MySQL锁总结
锁分类
当多个事务或进程访问同一个资源时,为了保证数据的一致性就会用到锁机制,在MySQL中锁有多种不同的分类。
以操作粒度区分
行级锁、表级锁和页级锁
- 表级锁:每次操作锁住整张表。锁定的粒度大、开销小、加锁快;不会发生死锁,但发生锁冲突的概率极高,并发度最低,应用在InnoDB、MyISAM、BDB中;
- 行级锁:每次操作锁住一行数据。锁定的粒度小、开销大、加锁慢;会出现死锁,发生锁冲突的概率极低,并发度最高,应用在InnoDB中;
- 页级锁:每次锁定相邻的一组记录。锁定粒度、开销、加锁时间介于行级锁和表级锁之间;会出现死锁,并发度一般,应用在BDB中;
| 行锁 | 表锁 | 页锁 | |
|---|---|---|---|
| MyISAM | √ | ||
| BDB | √ | √ | |
| MyISAM | √ | √ |
以操作类型区分
读锁、写锁
- 读锁(S):共享锁,针对同一份数据,多个读操作可以同时进行不会互相影响;
- 写锁(X):排它锁,当前写操作没有完成时,会阻塞其他读和写操作;
为了允许行锁和表锁的共存,实现多粒度的锁机制,InnoDB还有两种内部使用的意向锁,这两种意向锁都是表锁:
- 意向读锁(IS)、意向写锁(IX):属于表级锁,S和X主要针对行级锁。在对表记录添加S或X锁之前,会先对表添加IS和IX锁,表明某个事务正在持有某些行的锁、或该事务准备去持有锁;意向锁存在是为了协调锁之间的关系,支持多粒度锁共存;
为什么意向锁是表级锁?
为了减少确认次数,提升性能:如果意向锁是行锁,需要遍历每一行去确认数据是否已经加锁;如果是表锁的话,只需要判断一次就知道有没有数据行被锁定;
意向锁是如何支持行级锁、表级锁共存的?
举例
- S锁:事务A对记录添加了S锁,可以对记录进行读取操作,不能做修改,其它事务可以对改记录追加S锁,但是不能追加X锁,追加X锁需要等记录的S锁全部释放;
- X锁:事务A对记录添加了X锁,可以对记录进行读和修改操作,其它事务不能对该记录做读和修改操作。
意向锁、共享锁和排它锁之间的兼容关系
| 事务A持有:X | IX | S | IS | |
|---|---|---|---|---|
| 事务B获取:X | 冲突 | 冲突 | 冲突 | 冲突 |
| IX | 冲突 | 兼容 | 冲突 | 兼容 |
| S | 冲突 | 冲突 | 兼容 | 兼容 |
| IS | 冲突 | 兼容 | 兼容 | 兼容 |
- 意向锁相互兼容,因为IX和IS只是表明申请更低层次的级别元素的X、S操作;
- 表级S和X、IX不兼容,因为上了表级S锁后,不允许其它事务再加X锁;
- 上了表级X锁后,会修改数据,所以表级X锁和 IS、IX、S、X(即使是行排他锁,因为表级锁定的行肯定包括行级锁定的行,所以表级X和IX、行级X)不兼容。
以操作性能区分
乐观锁、悲观锁
- 乐观锁:一般采用的方式是对数据记录版本进行对比,在数据更新提交时才会进行冲突检测,如果发现冲突了,则提示错误信息;
- 悲观锁:在对一条记录进行修改时,为了避免被其他人修改,在修改数据之前先锁定再修改的方式。共享锁和排它锁是悲观锁的不同实现。
InnoDB的行锁
行锁的实现原理
意向锁是InnoDB自动加的,不需要用户干预;对于 UPDATE 、DELETE 和 INSERT 语句,InnoDB会自动给涉及的数据集增加排他锁(X);对于普通的 SELECT 语句,InnoDB不会加任何锁;事务也可以通过以下语句显式的给记录集加共享锁 SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE 和排它锁 SELECT * FROM table_name WHERE ... FOR UPDATE 。
在InnoDB中,支持行锁和表锁,行锁又分为共享锁和排它锁。InnoDB行锁是通过对索引数据页上的记录加锁实现的。由于InnoDB行锁的实现特点,导致只有通过索引条件检索并且执行计划中真正使用到索引时InnoDB才会使用行锁 ;并且不论使用主键索引、唯一索引、普通索引,InnoDB都会使用行锁来进行加锁,否则InnoDB将使用表锁。由于InnoDB是针对索引加锁,而不是针对记录加锁,所以即使多个事务访问不同行的记录,但如果使用的是相同的索引,还是会出现锁冲突的情况,甚至出现死锁。
行锁的不同实现
行锁的主要实现有三种: Record Lock 、 Gap Lock 和 Next-Key Lock 。
- RecordLock:记录锁,锁定单个行记录的锁,RC和RR隔离级别支持。
- GapLock:间隙锁,锁定索引记录间隙,确保索引记录的间隙不变。范围锁,RR隔离级别支持。(加锁之后间隙范围内不允许插入数据,防止发生幻读)
- Insert Intention:插入意向锁,插入意向锁中虽然含有意向锁三个字,但是它不属于意向锁,而是属于间隙锁,在insert时产生;意向锁是表锁,而插入意向锁是行锁。
- Next-Key Lock:临键锁,它是记录锁和间隙锁的结合体,锁住数据的同时锁住数据前后范围。记录锁+范围锁,RR隔离级别支持。
insert 的加锁流程:
执行
insert之后,如果没有任何冲突,在show engine innodb status命令中是看不到任何锁的,这是因为insert加的是隐式锁。什么是隐式锁?隐式锁的意思就是没有锁!所以,根本就不存在先加插入意向锁,再加排他记录锁的说法,在执行
insert语句时,什么锁都不会加。当其他事务执行select ... lock in share mode时触发了隐式锁的转换。InnoDb 在插入记录时,是不加锁的。如果事务 A 插入记录且未提交,这时事务 B 尝试对这条记录加锁:事务 B 会先去判断记录上保存的事务 id 是否活跃,如果活跃的话,那么就帮助事务 A 去建立一个锁对象(排他记录锁),然后自身进入等待事务 A 状态,这就是所谓的隐式锁转换为显式锁。
结论:
- 执行
insert语句,判断是否有和插入意向锁冲突的锁,如果有,加插入意向锁,进入锁等待;如果没有,直接写数据,不加任何锁;- 执行
select ... lock in share mode语句,判断记录上是否存在活跃的事务,如果存在,则为insert事务创建一个排他记录锁,并将自己加入到锁等待队列;
MySQL使用间隙锁的目的
间隙锁的主要目的是为了防止幻读,其主要通过两个方面实现这个目的:
- 防止间隙内有新数据被插入
- 防止已存在的数据,更新成间隙内的数据
另外一方面,是为了满足其恢复和复制的需要。对于基于语句的日志格式的恢复和复制而言,由于MySQL的BINLONG是按照事务提交的先后顺序记录的,因此要正确恢复或者复制数据,就必须满足:在一个事务未提交前,其他并发事务不能插入满足其锁定条件的任何记录,根本原因还是不允许出现幻读。
锁规则
- 规则1:加锁的基本单位是临键锁(Next-key Lock)
- 规则2:查找过程中访问的对象才会加锁
- 优化1:索引上的等值查询,给唯一键加索引的时候,如果查询值存在,临键锁(Next-key Lock)会退化成记录锁(Record Lock);如果查询值不存在,会按照优化2进行优化
- 优化2:索引上的等值查询,向右遍历时且最近一个值不满足等值条件时,临键锁(Next-key Lock)会退化成间隙锁(Gap Lock)
- bug1:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
在mysql8.0.18及以上已经没有这个bug
锁结构
对不同记录加锁时,如果符合下边这些条件:
- 在同一个事务中进行加锁操作
- 被加锁的记录在同一个页面中
- 加锁的类型是一样的
- 等待状态是一样的
那么这些记录的锁就可以被放到一个锁结构中。
锁的兼容性
| 事务A持有:Gap | Insert Intention | Record | Next-Key | |
|---|---|---|---|---|
| 事务B获取:Gap | 兼容 | 兼容 | 兼容 | 兼容 |
| Insert Intention | 冲突 | 兼容 | 兼容 | 冲突 |
| Record | 兼容 | 兼容 | 冲突 | 冲突 |
| Next-Key | 兼容 | 兼容 | 冲突 | 冲突 |
从图中可以看出,横向为事务A拥有的锁,竖向为事务B想要获取的锁;举例: 如果前一个事务A 持有 gap 锁 或者 next-key 锁的时候,后一个事务B如果想要持有 Insert Intention 锁的时候会不兼容,出现锁等待。
加锁
SELECT ... FROM ...:InnoDB采用MVCC机制实现非阻塞读,对于普通的 SELECT 语句,InnoDB不加锁。SELECT ... FROM ... LOCK In SHARE MODE:显式追加共享锁,InnoDB会使用临键锁(Next-key Lock)进行处理,如果发现了唯一索引,可以降级为记录锁(RecordLock)。SELECT ... FROM ... FOR UPDATE:显式追加排它锁,InnoDB会使用Next-Key Lock锁进行处理,如果发现唯一索引,可以降级为RecordLock锁。UPDATE ... WHERE:InnoDB会使用临键锁(Next-key Lock)进行处理,如果扫描发现唯一索引,可以降级为记录锁(RecordLock)。DELETE ... WHERE:InnoDB会使用临键锁(Next-key Lock)进行处理,如果扫描发现唯一索引,可以降级为记录锁(RecordLock)。insert:InnoDB会在将要插入的那一行设置一个排他的记录锁(RecordLock)。
以 update t1 set name=‘XX’ where id=10 操作为例:
主键加锁
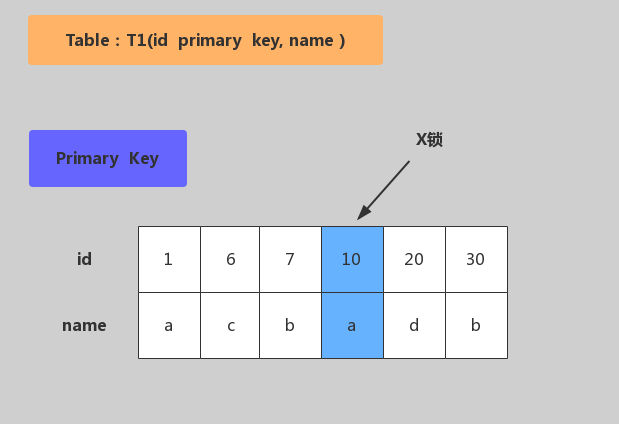
加锁行为:仅在id=10的主键索引记录上加X锁。
唯一键加锁
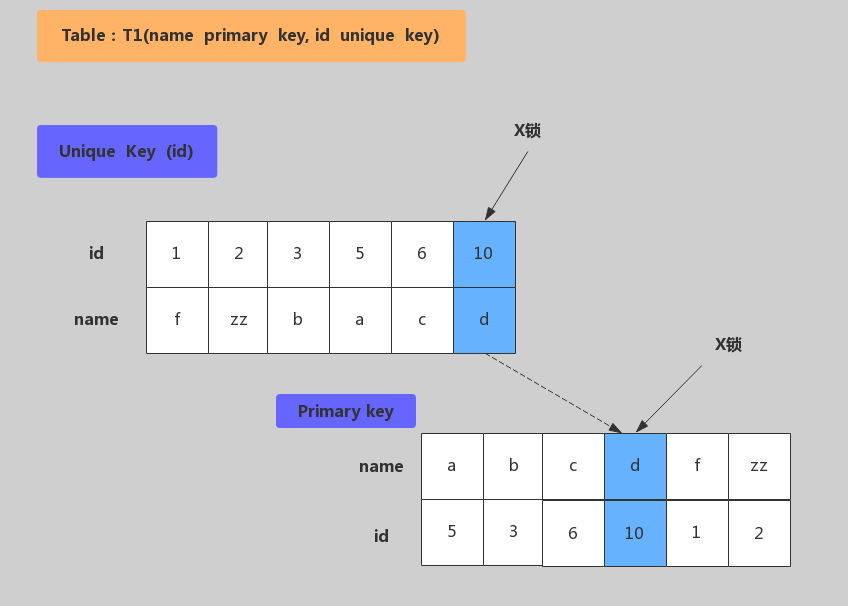
加锁行为:先在唯一索引id上加X锁,然后在id=10的主键索引记录上加X锁。
非唯一键加锁
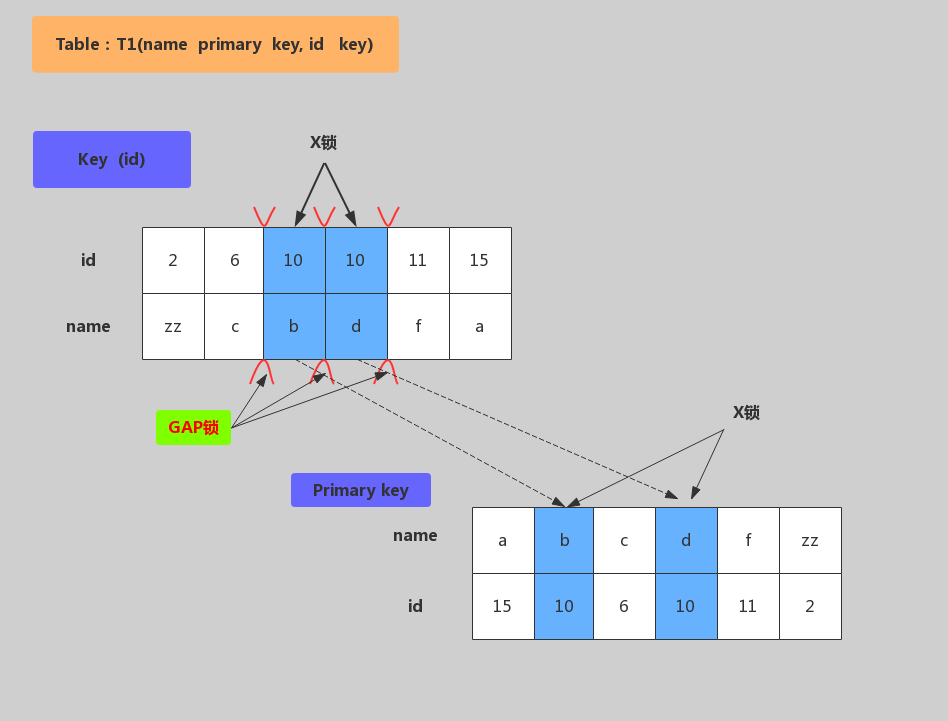
加锁行为:对满足id=10条件的记录和主键分别加X锁,然后在(6,c)-(10,b)、(10,b)-(10,d)、(10,d)(11,f)范围分别加Gap Lock。
无索引加锁
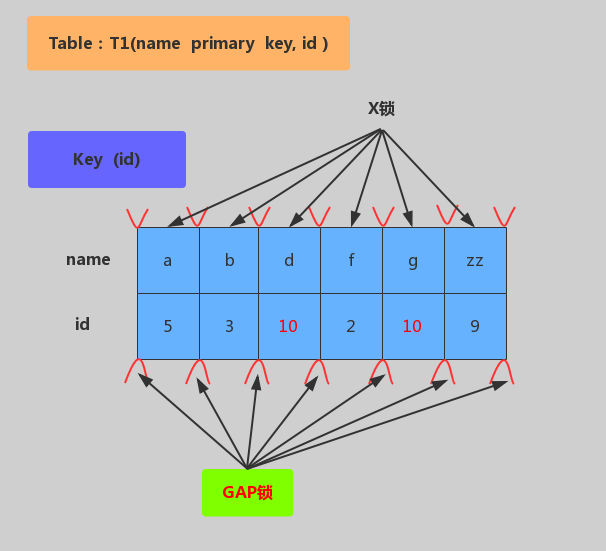
加锁行为:表里所有行和间隙都会加X锁。(当没有索引时,会导致全表锁定,因为InnoDB引擎 锁机制是基于索引实现的记录锁定)。
锁模拟
查看事务、锁的语句:
-- 当前运行的所有事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
-- 当前出现的锁
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
-- 锁等待的对应关系
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
输出结果解析:
-- 当前运行的所有事务 INFORMATION_SCHEMA.INNODB_TRX 表信息
root@127.0.0.1 : information_schema 13:29:05> desc innodb_trx ;
+—————————-+———————+——+—–+———————+——-+
| Field | Type | Null | Key | Default | Extra |
+—————————-+———————+——+—–+———————+——-+
| trx_id | varchar(18) | NO | | | |#事务ID
| trx_state | varchar(13) | NO | | | |#事务状态:
| trx_started | datetime | NO | | 0000-00-00 00:00:00 | |#事务开始时间;
| trx_requested_lock_id | varchar(81) | YES | | NULL | |#innodb_locks.lock_id
| trx_wait_started | datetime | YES | | NULL | |#事务开始等待的时间
| trx_weight | bigint(21) unsigned | NO | | 0 | |#
| trx_mysql_thread_id | bigint(21) unsigned | NO | | 0 | |#事务线程ID
| trx_query | varchar(1024) | YES | | NULL | |#具体SQL语句
| trx_operation_state | varchar(64) | YES | | NULL | |#事务当前操作状态
| trx_tables_in_use | bigint(21) unsigned | NO | | 0 | |#事务中有多少个表被使用
| trx_tables_locked | bigint(21) unsigned | NO | | 0 | |#事务拥有多少个锁
| trx_lock_structs | bigint(21) unsigned | NO | | 0 | |#
| trx_lock_memory_bytes | bigint(21) unsigned | NO | | 0 | |#事务锁住的内存大小(B)
| trx_rows_locked | bigint(21) unsigned | NO | | 0 | |#事务锁住的行数
| trx_rows_modified | bigint(21) unsigned | NO | | 0 | |#事务更改的行数
| trx_concurrency_tickets | bigint(21) unsigned | NO | | 0 | |#事务并发票数
| trx_isolation_level | varchar(16) | NO | | | |#事务隔离级别
| trx_unique_checks | int(1) | NO | | 0 | |#是否唯一性检查
| trx_foreign_key_checks | int(1) | NO | | 0 | |#是否外键检查
| trx_last_foreign_key_error | varchar(256) | YES | | NULL | |#最后的外键错误
| trx_adaptive_hash_latched | int(1) | NO | | 0 | |#
| trx_adaptive_hash_timeout | bigint(21) unsigned | NO | | 0 | |#
+—————————-+———————+——+—–+———————+——-+
-- 当前出现的锁 INFORMATION_SCHEMA.INNODB_LOCKS 信息
root@127.0.0.1 : information_schema 13:28:38> desc innodb_locks;
+————-+———————+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+————-+———————+——+—–+———+——-+
| lock_id | varchar(81) | NO | | | |#锁ID
| lock_trx_id | varchar(18) | NO | | | |#拥有锁的事务ID
| lock_mode | varchar(32) | NO | | | |#锁模式
| lock_type | varchar(32) | NO | | | |#锁类型
| lock_table | varchar(1024) | NO | | | |#被锁的表
| lock_index | varchar(1024) | YES | | NULL | |#被锁的索引
| lock_space | bigint(21) unsigned | YES | | NULL | |#被锁的表空间号
| lock_page | bigint(21) unsigned | YES | | NULL | |#被锁的页号
| lock_rec | bigint(21) unsigned | YES | | NULL | |#被锁的记录号
| lock_data | varchar(8192) | YES | | NULL | |#被锁的数据
+————-+———————+——+—–+———+——-+
-- 锁等待的对应关系 INFORMATION_SCHEMA.INNODB_LOCK_WAITS 信息
root@127.0.0.1 : information_schema 13:28:56> desc innodb_lock_waits;
+——————-+————-+——+—–+———+——-+
| Field | Type | Null | Key | Default | Extra |
+——————-+————-+——+—–+———+——-+
| requesting_trx_id | varchar(18) | NO | | | |#请求锁的事务ID
| requested_lock_id | varchar(81) | NO | | | |#请求锁的锁ID
| blocking_trx_id | varchar(18) | NO | | | |#当前拥有锁的事务ID
| blocking_lock_id | varchar(81) | NO | | | |#当前拥有锁的锁ID
+——————-+————-+——+—–+———+——-+
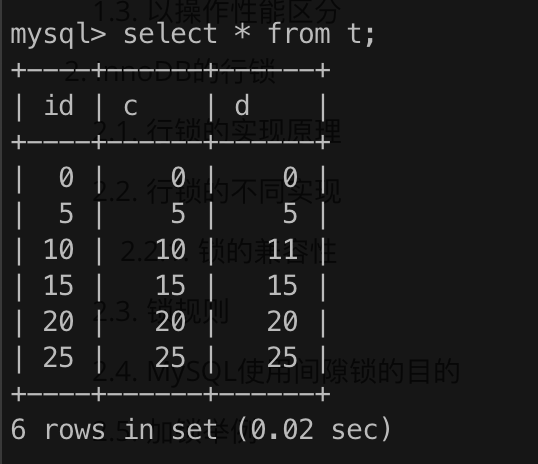
数据准备:
-- 建表语句
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE = InnoDB CHARSET = utf8 COLLATE utf8_bin;
-- 数据准备
INSERT INTO `t`(`id`, `c`, `d`) VALUES (0, 0, 0);
INSERT INTO `t`(`id`, `c`, `d`) VALUES (5, 5, 5);
INSERT INTO `t`(`id`, `c`, `d`) VALUES (10, 10, 11);
INSERT INTO `t`(`id`, `c`, `d`) VALUES (15, 15, 15);
INSERT INTO `t`(`id`, `c`, `d`) VALUES (20, 20, 20);
INSERT INTO `t`(`id`, `c`, `d`) VALUES (25, 25, 25);
锁举例
锁等待超时:ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
死锁:1213 Deadlock found when trying to get lock
等值查询间隙锁
| Session 1 | Session 2 | Session 1 |
|---|---|---|
| begin; UPDATE t SET d = d+1 WHERE id=7; |
||
| begin; INSERT INTO t VALUES(8,8,8); -- 阻塞 |
||
| begin; INSERT INTO t VALUES(11, 11, 11); -- 不阻塞 |
分析:
- 由于表T没有
id=7这条记录,加锁单位是Next-key Lock,事务1加锁范围是(5, 10],因为id=7是一个等值查询,根据优化规则,id=10不满足条件,Next-key Lock退化成Gap Lock,因此最终加锁范围是(5, 10)。 Session2想要向这个间隙中插入id=8的记录必须等待Session1事务提交后才可以。Session3想要插入id=11,不在加锁范围,所以可以插入成功。
这是如果有
Session4想要更新id=8的记录,是可以执行成功的,因为间隙锁之间互不冲突;
非唯一键等值锁
| Session 1 | Session 2 | Session 3 |
|---|---|---|
| begin; SELECT id FROM t WHERE c=5 LOCK IN SHARE MODE; |
||
| begin; INERT INTO t VALUES(7,7,7); -- 阻塞 |
||
| begin; UPDATE t SET d=d+1 WHERE id=5; -- 不阻塞 |
分析:
Session1给索引 c 上的 c=5 这一列加上读锁,根据规则1,加锁单位为Next-key Lock,因此会给 (0, 5] 区间加上Next-key Lock- 因为c是普通索引,所以访问 c=5 之后还要向右遍历,直到 c=10 停止,根据规则2访问到的都要加锁,所以加锁范围为 (5, 10] ,根据优化2,等值查询退化为
Gap Lock,变为 (5, 10),所以最终的加锁范围是 (0, 10); Session2想要插入 id=7 的记录,要等待Session1提交之后才可以成功插入,因为Session1的间隙范围是(5, 10);- 根据原则2,访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有加任何锁。所以
Session3的语句可以正常执行;
LOCK IN SHARE MODE; 只锁覆盖索引,FOR UPDATE; 会顺便锁上主键索引;
主键索引范围锁
select * from t where id=10 for update;
select * from t where id>=10 and id<11 for update;
对于以上两条SQL,加锁的范围不一致,第一条是id=10 的行锁,第二条是 (10, 15] 的
Next-key Lock
| Session1 | Session2 | Session3 |
|---|---|---|
| begin; select * from t where id>=10 and id<11 for update; |
||
| begin; insert into t values(9,9,9); -- 不阻塞 insert into t values(11,11,11); -- 阻塞 |
||
| update t set d=d+1 where id=15; -- 阻塞 |
分析:
Session1根据规则1,加锁单位为Next-key Lock,因为 id>=10 是范围查询,直到找到 id=15 停止,最终Session1的加锁范围是 (10, 15]Session3当去 update 一个存在的值是,给该行添加Record Lock,由于Record Lock和Next-key Lock不兼容,所以阻塞
如果
Session3更新一个 (10, 15) 的值,则会阻塞;
非唯一索引范围锁
| Session1 | Session2 | Session3 |
|---|---|---|
| begin; select * from t where c>=10 and c<11 for update; |
||
| begin; insert into t values(8,8,8); -- 阻塞 |
||
| begin; update t set d=d+1 where c=15; -- 阻塞 |
分析:
Session1给索引c加上了 (5,10], (10,15] 两个Next-key Lock;由于是范围查询,不触发优化,不会退化成间隙锁
非唯一索引等值锁for Update
数据准备:
DROP TABLE IF EXISTS `t`;
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
BEGIN;
INSERT INTO `t1` VALUES (2, 1);
INSERT INTO `t1` VALUES (3, 3);
INSERT INTO `t1` VALUES (4, 5);
INSERT INTO `t1` VALUES (5, 8);
INSERT INTO `t1` VALUES (6, 11);
COMMIT;
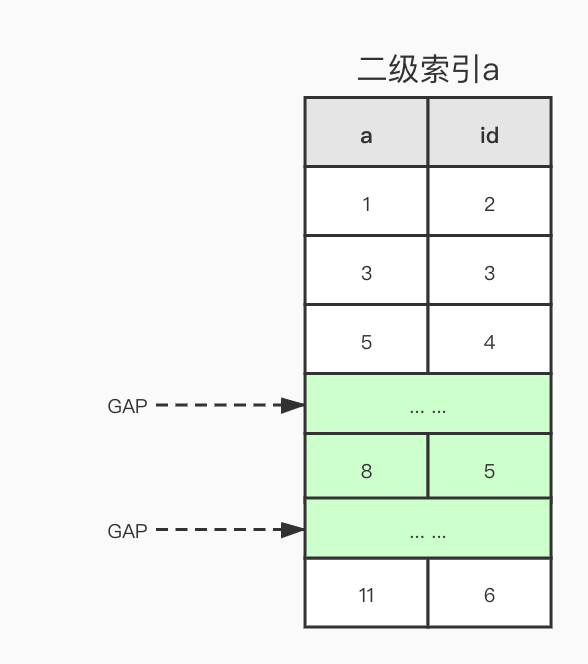
在表t中,a列有普通索引,所以可能锁定的范围有:
(-∞, 1], (1, 3], (3, 5], (5, 8], (8, 11], (11, +∞)
| session1 | session2 |
|---|---|
| begin; select * from t1 where a=8 for update; |
|
| begin; insert into t1 (a) values (12); -- 不会阻塞 insert into t1 (a) values (11); -- 不会阻塞 insert into t1 (a) values (4); -- 不会阻塞 insert into t1 (a) values (5); -- 阻塞 |
|
Session1 执行完成之后预期加锁范围为 (5, 8] 和 (8, 11],由于锁优化策略,退化成间隙锁,范围变成 (5, 8] 和 (8, 11) ,也就是 (5, 11) ,插入12和4不会阻塞很好理解。但是 5不在锁的范围内,还是被锁上了
是因为如果索引值相同的话,会根据id进行排序加锁,所以最终的加锁范围是索引a的 (5, 4) 到 (11, 6) 的范围
死锁模拟
死锁模拟-场景1
AB BA操作问题
数据准备:
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`stu_num` int(11) DEFAULT NULL,
`score` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_uniq_stu_num` (`stu_num`),
KEY `idx_score` (`score`)
) ENGINE=InnoDB;
insert into t2(id, stu_num, score) values (1, 11, 111);
insert into t2(id, stu_num, score) values (2, 22, 222);
insert into t2(id, stu_num, score) values (3, 33, 333);
| Session1 | Session2 |
|---|---|
| begin; select * from t2 where id = 1 for update; |
|
| begin; select * from t2 where id = 2 for update; |
|
| select * from t2 where id = 2 for update; | |
| select * from t2 where id = 1 for update; -- Deadlock |
死锁模拟-场景2
S-lock 升级 X-lock
数据准备:
沿用简单场景1数据
| Session1 | Session2 |
|---|---|
| begin; SELECT * FROM t2 WHERE id = 1 LOCK IN SHARE MODE; |
|
| begin; DELETE FROM t2 WHERE id = 1; |
|
| DELETE FROM t2 WHERE id = 1; |
分析:
- Session1 获取到 S-Lock
- Session2 尝试获取到 X-Lock ,但是被 Session1 的S-Lock 阻塞
- Session1 想要获取到 X-Lock,本身拥有一个 S-Lock ,但是Session2 申请 X-Lock 在前,需要等待 Session2 释放之后才能提升到 X-Lock,两个事务造成资源争抢导致死锁
死锁模拟-场景3
数据准备:
create table t3(
id int not null primary key auto_increment,
a int not null ,
unique key ua(a)
) engine=innodb;
insert into t3(id,a) values(1,1),(5,4),(20,20),(25,12);
| Session 1 | Session 2 |
|---|---|
| insert into t3(id,a) values(26,10); | |
| insert into t3(id,a) values(30,10); | |
| insert into t3(id,a) values(40,9); |
分析:
事务一在插入时由于跟事务二插入的记录唯一键冲突,所以对 a=10 这个唯一索引加 S 锁(Next-key)并处于锁等待,事务二再插入 a=9 这条记录,需要获取插入意向锁(lock_mode X locks gap before rec insert intention)和事务一持有的 Next-key 锁冲突,从而导致死锁。
死锁模拟-场景4
| 事务1 | 事务2 |
|---|---|
| begin; | begin; |
| UPDATE t SET d = d+1 WHERE id=7; | |
| UPDATE t SET d = d+1 WHERE id=9; | |
| INSERT INTO t VALUES(8,8,8); | |
| INSERT INTO t VALUES(8,8,8); |
两条语句的执行计划:
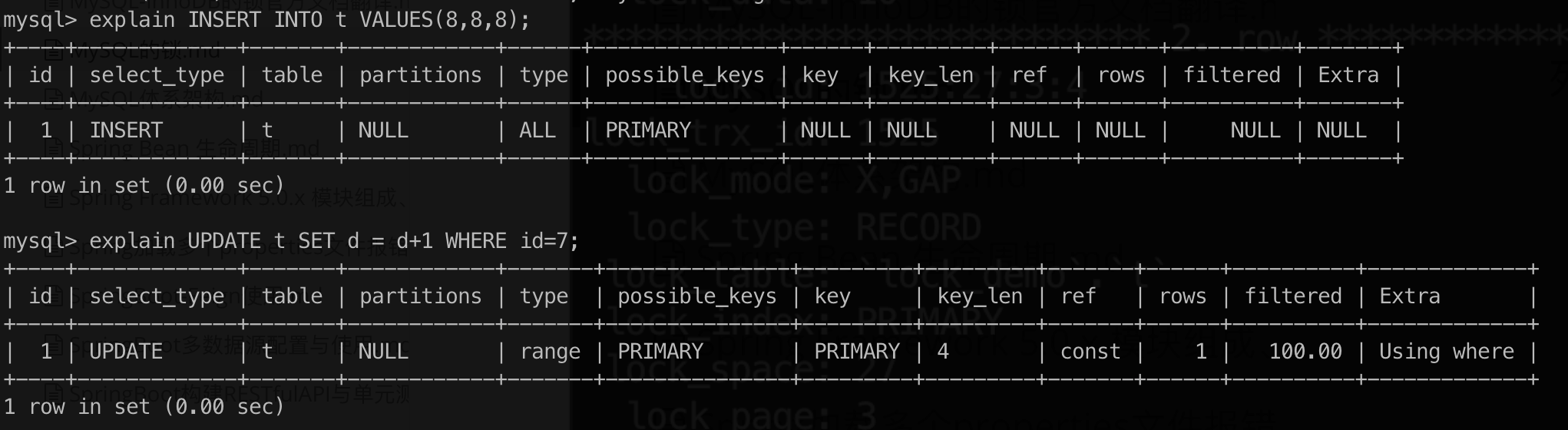
事务1执行 INSERT 时的锁情况:
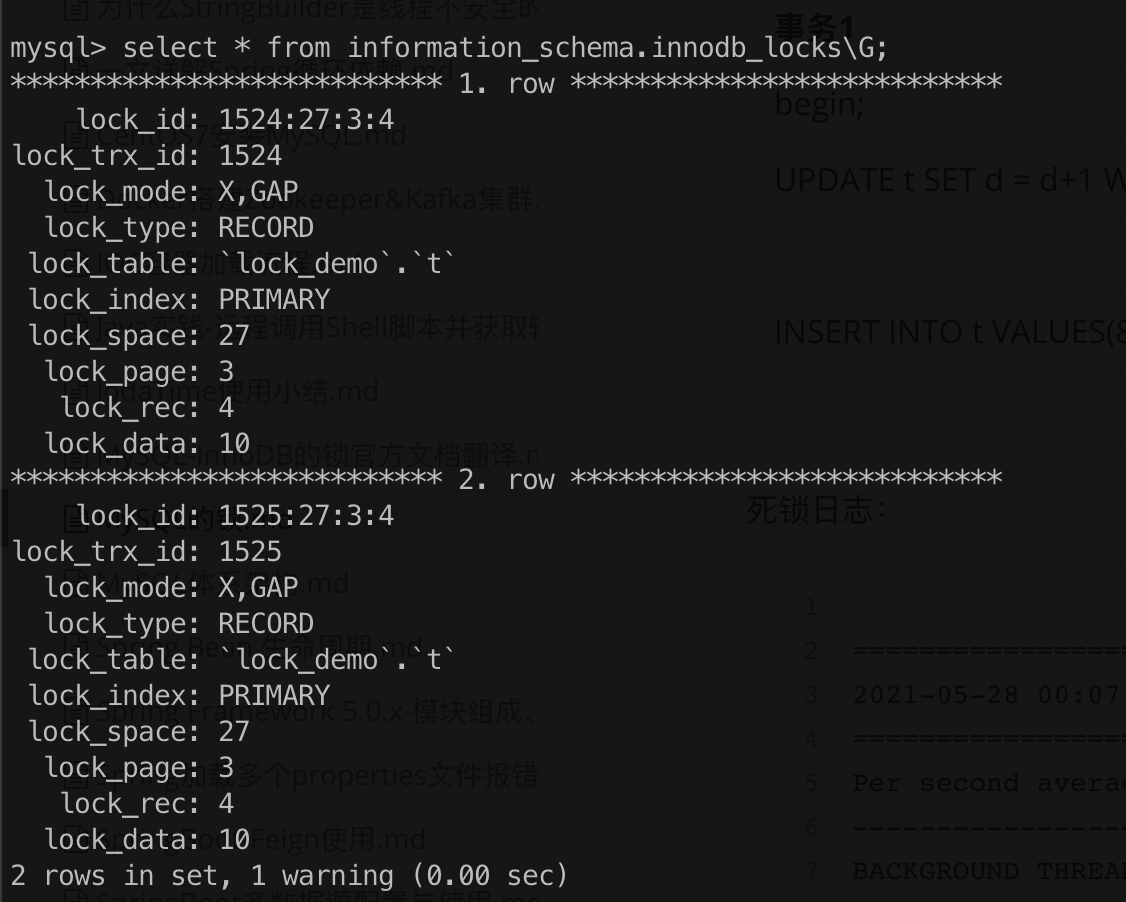
死锁日志:
------------------------
LATEST DETECTED DEADLOCK
------------------------
2021-05-28 00:07:00 0x70000a09a000
*** (1) TRANSACTION:
TRANSACTION 1518, ACTIVE 17 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 24, OS thread handle 123145470435328, query id 2673 localhost root update
INSERT INTO t VALUES(8,8,8)
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 27 page no 3 n bits 80 index PRIMARY of table `lock_demo`.`t` trx id 1518 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 0000000005d0; asc ;;
2: len 7; hex 2c0000014a01ca; asc , J ;;
3: len 4; hex 8000000a; asc ;;
4: len 4; hex 8000000b; asc ;;
*** (2) TRANSACTION:
TRANSACTION 1519, ACTIVE 12 sec inserting
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 25, OS thread handle 123145470713856, query id 2674 localhost root update
INSERT INTO t VALUES(8,8,8)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 27 page no 3 n bits 80 index PRIMARY of table `lock_demo`.`t` trx id 1519 lock_mode X locks gap before rec
Record lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 0000000005d0; asc ;;
2: len 7; hex 2c0000014a01ca; asc , J ;;
3: len 4; hex 8000000a; asc ;;
4: len 4; hex 8000000b; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 27 page no 3 n bits 80 index PRIMARY of table `lock_demo`.`t` trx id 1519 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 0000000005d0; asc ;;
2: len 7; hex 2c0000014a01ca; asc , J ;;
3: len 4; hex 8000000a; asc ;;
4: len 4; hex 8000000b; asc ;;
*** WE ROLL BACK TRANSACTION (2)
- UPDATE 的 WHERE 子句没有满足条件的记录,而对于不存在的记录 并且在RR级别下,UPDATE 加锁类型为间隙锁(Gap Lock),间隙锁(Gap Lock)之间是兼容的,所以两个事务都能成功执行 UPDATE;这里的gap范围是索引id列 (5, 10) 的范围。
- INSERT 时,其加锁过程为先在插入间隙上获取插入意向锁,插入数据后再获取插入行上的排它锁。又插入意向锁与间隙锁(Gap Lock)和临键锁(Next-key Lock)冲突,即一个事务想要获取插入意向锁,如果有其他事务已经加了(Gap Lock)或临键锁(Next-key Lock),则会阻塞。
- 场景中两个事务都持有间隙锁(Gap Lock),然后又申请插入意向锁,此时都被阻塞,循环等待造成死锁。
记录锁(LOCK_REC_NOT_GAP): lock_mode X locks rec but not gap
间隙锁(LOCK_GAP): lock_mode X locks gap before rec
Next-key 锁(LOCK_ORNIDARY): lock_mode X
插入意向锁(LOCK_INSERT_INTENTION): lock_mode X locks gap before rec insert intention
并不是在日志里看到 lock_mode X 就认为这是 Next-key 锁,因为还有一个例外:如果在 supremum record 上加锁,
locks gap before rec会省略掉,间隙锁会显示成lock_mode X,插入意向锁会显示成lock_mode X insert intention。
INSERT 语句,会尝试获取 lock mode S waiting 锁,这是为了检测唯一键是否重复,必须进行一次当前读,要加 S 锁。
INSERT 加锁分几个阶段:先检查唯一键约束,加 S 锁,再加插入意向锁,最后插入成功时升级为 X 锁。
-- 查看当前事务信息:
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
-- 查看当前锁定的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
-- 查看当前等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
站在巨人的肩膀上

参考链接:
MySQL官方团队:https://mysqlserverteam.com/innodb-data-locking-part-3-deadlocks/
MySQL锁官方文档:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html
死锁排查分析:https://www.aneasystone.com/archives/2018/04/solving-dead-locks-four.html
死锁场景罗列:https://github.com/aneasystone/mysql-deadlocks
插入意向锁和Next-Key引起的死锁:https://segmentfault.com/a/1190000019745324
透过源码分析INSERT加锁流程:https://www.aneasystone.com/archives/2018/06/insert-locks-via-mysql-source-code.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号