

爬取酷狗近期热搜的歌曲
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:酷狗热搜歌曲
2.主题式网络爬虫爬取的内容与数据特征分析
内容:主要是爬取酷狗音乐热搜歌曲名和作者
数据特征分析:对酷狗TOP500上歌曲的时长做一个可视化表格
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:用requests库抓取页面信息,用BeautifulSoup库解析网页,创建excel存储数据进行数据分析
技术难点:excel的创建和相关系数散点图与建立回归方程
二、主题页面的结构特征分析
1.主题页面的结构与特征分析
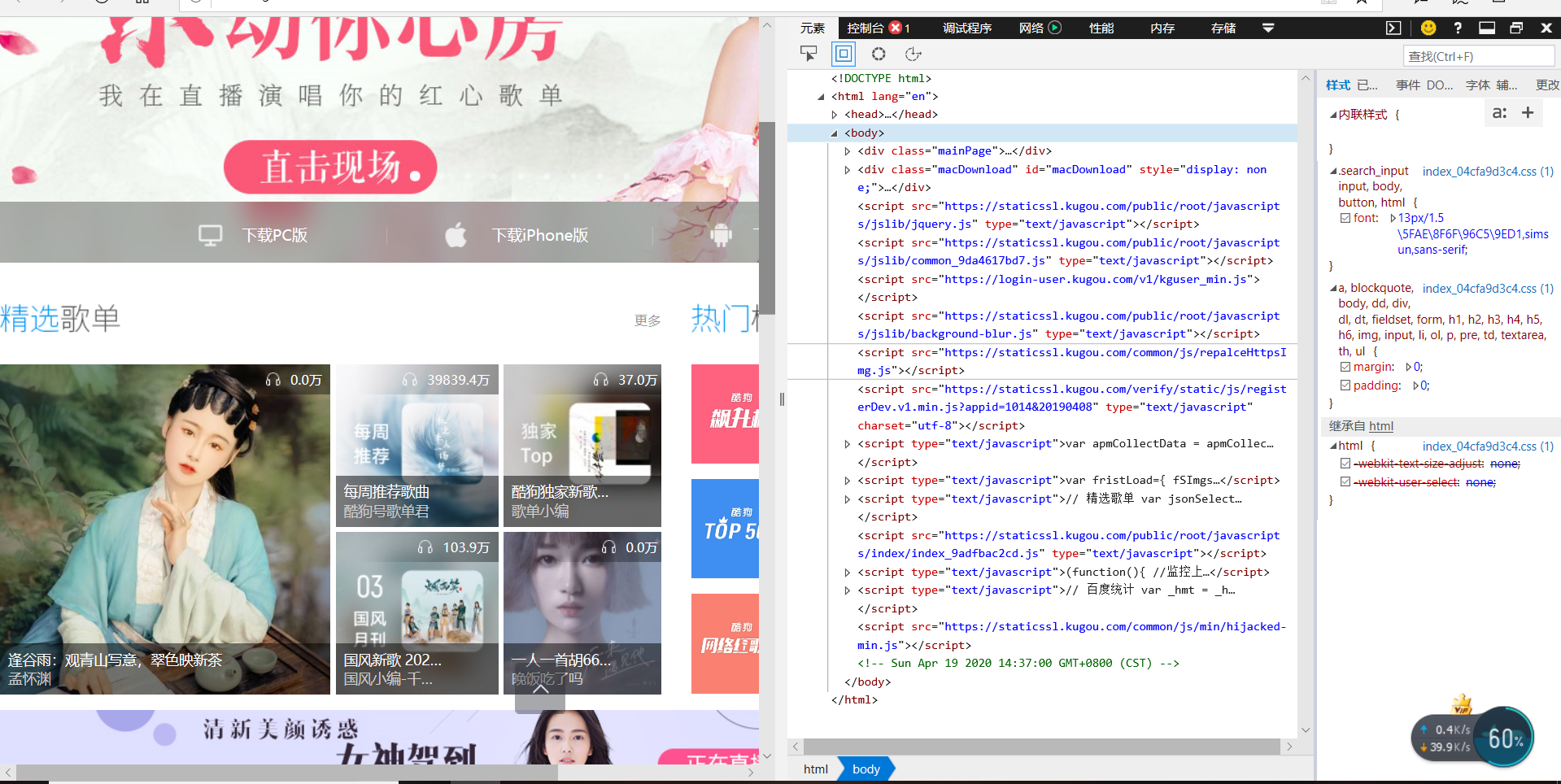
在浏览器中输入酷狗音乐官方网址https://www.kugou.com/,打开主页,然后点击榜单找到榜单页面,如图所示
三、网络爬虫程序设计
1.数据爬取与采集
爬取代码如下import requests
import time
import xlwt
from bs4 import BeautifulSoup
#创建Excel存储数据
class Spider:
def __init__(self):
self.workbook, self.worksheet = self.create_excel()
self.nums = 1
def create_excel(self):
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('Sheet1')
title = ['排名', '歌手和歌名', '播放时间']
for index, title_data in enumerate(title):
worksheet.write(0, index, title_data)
return workbook, worksheet
def get_html(self,url):
headers={'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',} # 爬虫请求头信息
response = requests.get(url, headers=headers)
if response.status_code == 200: # 如果请求状态值为200,则输出
return response.text
else:
return '产生异常'
def get_data(self,html):
soup = BeautifulSoup(html, 'lxml') # 用BeautifulSuop库解析网页
ranks = soup.find_all('span', class_='pc_temp_num') # 排名
names = soup.find_all('a', class_='pc_temp_songname') # 歌名和歌手
times = soup.find_all('span', class_='pc_temp_time') # 播放时间
# 打印信息
for r, n, t in zip(ranks, names, times): # 用zip函数
r = r.get_text().replace('\n', '').replace('\t', '').replace('\r', '')
n = n.get_text()
t = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '')
data = {'排名': r, '歌名-歌手': n, '播放时间': t}
self.worksheet.write(self.nums, 0, str(r))
self.worksheet.write(self.nums, 1, str(n))
self.worksheet.write(self.nums, 2, str(t))
self.nums += 1
def main(self,):
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1, 24)] # 用for循环
for url in urls:
print(url)
html = self.get_html(url)
self.get_data(html)
time.sleep(1)
self.workbook.save('data.xls')#存入所有信息后保存为data.xls
if __name__ == '__main__': # 程序执行时调用主程序main()
spider = Spider()
spider.main()

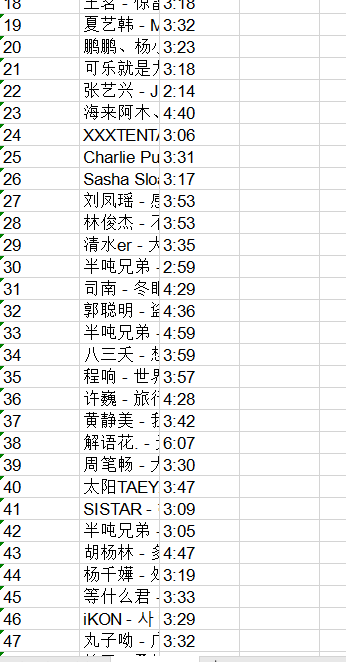
接下来进行数据清洗与处理
#数据清洗
print('\n====各列是否有缺失值情况如下:====')
print(df.isnull())
#统计空值情况
print(df.duplicated())
#查找重复值
print(df.isna().head())
#统计缺失值 # 得出结果为False则不为空值
print(df.describe())
#描述数据

完整代码如下:
import requests
import time
import xlwt
from bs4 import BeautifulSoup
#创建Excel存储数据
class Spider:
def __init__(self):
self.workbook, self.worksheet = self.create_excel()
self.nums = 1
def create_excel(self):
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('Sheet1')
title = ['排名', '歌手和歌名', '播放时间']
for index, title_data in enumerate(title):
worksheet.write(0, index, title_data)
return workbook, worksheet
def get_html(self,url):
headers={'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',} # 爬虫请求头信息
response = requests.get(url, headers=headers)
if response.status_code == 200: # 如果请求状态值为200,则输出
return response.text
else:
return '产生异常'
def get_data(self,html):
soup = BeautifulSoup(html, 'lxml') # 用BeautifulSuop库解析网页
ranks = soup.find_all('span', class_='pc_temp_num') # 排名
names = soup.find_all('a', class_='pc_temp_songname') # 歌名和歌手
times = soup.find_all('span', class_='pc_temp_time') # 播放时间
# 打印信息
for r, n, t in zip(ranks, names, times): # 用zip函数
r = r.get_text().replace('\n', '').replace('\t', '').replace('\r', '')
n = n.get_text()
t = t.get_text().replace('\n', '').replace('\t', '').replace('\r', '')
data = {'排名': r, '歌名-歌手': n, '播放时间': t}
self.worksheet.write(self.nums, 0, str(r))
self.worksheet.write(self.nums, 1, str(n))
self.worksheet.write(self.nums, 2, str(t))
self.nums += 1
def main(self,):
urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(str(i)) for i in range(1, 24)] # 用for循环
for url in urls:
print(url)
html = self.get_html(url)
self.get_data(html)
time.sleep(1)
self.workbook.save('data.xls')#存入所有信息后保存为data.xls
if __name__ == '__main__': # 程序执行时调用主程序main()
spider = Spider()
spider.main()
#数据清洗
print('\n====各列是否有缺失值情况如下:====')
print(df.isnull())
#统计空值情况
print(df.duplicated())
查找重复值
print(df.isna().head())
#统计缺失值 # 得出结果为False则不为空值
print(df.describe())
10 #描述数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号