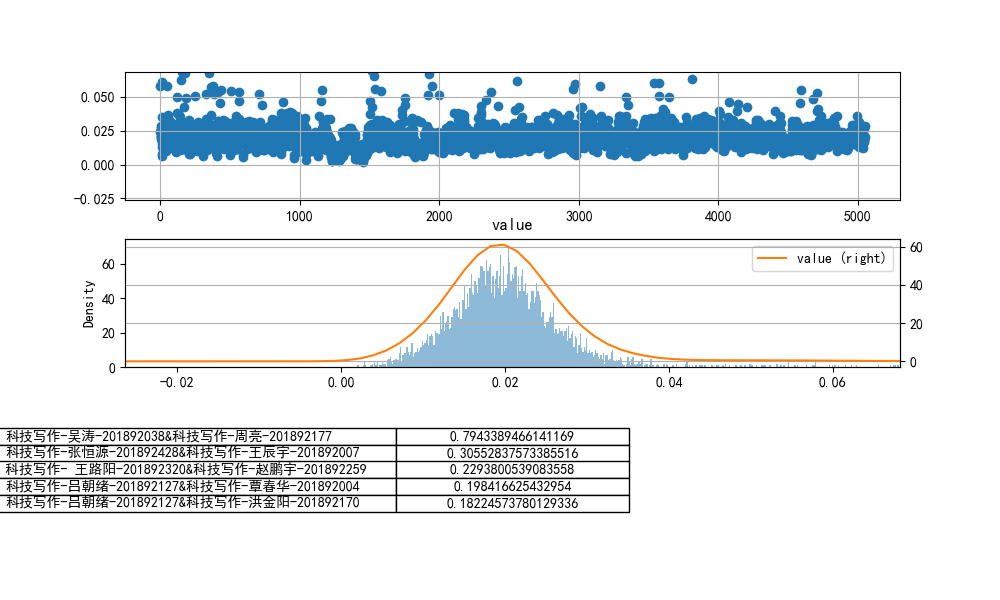
取300份文档
- 不设置n-grams(1)
cheat-R
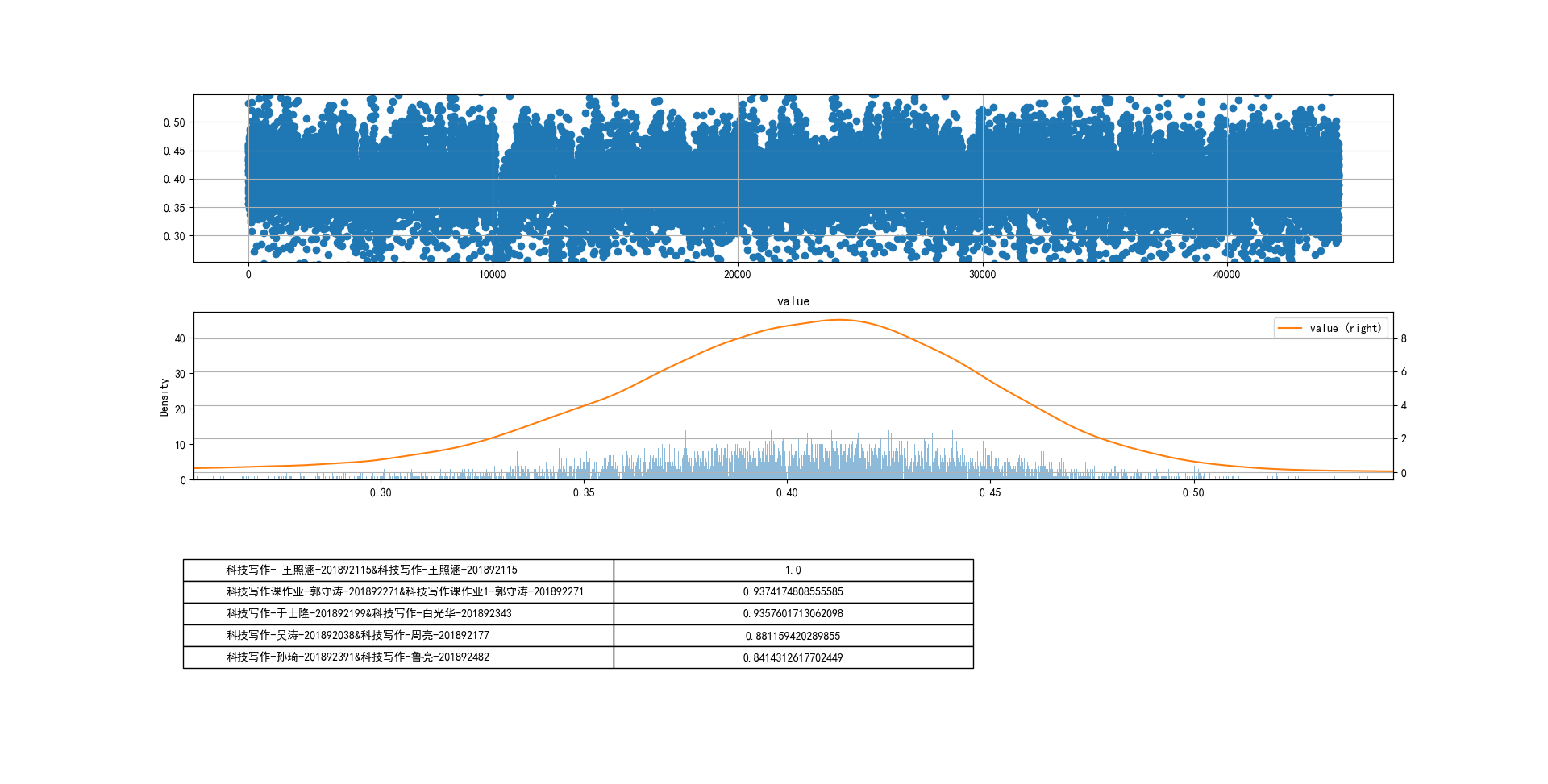
tf-idf余弦相似度
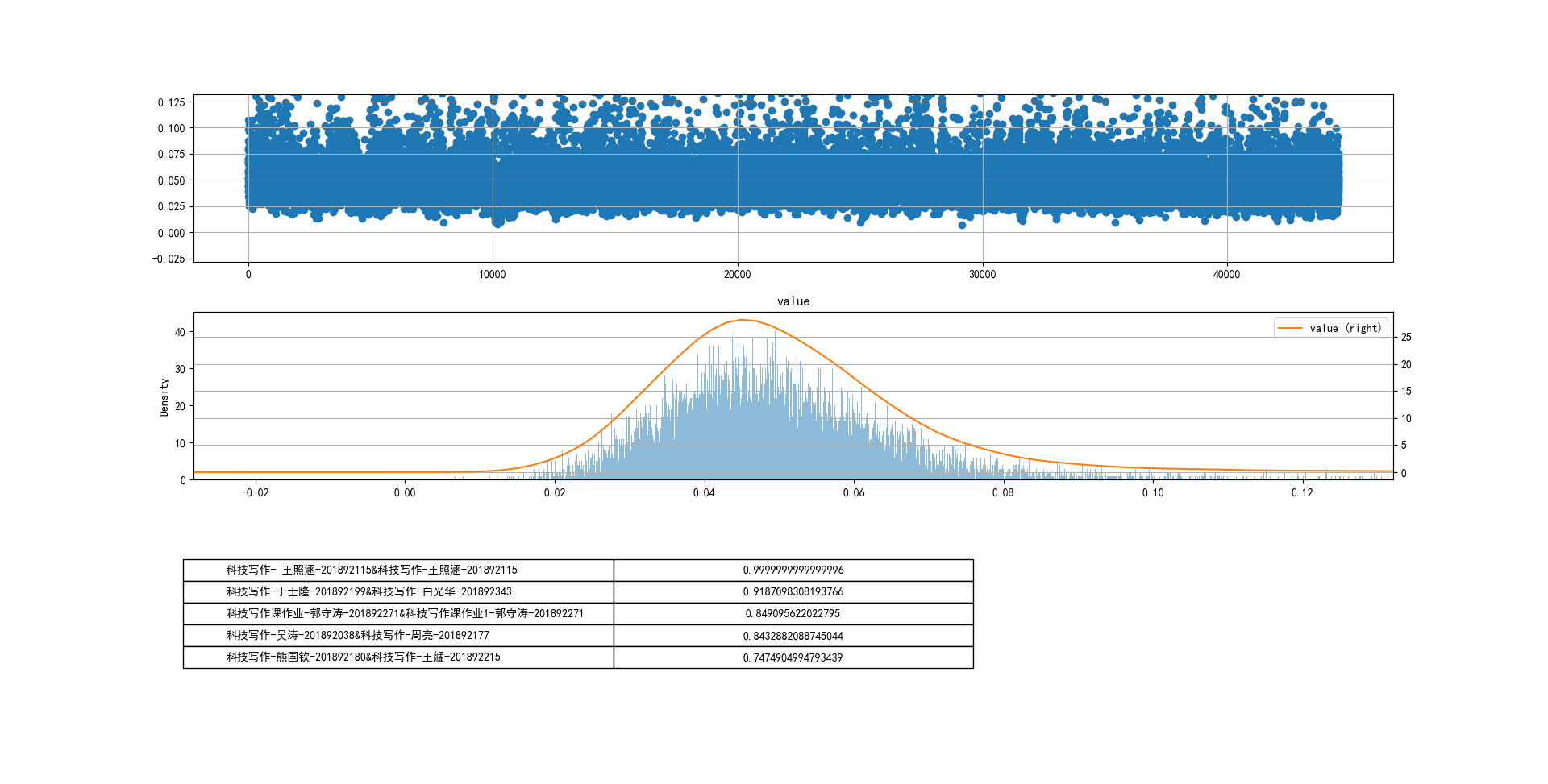
jaccard
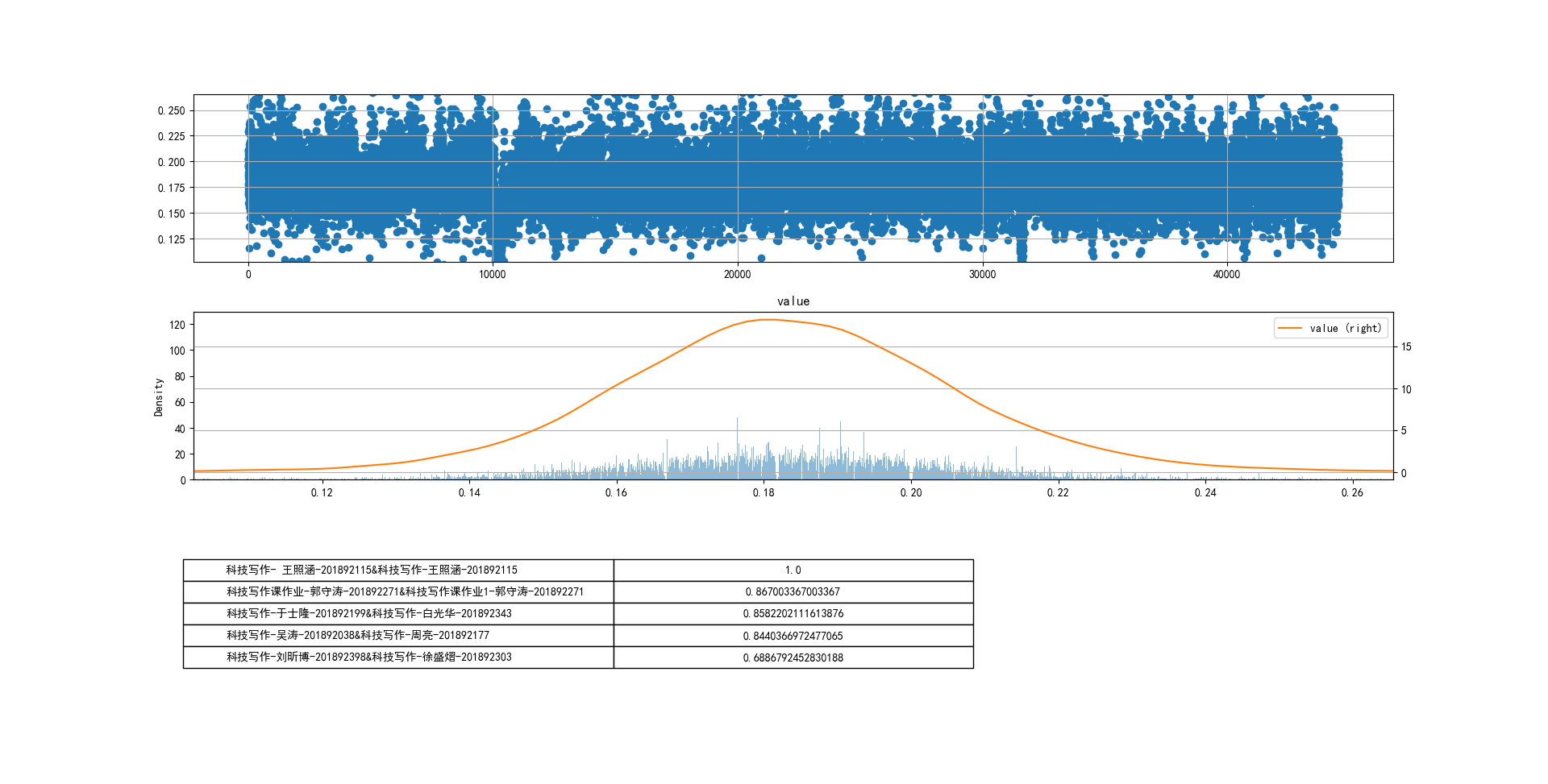
- 设置n-grams取(1,2)
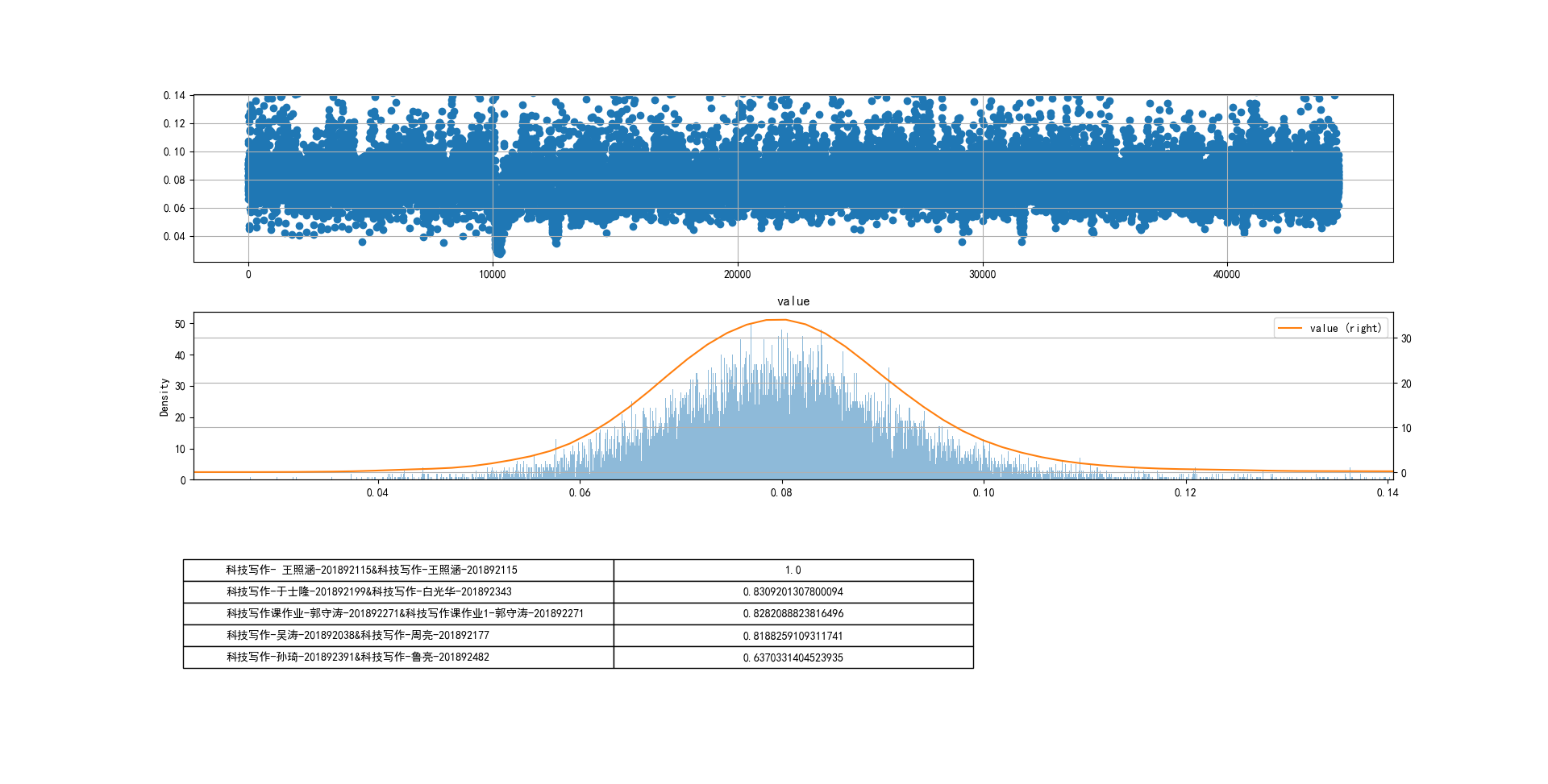
cheat-R
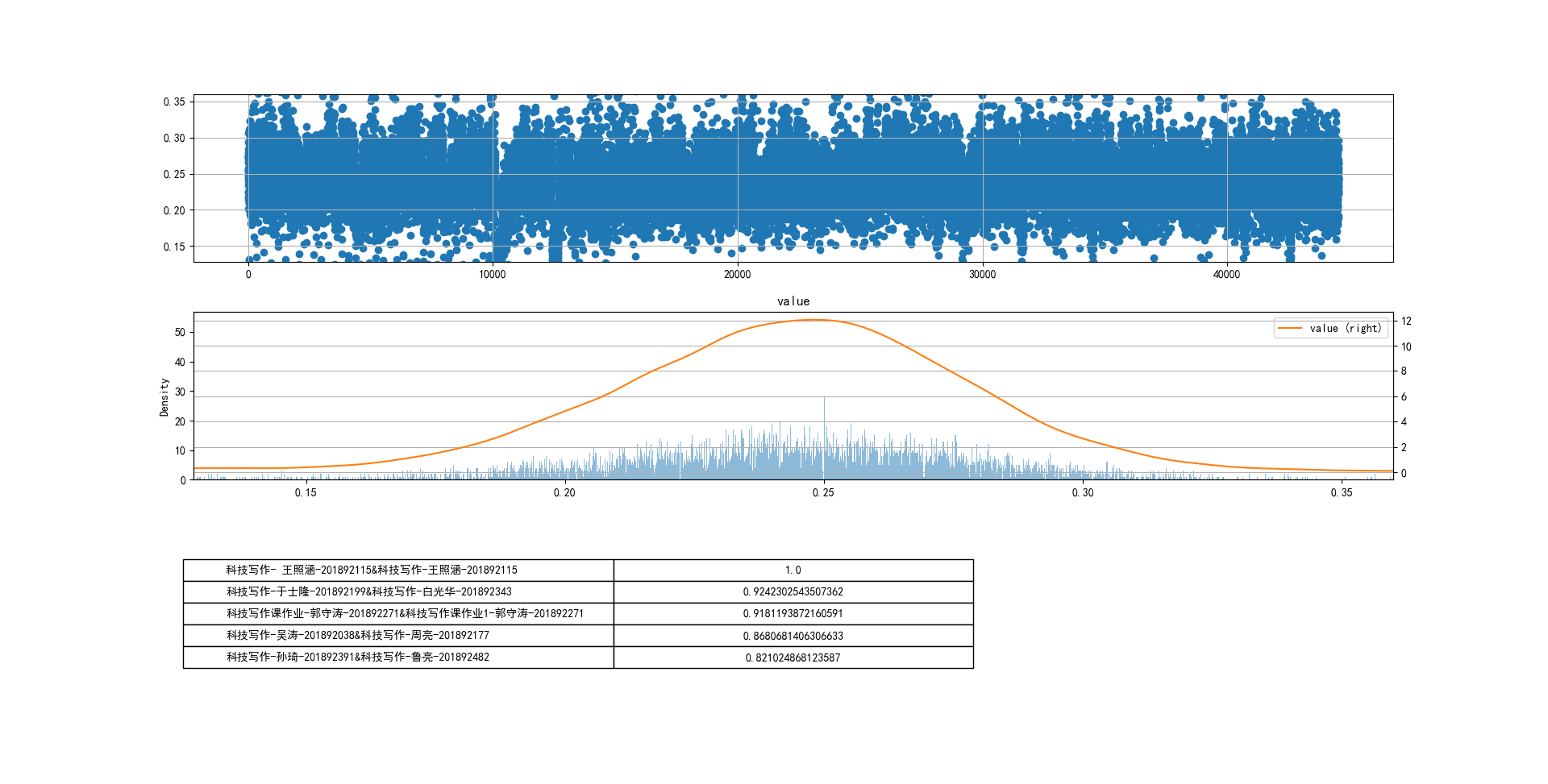
tf-idf余弦相似度
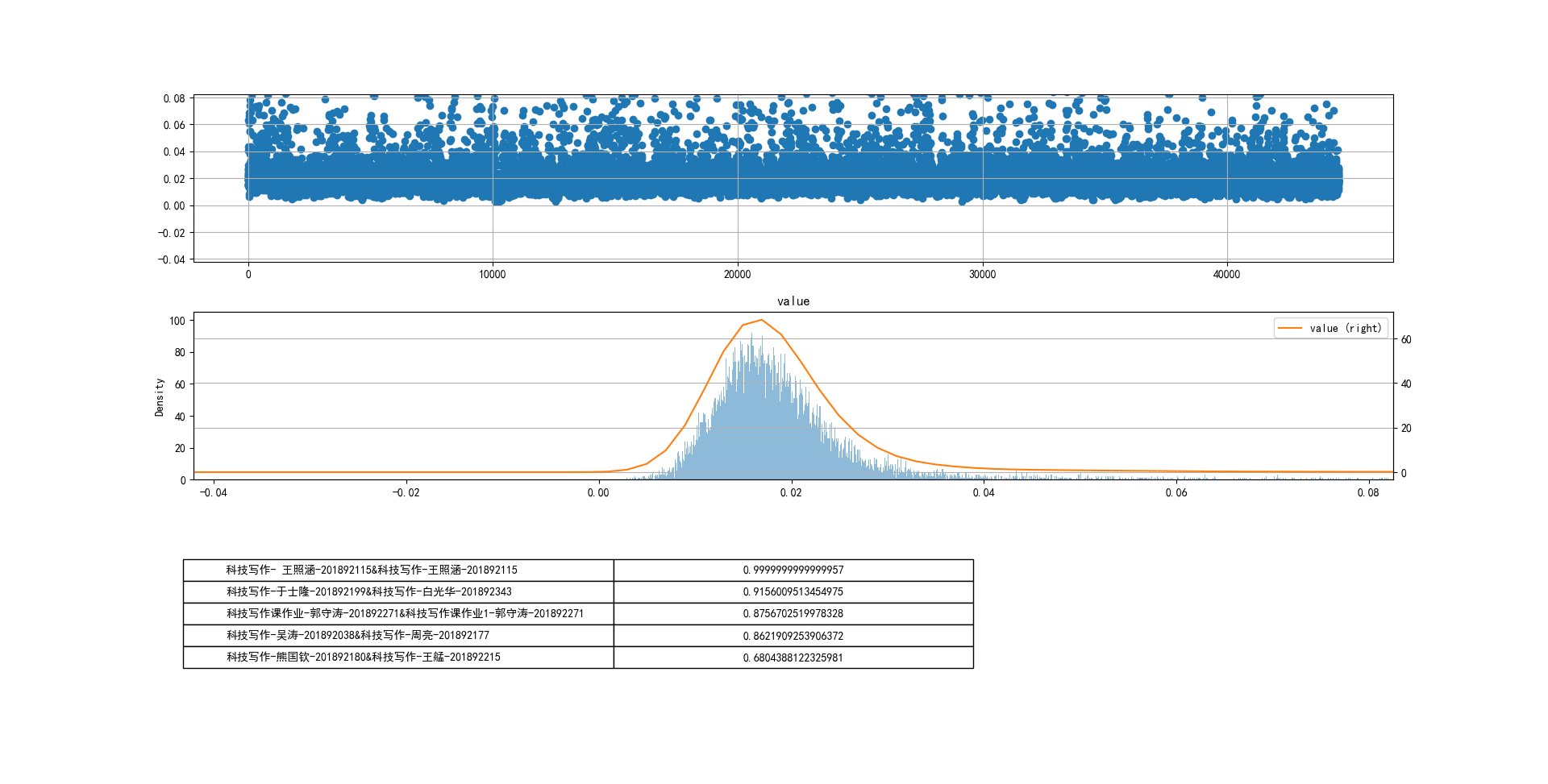
jaccard

 浙公网安备 33010602011771号
浙公网安备 33010602011771号