三阶段训练超车《Autonomous Overtaking in Gran Turismo Sport Using Curriculum Reinforcement Learning 》
方法
A. 问题建模
高速度与低碰撞率是相互矛盾的
问题分成了 加速部分 和 超车部分
1 加速问题
加速奖励函数 如下
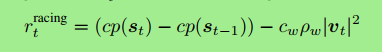
cp():投影到中心线的点
Cw:惩罚的权重 (这里是因为速度越高,碰撞率也就越高,所以代表了惩罚的权重)
Pw: 是不是撞墙了
公示中前两项激励小车跑快点,后一项激励小车避免撞墙
2 超车问题
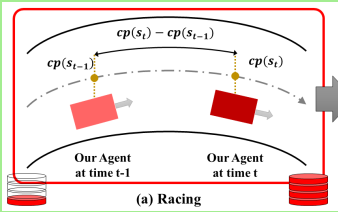
超车奖励函数 如下
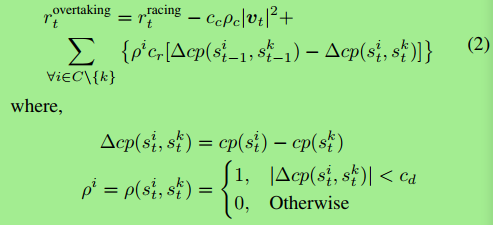
C集合:所有小车的集合
C集合中的{k}: 被RL控制的车
Cd:小车探测距离
Cr:平衡 超车与碰撞的 超参数
Pc:是不是撞车了
Cc:撞车的惩罚权重
Σ的内容: 激励小车超车 并且超过之后跑的更远 拉开距离
B.状态和动作空间
如图
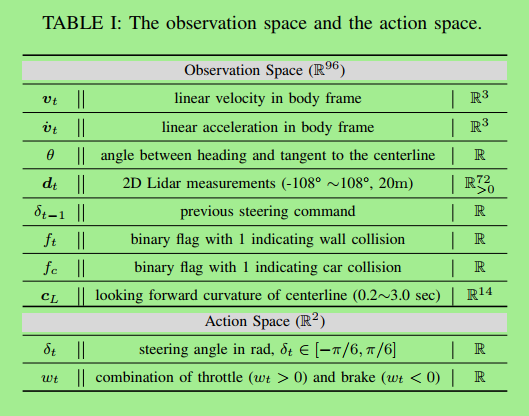
normalization 标准化是很重要的!!!
除了2D Lidar,其他所有全用的z-score标准化
2D Lidar用的min-max 标准化
2D Lidar: 72个雷达均匀分在-108°到108°之间 探测20米范围
动作空间:一个是方向 一个是 刹车和加速(合并成一个参数了)
C.三阶段式SAC
为什么三阶段?:
1 三阶段式强化训练
-
阶段一: 目的:训练高速运动 用加速奖励函数 训练
-
节段二: 目的:继续训练高速运动以及超车
加载阶段一的预训练模型
keep the old replay buffer
重新初始化 策略随机部分的超参数 保证足够的探索
超车奖励函数 训练
-
阶段三: 增加 惩罚的权重
用新样本
2 分布式采样策略
不知道具体怎么做的,论文意思就是4个模拟器,每个模拟器模拟20个小车,最终是4*80倍的速度采样
实验部分
A. 实验初始化
什么参数啊 网络啊 乱七八糟的
B. 阶段式训练的效果
嗯 确实有效果 有图证明
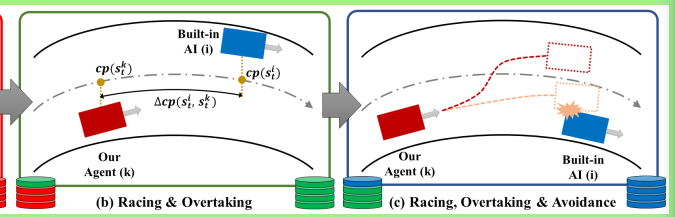
C. 超车表现的评估
We train three different agents using the overtaking reward with different hyperparameters and different training procedures for benchmark comparisons.
ForAgent1, we use only the first 2 stages that include single-car racing and multiple-car overtaking.
For Agent2, we use 3-stage training, where the second and the third stage has same collision weights of Cw = Cc= 0.005.
ForAgent3, we use 3-stage training, where the third stage has larger collision weights of Cw = cc = 0:01 than the second stage, which has collision
weights of Cw = cc = 0.005.
Agent3表现得最好
D. 超车表现详解
重点总结
问题分解为加速问题和超车问题
奖励函数在不同阶段不同
训练分三阶段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号