1.19总结
第五天
对于算子部分总结在了昨天,今天不在进行复述。
继续上部分内容
RDD算子
分区操作算子
转换算子-mapPartitions
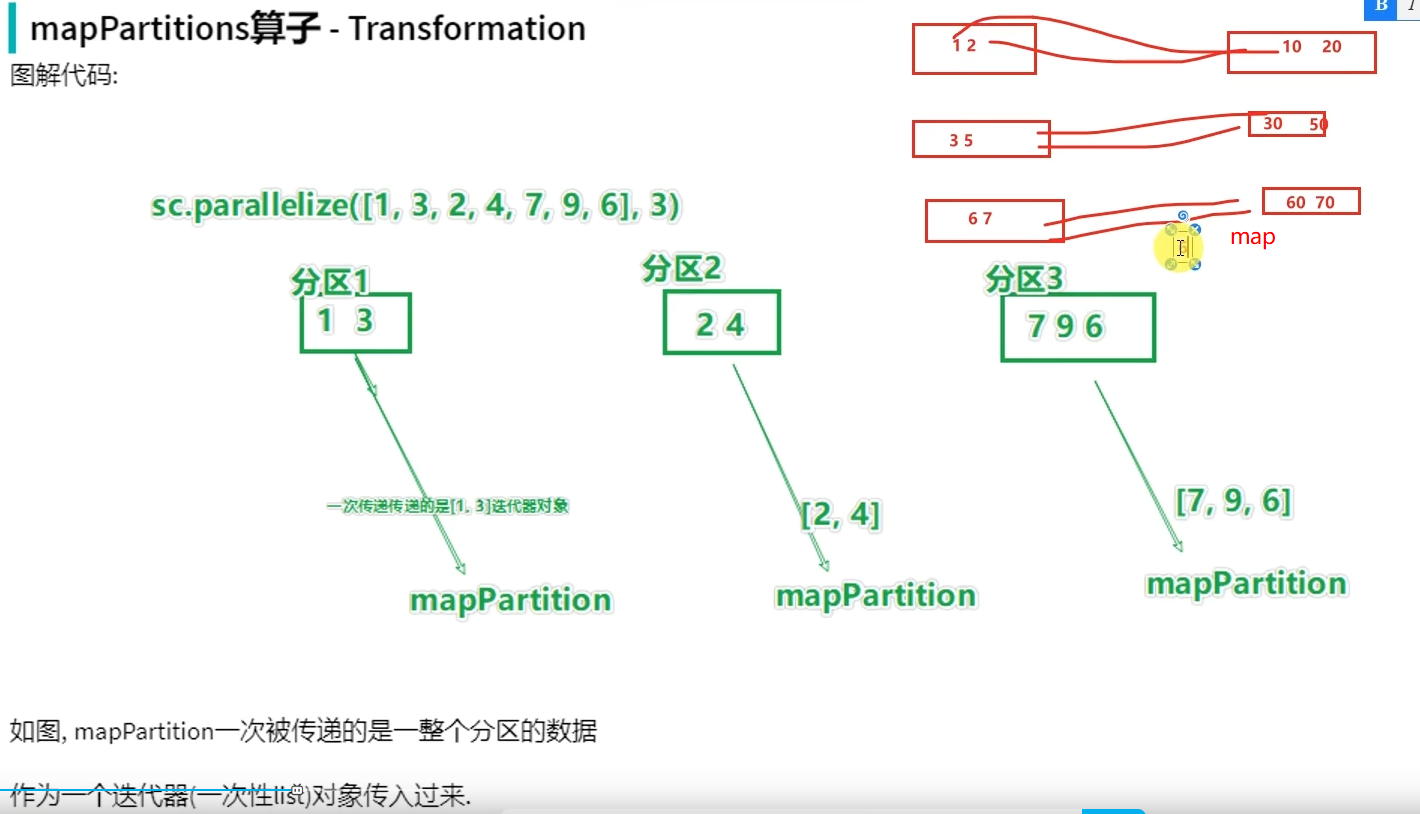
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3) def process(iter): result = list() for it in iter: result.append(it * 10) return result print(rdd.mapPartitions(process).collect())
mapPartitions并没有节省CPU执行层面的东西,但节省了网络管道IO开销,所以他的性能比map好。
Action算子-foreachPartition

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3) def process(iter): result = list() for it in iter: result.append(it * 10) print(result) rdd.foreachPartition(process)
转换算子-partitionBy

# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([('hadoop', 1), ('spark', 1), ('hello', 1), ('flink', 1), ('hadoop', 1), ('spark', 1)]) # 使用partitionBy 自定义 分区 def process(k): if 'hadoop' == k or 'hello' == k: return 0 if 'spark' == k: return 1 return 2 print(rdd.partitionBy(3, process).glom().collect())
转换算子-repartition
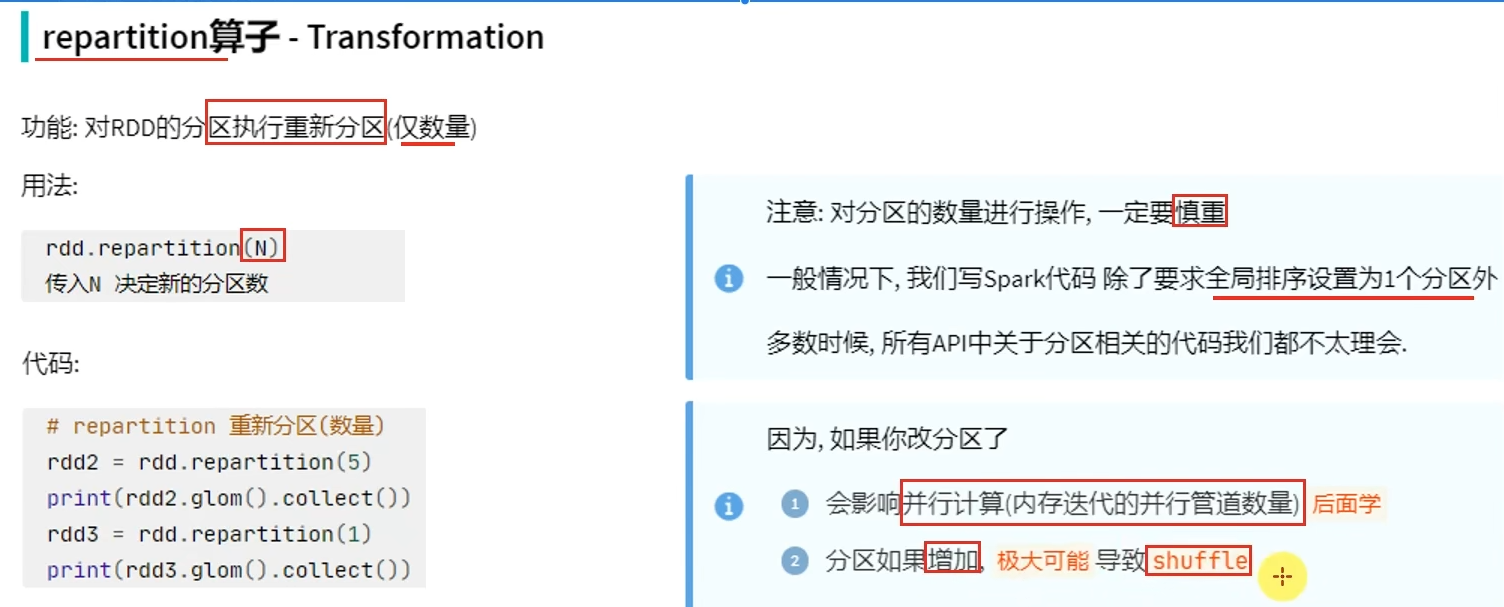
- shuffle是有状态计算,有状态计算涉及到状态的获取,就会导致性能下降。而没有shuffle,大部分都是无状态计算,可以并行执行,效果很快。
- coalesce有安全机制,当增加分区但没有设置shuffle参数为True时,分区并不会增加
- repartition底层调用的是coalesce,只是参数shuffle默认设置为True
# coding:utf8 from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName("test").setMaster("local[*]") sc = SparkContext(conf=conf) rdd = sc.parallelize([1, 2, 3, 4, 5], 3) # repartition 修改分区 print(rdd.repartition(1).getNumPartitions()) print(rdd.repartition(5).getNumPartitions()) # coalesce 修改分区 print(rdd.coalesce(1).getNumPartitions()) print(rdd.coalesce(5, shuffle=True).getNumPartitions())
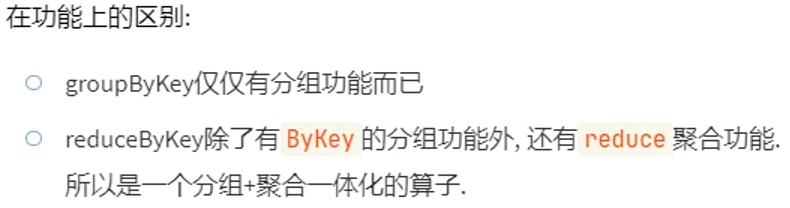
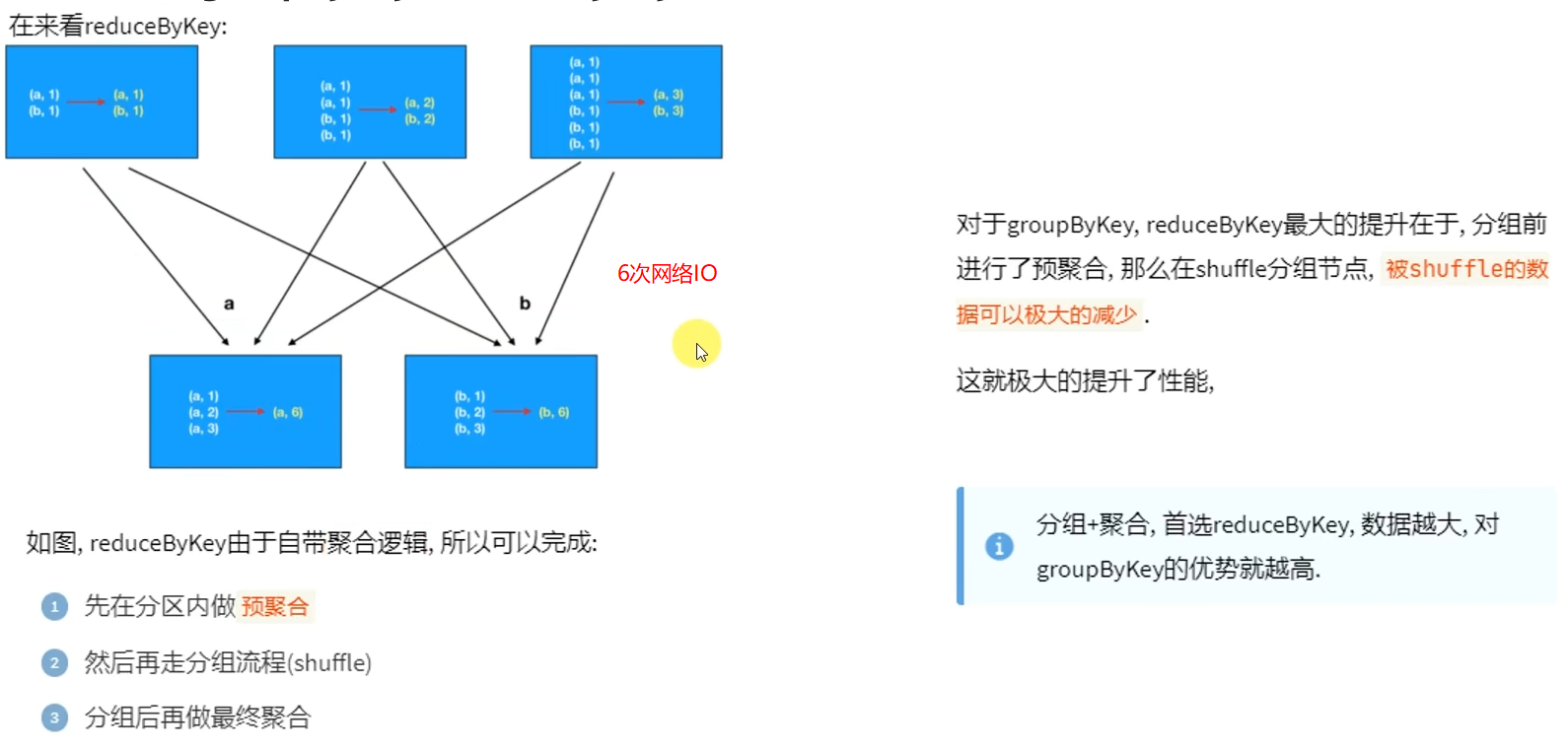
面试题&:groupByKey和reduceByKey的区别
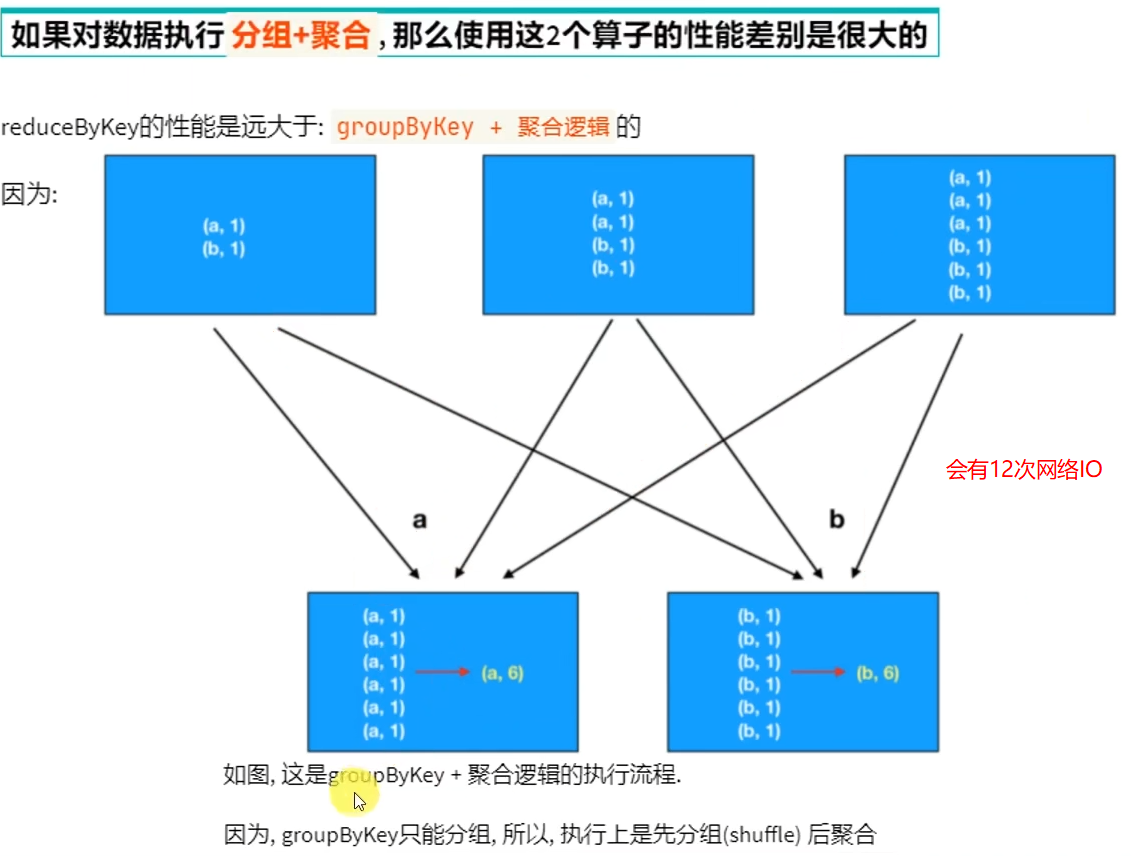

 浙公网安备 33010602011771号
浙公网安备 33010602011771号