alt-opt and end2end
【使用】:如果要训练一个网络,可以在shell中输入:./experiments/scripts/faster_rcnn_alt_opt.sh 0 ZF pascal_voc
这样就指定了gpu编号,网络名称,数据集名称三个参数,就可以了
- #!/bin/bash
- # Usage:
- # ./experiments/scripts/faster_rcnn_alt_opt.sh GPU NET DATASET [options args to {train,test}_net.py]
- # DATASET is only pascal_voc for now
- #
- # Example:
- # ./experiments/scripts/faster_rcnn_alt_opt.sh 0 VGG_CNN_M_1024 pascal_voc \
- # --set EXP_DIR foobar RNG_SEED 42 TRAIN.SCALES "[400, 500, 600, 700]"
- set -x
- set -e
- export PYTHONUNBUFFERED="True"
- GPU_ID=$1
- NET=$2
- NET_lc=${NET,,}
- DATASET=$3
- array=( $@ )
- len=${#array[@]}
- EXTRA_ARGS=${array[@]:3:$len}
- EXTRA_ARGS_SLUG=${EXTRA_ARGS// /_}
- case $DATASET in
- pascal_voc)
- TRAIN_IMDB="voc_2007_trainval"
- TEST_IMDB="voc_2007_test"
- PT_DIR="pascal_voc"
- ITERS=40000
- ;;
- coco)
- echo "Not implemented: use experiments/scripts/faster_rcnn_end2end.sh for coco"
- exit
- ;;
- *)
- echo "No dataset given"
- exit
- ;;
- esac
- LOG="experiments/logs/faster_rcnn_alt_opt_${NET}_${EXTRA_ARGS_SLUG}.txt.`date +'%Y-%m-%d_%H-%M-%S'`"
- exec &> >(tee -a "$LOG")
- echo Logging output to "$LOG"
- time ./tools/train_faster_rcnn_alt_opt.py --gpu ${GPU_ID} \
- --net_name ${NET} \
- --weights data/imagenet_models/${NET}.v2.caffemodel \
- --imdb ${TRAIN_IMDB} \
- --cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
- ${EXTRA_ARGS}
- set +x
- NET_FINAL=`grep "Final model:" ${LOG} | awk '{print $3}'`
- set -x
- time ./tools/test_net.py --gpu ${GPU_ID} \
- --def models/${PT_DIR}/${NET}/faster_rcnn_alt_opt/faster_rcnn_test.pt \
- --net ${NET_FINAL} \
- --imdb ${TEST_IMDB} \
- --cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
- ${EXTRA_ARGS}
按行解析:
set -x
set -e
关于set可以参考链接点击打开链接,set -x :将后面执行的命令输出到屏幕,便于调试;set -e:如果命令返回值不是0则退出shell;
后面的这一段就是输入3个参数
GPU_ID=$1
NET=$2
NET_lc=${NET,,}
DATASET=$3
这一段没去纠结细节,反正大意就是获取剩下的参数,放在EXTRA_ARGS变量中
array=( $@ )
len=${#array[@]}
EXTRA_ARGS=${array[@]:3:$len}
EXTRA_ARGS_SLUG=${EXTRA_ARGS// /_}
然后就是根据出入的参数dataset,使用case语句选择执行,这里有3个分支,分别是pascal_voc,coco和其他
case $DATASET in
pascal_voc)
TRAIN_IMDB="voc_2007_trainval"
TEST_IMDB="voc_2007_test"
PT_DIR="pascal_voc"
ITERS=40000
;;
coco)
echo "Not implemented: use experiments/scripts/faster_rcnn_end2end.sh for coco"
exit
;;
*)
echo "No dataset given"
exit
;;
esac
再下面就是调用python脚本执行训练和测试了:
time ./tools/train_faster_rcnn_alt_opt.py --gpu ${GPU_ID} \
--net_name ${NET} \
--weights data/imagenet_models/${NET}.v2.caffemodel \
--imdb ${TRAIN_IMDB} \
--cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
${EXTRA_ARGS}
set +x
NET_FINAL=`grep "Final model:" ${LOG} | awk '{print $3}'`
set -x
time ./tools/test_net.py --gpu ${GPU_ID} \
--def models/${PT_DIR}/${NET}/faster_rcnn_alt_opt/faster_rcnn_test.pt \
--net ${NET_FINAL} \
--imdb ${TEST_IMDB} \
--cfg experiments/cfgs/faster_rcnn_alt_opt.yml \
${EXTRA_ARGS}
从上面可以看出,作者搞这么麻烦,其实一句话调用train_faster_rcnn_alt_opt.py就得了,费这么大劲,无语
比如训练,直接使用python脚本的话,如下输入:
./tools/train_faster_rcnn_alt_opt.py --gpu 0 --net_name ZF --weights data/imagenet_models/ZF.v2.caffemodel --imdb voc_2007_trainval --cfg experiments/cfgs/faster_rcnn_alt_opt.yml
faster_rcnn_end2end.sh源码分析
#!/bin/bash# Usage:# ./experiments/scripts/faster_rcnn_end2end.sh GPU NET DATASET [options args to {train,test}_net.py]# DATASET is either pascal_voc or coco.## Example:# ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG_CNN_M_1024 pascal_voc \# --set EXP_DIR foobar RNG_SEED 42 TRAIN.SCALES "[400, 500, 600, 700]"set -x #将后面执行的命令输出到屏幕set -e #如果命令的返回值不是0 则退出shellexport PYTHONUNBUFFERED="True" #和缓存有关系的一个变量,使得按顺序输出GPU_ID=$1 # 这一部分是读取命令信息,包括GPU的编号,网络类型,以及数据集类型等 NET=$2NET_lc=${NET,,}DATASET=$3array=( $@ ) len=${#array[@]}EXTRA_ARGS=${array[@]:3:$len}EXTRA_ARGS_SLUG=${EXTRA_ARGS// /_}case $DATASET in #根据输入数据类型,进行不同的处理,分为3种情况pascal_voc; coco; 错误类型 pascal_voc) TRAIN_IMDB="voc_2007_trainval" #定义相应的变量 TEST_IMDB="voc_2007_test" PT_DIR="pascal_voc" ITERS=70000 #定义迭代次数 ;; coco) # This is a very long and slow training schedule # You can probably use fewer iterations and reduce the # time to the LR drop (set in the solver to 350,000 iterations). TRAIN_IMDB="coco_2014_train" #定义相应的变量 TEST_IMDB="coco_2014_minival" PT_DIR="coco" ITERS=490000 #定义迭代次数 ;; *) echo "No dataset given" exit ;;esacLOG="experiments/logs/faster_rcnn_end2end_${NET}_${EXTRA_ARGS_SLUG}.txt.`date +'%Y-%m-%d_%H-%M-%S'`" #训练日志的存储路径exec &> >(tee -a "$LOG")echo Logging output to "$LOG"time ./tools/train_net.py --gpu ${GPU_ID} \ #加载网络训练的相关参数并进行训练 --solver models/${PT_DIR}/${NET}/faster_rcnn_end2end/solver.prototxt \ --weights data/imagenet_models/${NET}.v2.caffemodel \ --imdb ${TRAIN_IMDB} \ --iters ${ITERS} \ --cfg experiments/cfgs/faster_rcnn_end2end.yml \ ${EXTRA_ARGS}set +xNET_FINAL=`grep -B 1 "done solving" ${LOG} | grep "Wrote snapshot" | awk '{print $4}'` set -xtime ./tools/test_net.py --gpu ${GPU_ID} \ #测试过程 --def models/${PT_DIR}/${NET}/faster_rcnn_end2end/test.prototxt \ --net ${NET_FINAL} \ --imdb ${TEST_IMDB} \ --cfg experiments/cfgs/faster_rcnn_end2end.yml \ ${EXTRA_ARGS}
Sharing Features for RPN and Fast R-CNN
前面已经讨论如何训练提取proposal的RPN,分类采用Fast R-CNN。如何把这两者放在同一个网络结构中训练出一个共享卷积的Multi-task网络模型。
我们知道,如果是分别训练两种不同任务的网络模型,即使它们的结构、参数完全一致,但各自的卷积层内的卷积核也会向着不同的方向改变,导致无法共享网络权重,论文作者提出了三种可能的方式:
-
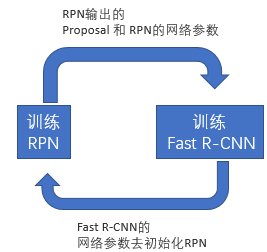
Alternating training:此方法其实就是一个不断迭代的训练过程,既然分别训练RPN和Fast-RCNN可能让网络朝不同的方向收敛,a)那么我们可以先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN。b) 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。
![]()
-
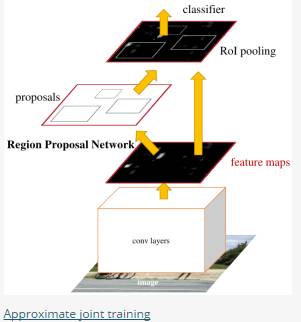
Approximate joint training:这里与前一种方法不同,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内,具体融合的网络结构如下图所示,可以看到,proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的"approximate"是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这个设置可以使backward时该网络层能得到一个解析解(closed results),并且相对于Alternating traing减少了25-50%的训练时间。(此处不太理解: 每次mini-batch的RPN输出的proposal box坐标信息固定,让Fast R-CNN的regressor去修正位置?)
![]()
-
Non-approximate training:上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”,但是此方法在paper中只是一笔带过,表示“This is a nontrivial problem and a solution can be given by an “RoI warping” layer as developed in [15], which is beyond the scope of this paper”,
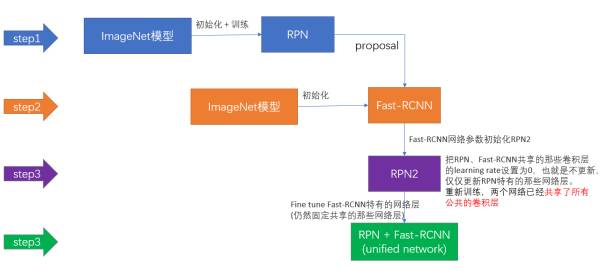
上面说完了三种可能的训练方法,可非常神奇的是作者发布的源代码里却用了另外一种叫做4-Step Alternating Training的方法,思路和迭代的Alternating training有点类似,但是细节有点差别:
-
第一步:用ImageNet模型初始化,独立训练一个RPN网络;
-
第二步:仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享;
-
第三步:使用第二步的Fast-RCNN网络参数初始化一个新的RPN网络,但是把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,此时,两个网络已经共享了所有公共的卷积层;
-
第四步:仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层,此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。
![]()
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号