第十二天
第三章:DataFrame入门
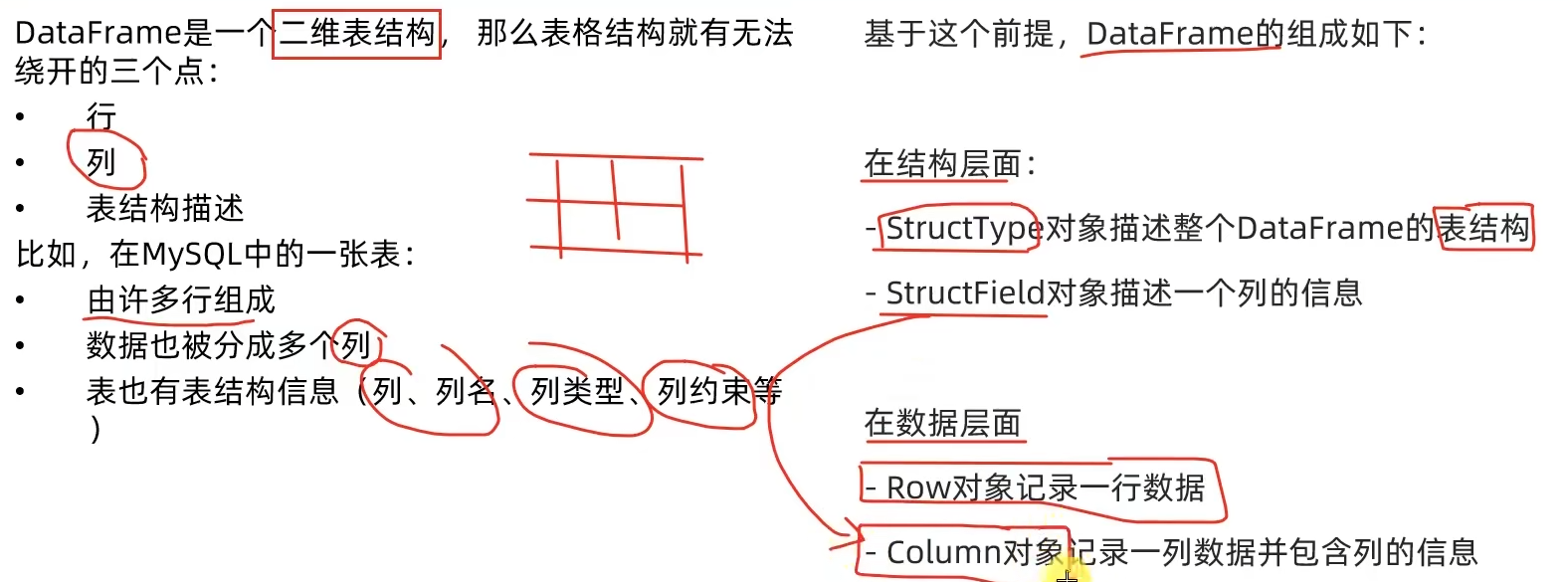
3.1 DataFrame的组成

3.2 DataFrame的代码构建

基于RDD方式1-通过createDataFrame方法
# coding:utf8
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 0. 构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
getOrCreate()
sc = spark.sparkContext
# 基于RDD转换成DataFrame
rdd = sc.textFile("../data/input/sql/people.txt").\
map(lambda x: x.split(",")).\
map(lambda x: (x[0], int(x[1])))
# 构建DataFrame对象
# 参数1 被转换的RDD
# 参数2 指定列名, 通过list的形式指定, 按照顺序依次提供字符串名称即可
df = spark.createDataFrame(rdd, schema=['name', 'age'])
# 打印DataFrame的表结构
df.printSchema()
# 打印df中的数据
# 参数1 表示 展示出多少条数据, 默认不传的话是20
# 参数2 表示是否对列进行截断, 如果列的数据长度超过20个字符串长度, 后续的内容不显示以...代替
# 如果给False 表示不阶段全部显示, 默认是True
df.show(20, False)
# 将DF对象转换成临时视图表, 可供sql语句查询
df.createOrReplaceTempView("people")
spark.sql("SELECT * FROM people WHERE age < 30").show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号