

机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。机器学习利用数据或以往的经验,以此优化计算机程序的性能标准。
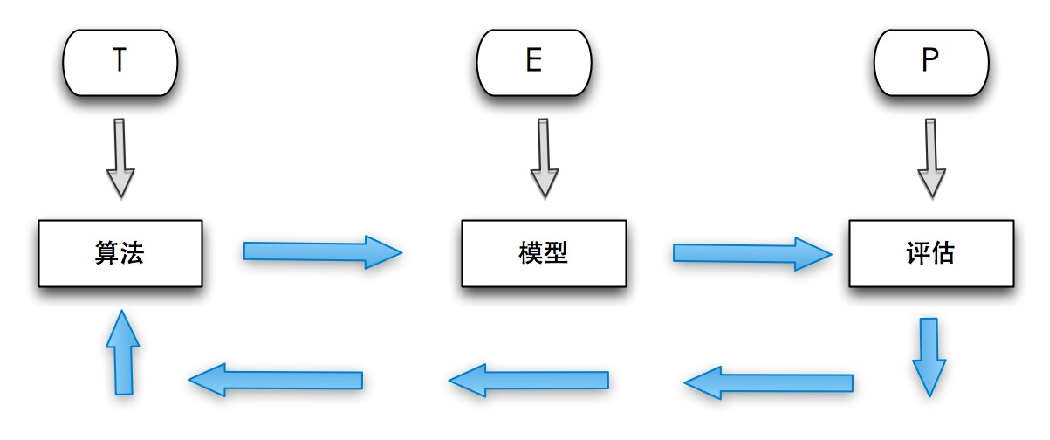
机器学习强调三个关键词:算法、经验、性能
Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现
开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程
spark-Shell的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果
MLlib
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作
MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的流水线(Pipeline)API,具体如下:
算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
特征化工具:特征提取、转化、降维和选择工具;
流水线(Pipeline):用于构建、评估和调整机器学习工作流的工具;持久性:保存和加载算法、模型和管道;
实用工具:线性代数、统计、数据处理等工具。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号