

本次学习学习了spark的安装和使用方法
运行代码
Spark shell本身就是一个Driver,里面包含main方法
进入shell界面
./bin/spark-shell -- master<master-url>
<master-url>:
local 使用一个CPU本地去运行SPARK:完全不并行 不加参数默认该模式
local[*] 使用逻辑CPU个数量的线程去本地SPRAK
local[K] 使用K个CPU的数量的线程去本地SPRAK
还有在集群上进行运行:...
退出: :quit
编写Spark独立应用程序
对于Scala编写的程序采用sbt/maven都可以进行打包
进行安装下载sbt:安装了大约3个小时吧,一开始报错找不到stat,换版本加载慢,最后换阿里源进行解决
启动:
./sbt sbtVersion
示例:
[atguigu@hadoop102 mycode]$ cd ~ [atguigu@hadoop102 ~]$ mkdir ./sparkapp [atguigu@hadoop102 ~]$ mkdir -p ./sparkapp/src/main/scala [atguigu@hadoop102 ~]$ cd ./sparkapp/src/main/scala/ [atguigu@hadoop102 scala]$ vim SimpleApp.scala
编写程序:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ object SimpleApp { def main(args: Array[String]): Unit = { val logFile = "file:///opt/module/spark/README.md" val conf = new SparkConf().setAppName("Simple Application") val sc = new SparkContext(conf) val logData = sc.textFile(logFile,2).cache() val numAs = logData.filter(line => line.contains("a")).count() val numBs = logData.filter(line => line.contains("b")).count() println("Line with a: %s,Line with b: %s".format(numAs,numBs)) } }
返回到与src同级的目录下,创建simple.sbt
[atguigu@hadoop102 ~]$ cd sparkapp/ [atguigu@hadoop102 sparkapp]$ ll 总用量 0 drwxrwxr-x. 3 atguigu atguigu 18 1月 20 11:01 src [atguigu@hadoop102 sparkapp]$ vim simple.sbt
写入内容:
name := "Simple Project" //名称 version := "1.0" scalaVersion := "2.12.15" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.0"
目录结构如下:
[atguigu@hadoop102 sparkapp]$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala ./simple.sbt
进行打包:
[atguigu@hadoop102 sparkapp]$ /usr/local/sbt/sbt package
打包完成后文件存在target目录下:生成的应用程序JAR包的位置为“/home/hadoop/sparkapp/target/XXX.jar”
运行:
./bin/spark-submit --class <main-class> //需要运行的程序的主类,应用程序的入口点 (object) --master <master-url> //Master URL,下面会有具体解释 --deploy-mode <deploy-mode> //部署模式 ... # other options //其他参数 <application-jar> //应用程序JAR包 [application-arguments] //传递给主类的主方法的参数
--master <master-url> 不写采用本地模式
[atguigu@hadoop102 spark]$ ./bin/spark-submit --class "SimpleApp" /home/atguigu/sparkapp/target/scala-2.12/simple-project_2.12-1.0.jar

入门示例 wordCount
进入shell界面:./bin/spark-shell
scala> val textFile = sc.textFile("file:///usr/local/spark/mycode/wordcount/word.txt") scala> val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) scala> wordCount.collect()
结果:
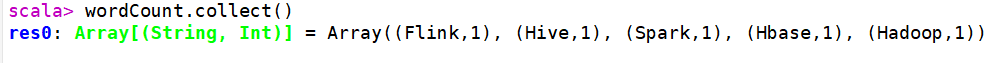
采用的是不需要hadoop版本的spark进行操作
编写应用程序执行词频统计:
下面我们编写一个Scala应用程序来实现词频统计。
请登录Linux系统(本教程统一采用用户名hadoop进行登录),进入Shell命令提示符状态,然后,执行下面命令:
cd /usr/local/spark/mycode/wordcount/ mkdir -p src/main/scala //这里加入-p选项,可以一起创建src目录及其子目录
Shell 命令
请在“/usr/local/spark/mycode/wordcount/src/main/scala”目录下新建一个test.scala文件,里面包含如下代码:
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object WordCount { def main(args: Array[String]) { val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt" val conf = new SparkConf().setAppName("WordCount") val sc = new SparkContext(conf) val textFile = sc.textFile(inputFile) val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) wordCount.foreach(println) } }
如果test.scala没有调用SparkAPI,那么,只要使用scalac命令编译后执行即可。但是,这个test.scala程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包
执行如下命令:
cd /usr/local/spark/mycode/wordcount/
vim simple.sbt
Shell 命令
通过上面代码,新建一个simple.sbt文件,请在该文件中输入下面代码:
name := "WordCount Project" version := "1.0" scalaVersion := "2.12.15" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.0"
注意, "org.apache.spark"后面是两个百分号,千万不要少些一个百分号%,如果少了,编译时候会报错。
下面我们使用 sbt 打包 Scala 程序。为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构:
cd /usr/local/spark/mycode/wordcount/
find .
Shell 命令
应该是类似下面的文件结构:
. ./src ./src/main ./src/main/scala ./src/main/scala/test.scala ./simple.sbt ./word.txt
接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包 ):
cd /usr/local/spark/mycode/wordcount/ //请一定把这目录设置为当前目录 /usr/local/sbt/sbt package
Shell 命令
上面执行过程需要消耗几分钟时间:
生成的 jar 包的位置为
/usr/local/spark/mycode/wordcount/target/scala-2.12/wordcount-project_2.12-1.0.jar
最后,通过 spark-submit 运行程序。我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下:
/usr/local/spark/bin/spark-submit --class "WordCount" /usr/local/spark/mycode/wordcount/target/scala-2.12/wordcount-project_2.12-1.0.jar
结果:

IDEA编写Spark应用程序
。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号