
PowerBI之DAX
计算表、计算字段和度量
计算表
返回值是一个二维表,比如下面返回一个只有一个时间列的表。时间是连续的,结束于6月。会扫描模型里的最大时间和最小时间,然后涵盖掉。
Due Date = CALENDARAUTO(6)计算列
单行内计算,非聚合。和我们的非聚合型计算字段类似。
Due Fiscal Year =
"FY"
& YEAR('Due Date'[Due Date])
+ IF(
MONTH('Due Date'[Due Date]) > 6,
1
)Due Month =
FORMAT('Due Date'[Due Date], "yyyy mmm")注意,单行内的计算,是不能跨表的,这点和我们是一样的。但是也允许通过RELATED 、 RELATEDTABLE和LOOKUPVALUE函数引用其他关联表的字段,比如下面这样,跨sales表和product两张表的字段:
Discount Amount =
(
Sales[Order Quantity]
* RELATED('Product'[List Price])
) - Sales[Sales Amount]度量
聚合后的字段称为度量。度量分为隐式度量和显式度量,用DAX创建的叫显示度量,在报表里展示的数值,叫隐式度量。显式度量是聚合的数值,类似于我们的聚合型计算字段、高级计算。尤其要提到的是,dax中,所有的高级计算,都是一个单独的度量,在建模时就创建好的。
在不麻烦的情况下,PowerBI推荐建模者在建模的时候就创建好显式度量,并且把隐式度量隐藏掉,防止做报表的人做出错误的聚合度量。
Revenue = SUM(Sales[Sales Amount])Context
Power BI最最最重要的概念,可以说,Power BI的一切计算,都是围绕Context进行的。
记住,在DAX中,是没有group by的概念的。pbi在计算一个单元格或者表达时的值时,总是根据这个单元格或表达时所处的上下文来执行计算的。

Row Context
行上下文的意思就是当前行,一般在非聚合型计算字段上使用这个概念,只在行内计算。或者在迭代函数上使用这个概念,代表内外循环的两个“当前行”。
需要注意的是,行上下文默认是不跨关联表的。比如你有Product 和Sales两张表通过order_id关联在一起,你在Product表上新建一个totalCost=sum(Sales[shipping_cost])计算字段,那么所有行上的totalCost都是同一个值:shipping_cost总计值。它不会根据Product表上的维度做分组聚合。如果需要的话,必须通过RELATED 之类的函数引用关联表字段,或者使用CALCULATE函数,让Row Context转为Filter Context(下面会讲)。
Query Context
查询上下文就是在报表查询时确定一个单元格的上下文,它由单元格上的行头列头、报表上的各类过滤器、切片器共同决定,然后单元格上的表达式(可能是一个最简单的聚合)就是在这些上下文中执行的。
Filter Context
这是所有context中最灵活最强大的。可以先把它看成是对数据的过滤条件,比如制作报表的时候,filter context就是添加的各种过滤器比如切片器、查询控件,更为强大的是,他可以在创建度量的时候,直接写到表达式中,影响表达式计算的范围。更重要的是,你可以通过各种函数去改变动态修改filter context。由于filter context的优先级比其他context都要高,所以它可以改变聚合、计算的结果。
context转移
指的是将Row Context 和Query Context转为Filter Context,可以直白的理解为图表上的单元格所在行的维度值(row context)变成了(转移成)该单元格上表达式执行时的过滤条件(filter context)。发生了转移之后,就能够通过修改函数去修改表达式的context了,这也是dax能够实现各种高级计算的秘诀。
写好dax的关键是掌握context
写好dax,尤其是复杂的dax,关键是在理解各种dax概念(context)的基础上,用好各种聚合函数和filter context修改函数。
1.理解filter context 的概念,以及它的作用机制
2.掌握何时以及用什么方法去改变filter context以获得正确的表达式结果
3.将各种表达式组合成更复杂的dax语句。
迭代函数
所有的聚合函数基本上都有一个迭代函数版本,函数名是聚合函名加上X后缀,比如 SUMX, COUNTX, MINX, MAXX 等等迭代函数是迭代一个表的所有行,他的声明如下:
SUMX( table , expression)
第一个入参是一个表或者能够返回一个表的表达式,第二个入参是一个表达式。迭代函数的做法是迭代table的每一行,并且在每一行的row context下执行expression,然后对每一行结果做入参执行聚合计算,得到一个出参。如果第一个入参是返回表的表达式,这个表达式是在当前filter context中执行的。
实际上,普通的聚合函数其实是迭代聚合的语法糖,在pbi中,简单聚合都会变成迭代聚合函数,比如sum聚合
Revenue = SUM(Sales[Sales Amount])其实是下面这个SUMX迭代函数的语法糖,它迭代了Sales表。
Revenue =
SUMX(
Sales,
Sales[Sales Amount]
)迭代函数的作用
创建复杂聚合的计算字段
Discount =
SUMX(
Sales,
Sales[Order Quantity]
* (
RELATED('Product'[List Price]) - Sales[Unit Price]
)
)这个表达式迭代了Sales表,并且以Sales表每一行的row context去计算单行的折扣量,最后汇总成总的折扣。需要注意的是,这里用了一个RELATED函数,这是因为pbi的row context默认是不能跨关联表的,如果不加这个函数,Product'[List Price]的值是不会受到Sales表当前行的维值约束的。
实现高阶聚合
比如想实现每类商品的平均利润,我们可能这样写
Revenue Avg =
AVERAGEX(
Sales,
Sales[Order Quantity] * Sales[Unit Price] * (1 - Sales[Unit Price Discount Pct])
)但这其实不对,他计算的是每一行的的平均利润,但是同一类商品可能会有很多很多行。我们真正想实现的,其实是先计算每一类商品的利润,然后相加起来,再除以商品种类。
Revenue Avg Order =
AVERAGEX(
VALUES('Product'[Product Type]),
[Revenue]
)这里的VALUES('Product'[Product Type])返回了所有的产品类型作为一个表,这个表只有一列,那就是产品类型,然后AVERAGEX函数迭代了这个表,在每一行(每种产品类型)以改行的row context去计算Revenue,最后算平均值。这里我们引用了Revenue度量,如果我们不是用引用,直接写成下面这样:
Revenue Avg Order =
AVERAGEX(
VALUES('Product'[Product Type]),
SUM(Sales[Sales Amount])
)结果也是不一样的,因为row context是不会跨关联表的,所以产品类型不会影响SUM(Sales[Sales Amount]),那么每一行的SUM(Sales[Sales Amount])结果都是一样的。如果要让产品类型作用与SUM(Sales[Sales Amount]),则需要让row context转移成SUM(Sales[Sales Amount])表达式的filter context
Revenue Avg Order =
AVERAGEX(
VALUES('Product'[Product Type]),
CALCULATE(SUM(Sales[Sales Amount]))
)calculate函数
calculate函数的用于修改filter context,实现强大的dax计算,他的基本格式如下
CALCULATE(<expression>, [[<filter1>], <filter2>]…)表达式部分必须返回一个具体的值(数值、文本、时间等)。
筛选器部分,每个筛选器必须返回bool值或者一个数据表,各个filter之间是and关系。
bool筛选器
bool筛选器比较简单,但是它有以下限制
- 每个filter只能引用一个列
- 不能引用度量
- 不能用聚合函数
举几个引用bool筛选器的例子:
Revenue Red = CALCULATE([Revenue], 'Product'[Color] = "Red")
Revenue Red or Blue = CALCULATE([Revenue], 'Product'[Color] IN {"Red", "Blue"})
Revenue Expensive Products = CALCULATE([Revenue], 'Product'[List Price] > 1000)表筛选器
表筛选器是一个表,可以直接用一个数据表充当表筛选器,但更常见的是用一个函数去创建表筛选器,最常用的函数就是FILTER函数。这是一个迭代器函数,有两个入参:表和过滤条件,申明如下
FILTER(<table>,<filter>)
FILTER函数会返回一个表,结构和传入的表一模一样,这个返回表的数据是经过filter表达式运算后为true的那些行。
比如下面这样,FILTER函数的返回结果就是Product表中所有满足售价大余成本2倍的行。
Revenue High Margin Products =
CALCULATE(
[Revenue],
FILTER(
'Product',
'Product'[List Price] > 'Product'[Standard Cost] * 2
)
)把这个表筛选器用于CALCULATE函数,Revenue的计算就是在筛选出来的Product行数据组成的Filter Context下计算的。
其实所有的过滤器最终都会化成表过滤器,即使是bool过滤器,在pbi的内部,也会转为表过滤器,bool过滤器可以看做是一种语法糖,只是为了便于使用。比如上面的bool过滤器例子,其实会转为一下表过滤器:
Revenue Red =
CALCULATE(
[Revenue],
FILTER(
'Product',
'Product'[Color] = "Red"
)
)筛选器表达式与Filter Context的关系
一共有两种情况:
- 如果Filter Context已经有了某一列(或者某个表)的约束条件,那么筛选器会直接覆盖掉这个列(或者表)的条件。
- 如果Filter Context没有了某一列(或者某个表)的约束条件,那么筛选器会把这列(或者表)的筛选条件加上。
比如上面写的Revenue Red度量,只计算红色的收入,那如果拖入颜色和Revenue Red,可以看到所有行的Revenue Red都是一样的,这是在Filter Context中因为发生了Color列上的条件覆盖,筛选器覆盖了行维度。

筛选器修改函数
除了写死筛选器求覆盖Filter Context中的条件,还可以用修改函数去修改Filter Context。
REMOVEFILTERS 可以删除Filter Context中的过滤条件,它可以从一个或多个列或从单个表的所有列中删除筛选器。在算总小计的时候,这个修改器函数很有用
KEEPFILTERS 可以在保留已有筛选条件的基础上增加新的筛选条件,比如把它用在Revenue Red中
Revenue Red =
CALCULATE(
[Revenue],
KEEPFILTERS('Product'[Color] = "Red")
)那么其他颜色行的数据就会为空,只有Red行有数据

原因是行维度的值作为Filter Context的条件和表达式中的条件是and关系,所以只有Color='Red' and Color='Red'为true,其他的行都是false。
USERELATIONSHIP是个非常有特色的函数,因为它体现了一个Power BI数据建模中的一个隐藏限制:表之间的关联关系只能是单个字段的关联,但是允许有多组关联关系(都是单字段关联),但只有其中一组为活跃关联,其他为非活跃关联。 如果要引用非活跃关联关系,那么就必须用USERELATIONSHIP函数指定一个非活跃关联。
Revenue Shipped =
CALCULATE (
[Revenue],
USERELATIONSHIP('Date'[DateKey], Sales[ShipDateKey])
)CROSSFILTER 能够影响关联关系的影响方向(维表到事实表,事实表到维表),甚至删除关联关系,更强大。
快捷计算
为了减轻写dax的难度,pbi提供了快捷方式创建度量,分成以下几类
分类聚合
分类聚合其实就是聚合的聚合,有下面这些

过滤
时间智能
前提:
必须要有时间表,时间表是一个连续的时间字段,且数据跨度满1年。
限制:
不支持自定义财年,否则需要自己写复杂的过滤函数。
同环比计算
Revenue YoY % =
VAR RevenuePriorYear = CALCULATE([Revenue], SAMEPERIODLASTYEAR('Date'[Date]))
RETURN
DIVIDE(
[Revenue] - RevenuePriorYear,
RevenuePriorYear
)xtd计算
Revenue YTD =
TOTALYTD([Revenue], 'Date'[Date], "6-30")计算拉新数
New Customers =
VAR CustomersLTD =
CALCULATE(
DISTINCTCOUNT(Sales[CustomerKey]),
DATESBETWEEN(
'Date'[Date],
BLANK(),
MAX('Date'[Date])
),
'Sales Order'[Channel] = "Internet"
)
VAR CustomersPrior =
CALCULATE(
DISTINCTCOUNT(Sales[CustomerKey]),
DATESBETWEEN(
'Date'[Date],
BLANK(),
MIN('Date'[Date]) - 1
),
'Sales Order'[Channel] = "Internet"
)
RETURN
CustomersLTD - CustomersPrior
快照计算(库存等等,其实就是最后一天聚合)
Stock on Hand =
CALCULATE(
SUM(Inventory[UnitsBalance]),
LASTDATE('Date'[Date])
)度量嵌套
在定义一个度量的DAX中,可以引用其他已经存在的度量,还能创建变量,这就使得DAX非常复杂了,像一门编程语言。
和LOD区别
DAX是基于context的,LOD是基于聚合的。举个例子,计算每个商品类型的平均售价。
DAX
在DAX中,可以直接创建 price average per product_type这样一个度量。
price average per product_type =
AVERAGEX(
KEEPFILTERS(VALUES('quickbi_test company_sales_record'[product_type])),
CALCULATE(SUM('quickbi_test company_sales_record'[price]))
)如果不想编辑,还可以通过快捷按钮方式直接创建常见的度量。

将度量拖到交叉表中,这时候PowerBI会根据row context,在表格上的每行都做一次品类平均值的计算。比如我们把area维度和度量price average per product_type拖入交叉表中,这时候row context是区域的值,比如第一行,就是在area=东北这个条件下,计算商品类型的售价均值。注意,度量的聚合方式是不可以更改的。

LOD
再看在LOD中,我们没有办法直接创建一个 price average per product_type度量,但是我们可以创建按照product_type聚合的计算字段,然后在使用该计算字段时,选择average聚合。
首先,创建 扩展 product_type聚合的计算字段sum price per product_type:
{INCLUDE [product_type]:SUM([price])}然后,把这个计算字段拖到交叉表中,并且选择 average聚合:
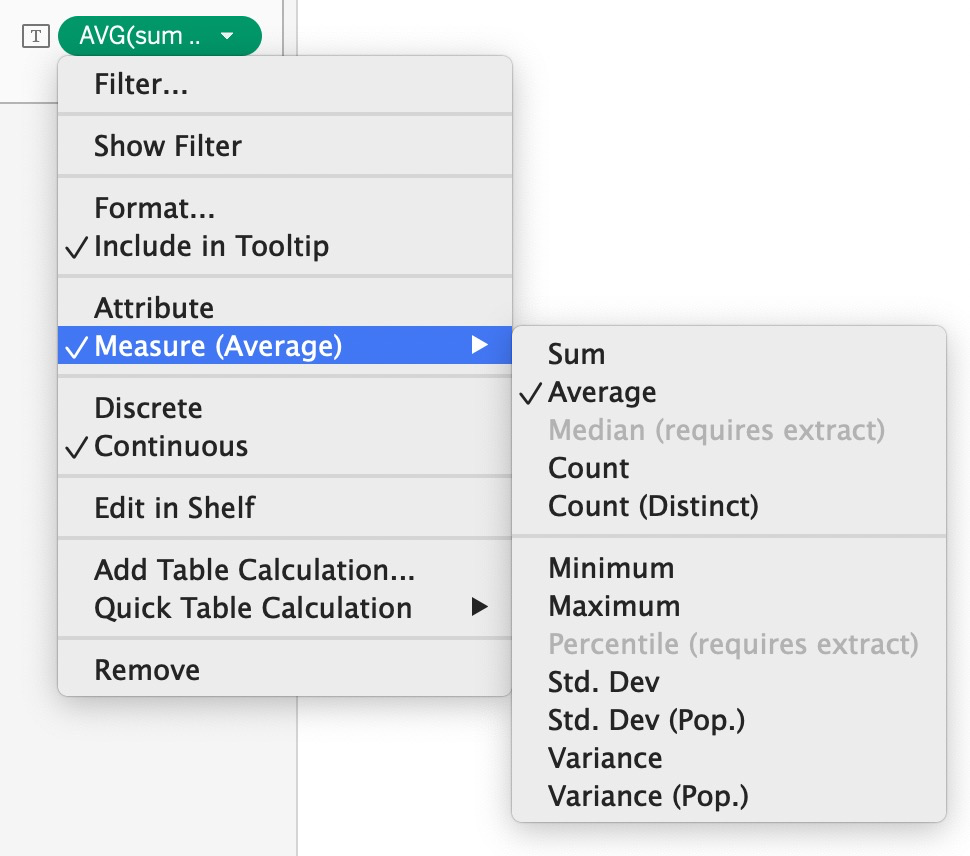
这里的计算逻辑就是:
首先,根据area和product_type两个维度做sum聚合。
然后,因为聚合的维度比图表上展示的多(也就是LOD聚合粒度比图表聚合粒度更细),这样每行下面会有多个聚合值,所以需要进行二次聚合,这时候根据所选的聚合方式average再聚合一次。
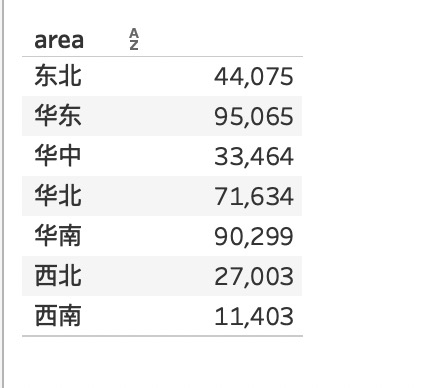
最终结果就是在每个区域下计算商品类型的售价均值,和DAX异曲同工。
可以看到,结果和在PowerBI中用dax创建的price average per product_type是一样的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号