1.20总结
第六天。
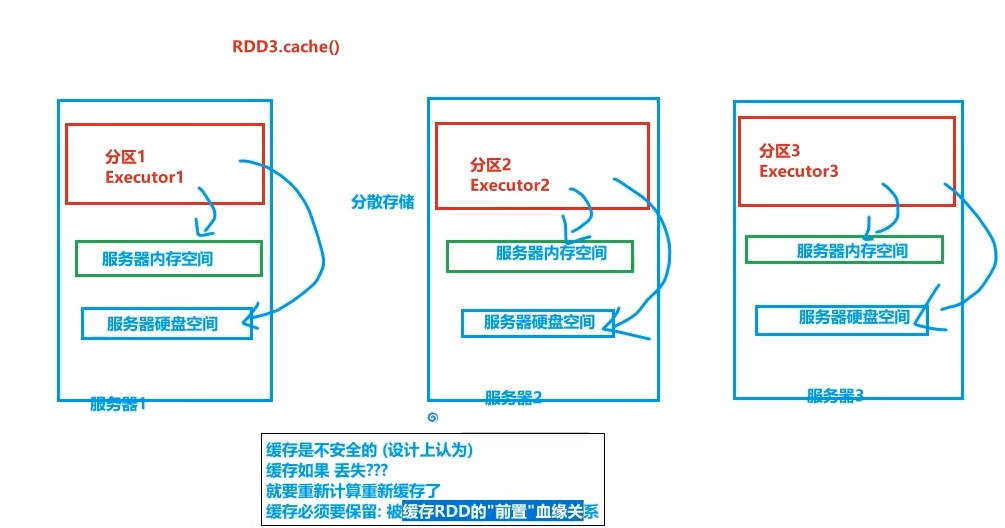
RDD的持久化
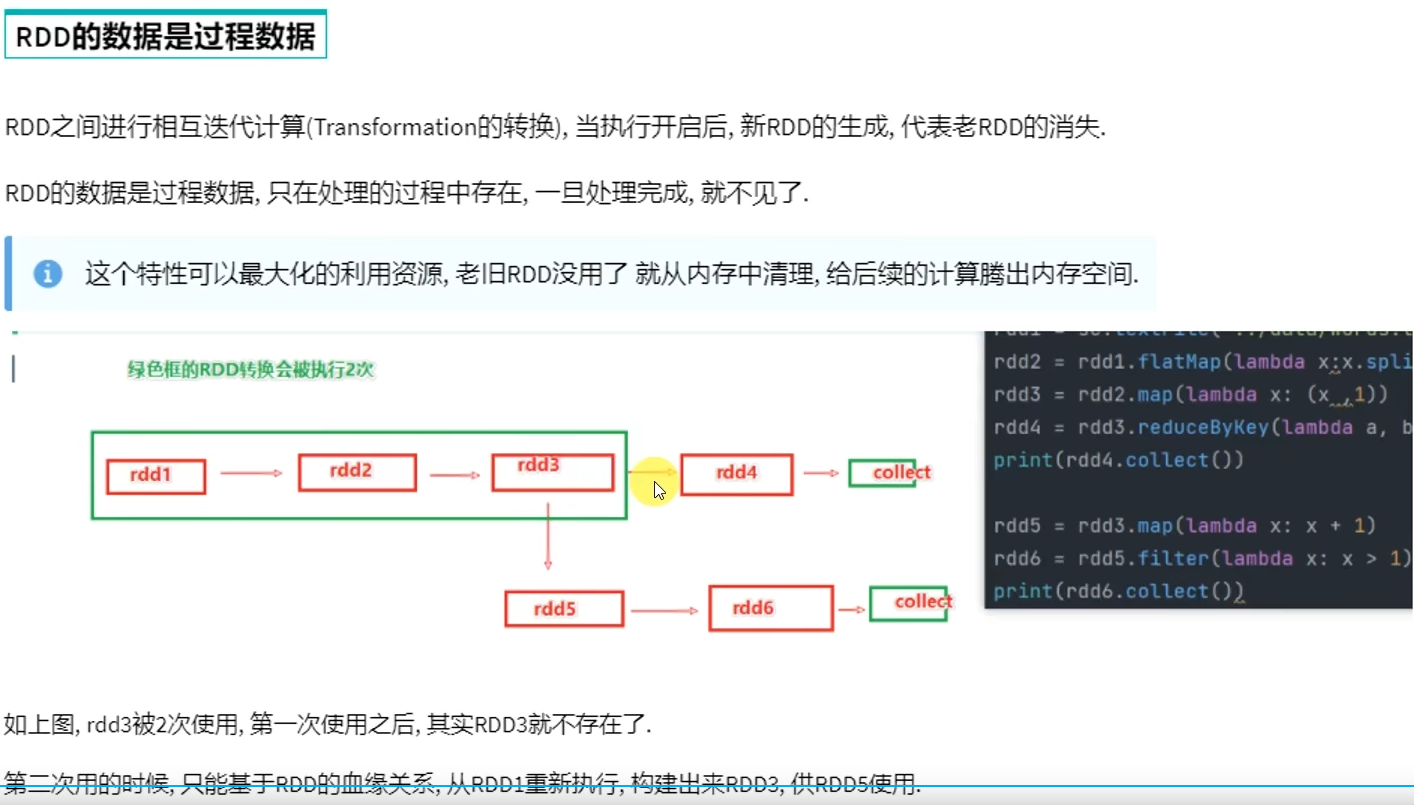
RDD的数据是过程数据
RDD缓存


# coding:utf8 import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd1 = sc.textFile("../data/input/words.txt") rdd2 = rdd1.flatMap(lambda x: x.split(" ")) rdd3 = rdd2.map(lambda x: (x, 1)) rdd3.cache() rdd3.persist(StorageLevel.MEMORY_AND_DISK_2) rdd4 = rdd3.reduceByKey(lambda a, b: a + b) print(rdd4.collect()) rdd5 = rdd3.groupByKey() rdd6 = rdd5.mapValues(lambda x: sum(x)) print(rdd6.collect()) rdd3.unpersist() time.sleep(100000)
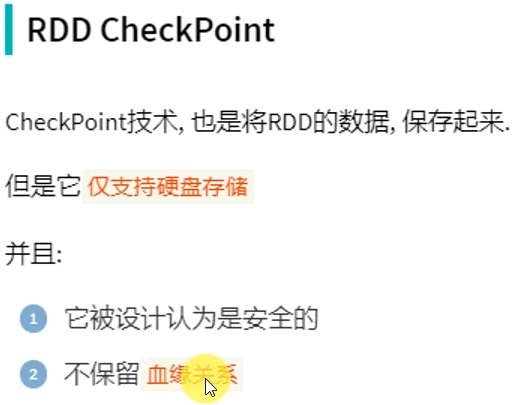
RDD CheekPoint

# coding:utf8 import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) # 1. 告知spark, 开启CheckPoint功能 sc.setCheckpointDir("hdfs://node1:8020/output/ckp") rdd1 = sc.textFile("../data/input/words.txt") rdd2 = rdd1.flatMap(lambda x: x.split(" ")) rdd3 = rdd2.map(lambda x: (x, 1)) # 调用checkpoint API 保存数据即可 rdd3.checkpoint() rdd4 = rdd3.reduceByKey(lambda a, b: a + b) print(rdd4.collect()) rdd5 = rdd3.groupByKey() rdd6 = rdd5.mapValues(lambda x: sum(x)) print(rdd6.collect()) rdd3.unpersist() time.sleep(100000)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号