spark05
spark05
|
def main(args: Array[String]): Unit = { |
作业题
|
object MoviesTest { |
wordcount中得rdd数量
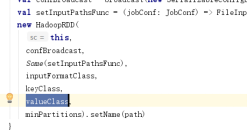

textFile算子中产生了两个rdd,第一个是hadoopRDD用于读取hdfs中得文件,这个读取使用得是hadoop得原生api,key longWritable value text

通过map方法将读取后得文件取value值,不取key

mapPartitionsRDD在flatMap算子中产生

在map算子中产生得mapPartitionsRdd

在reduceByKey这个算子中产生了shuffledRDD

saveAsTextFile存储数据产生得MapPartitionsRDD
一个wordcount应用程序中产生了6rdd
hadoopRDD mapPartitionsRDD mapPartitionsRDD mapPartitionsRDD shuffledRDD mapPartitionsRDD
wordcount中得数据流向图
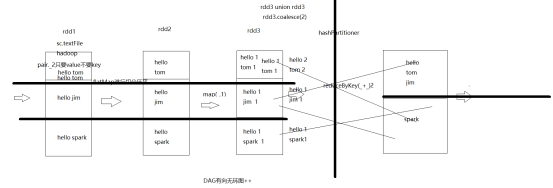
spark任务得调用流程
任务得层次
application job stage task任务数量
spark任务得物理执行流程
spark任务在执行main方法得时候,并没有真正得执行

spark中的原理
RDD之间的依赖关系,父子关系,RDD之间存在血统血缘关系lineage
算子就是两个rdd之间的关系,这个关系又称之为依赖
dependency : shuffleDependency narrowDependency:OneToOne RangeDependency
宽窄依赖
依赖的划分
父rdd和子rdd之间存在依赖关系,宽依赖和窄依赖
- 从计算过程中:窄依赖是管道形式运算的,上一个rdd和下一个rdd之间的数据不会产生变化,数据在一个节点上不会流动,如果产生了节点之间的数据转移,宽依赖(shuffle)
- 从失败恢复的角度:窄依赖的失败恢复比较快,rdd对应分区中的数据丢失就去上一个rdd上面的对应分区中寻找,如果是宽依赖,去上一个rdd上面的所有分区中去寻找
- 综上所述引入一个新的概念,stage,宽依赖会切分stage,窄依赖不会切分stage
管道形式的任务都属于一个stage中
宽依赖和窄依赖的理解
上一个rdd的数据到下一个rdd中的时候对应分区中的数据不会发生改变,窄依赖
上一个rdd上面的数据不同分区中的数据到下一个rdd的分区中 宽依赖
窄依赖是一对一的 map flatMap union filter coalesce
以上的算子都是窄依赖,在窄依赖中算子产生的DAG图是一条线
窄依赖的算子都是pipeline形式的任务

宽依赖
reduceByKey groupBykey distinct groupBy repartition
以上都是宽依赖,他们的分区器都是hashPartitioner
shuffleDependency宽依赖
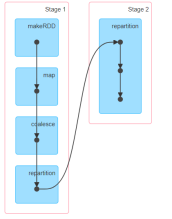
repartition是宽依赖,但是可以变为窄依赖repartition == coalesce(false)
join算子是一个特殊的算子(重点)
join算子是宽依赖还窄依赖????

join算子的底层使用的就是cogroup算子

根据源码得出两个rdd的分区其是一样的那么就是窄依赖,如果是不一样的就是宽依赖
怎么判断分区器是不是一样的?

分区器中含有一个equals方法,这个方法中判定逻辑,如果两个分区器都是hash分区器,并且分区数量一致,那么两个分区器就一样,那么就是窄依赖,不然就是宽依赖
|
scala> var arr = Array(("zhangsan",200),("lisi",700),("xiaohong",20000)) arr: Array[(String, Int)] = Array((zhangsan,200), (lisi,700), (xiaohong,20000))
scala> var arr1 = Array(("zhangsan",20),("lisi",30),("xiaohong",1)) arr1: Array[(String, Int)] = Array((zhangsan,20), (lisi,30), (xiaohong,1))
scala> sc.makeRDD(arr,3) res7: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[8] at makeRDD at <console>:27
scala> sc.makeRDD(arr1,3) res8: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[9] at makeRDD at <console>:27
scala> res7 join res8 res9: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[12] at join at <console>:33
scala> res9.collect res10: Array[(String, (Int, Int))] = Array((zhangsan,(200,20)), (xiaohong,(20000,1)), (lisi,(700,30))) |
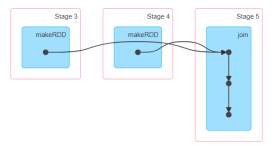
分区器都没有,分区数量一致就是宽依赖
|
scala> res7.reduceByKey(_+_) res11: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[13] at reduceByKey at <console>:29
scala> res8.reduceByKey(_+_) res12: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[14] at reduceByKey at <console>:29
scala>
scala> res11 join res12 res13: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[17] at join at <console>:37
scala> res13.collect res14: Array[(String, (Int, Int))] = Array((zhangsan,(200,20)), (xiaohong,(20000,1)), (lisi,(700,30)))
|
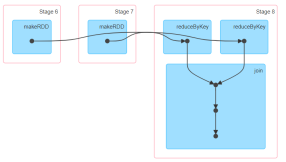
算子是不是宽依赖,看这个算子的上一个rdd和下一个rdd是不是在一个stage中存在
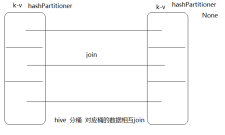
join之后的rdd分区数量
- 如果两个rdd都是普通的rdd
|
scala> sc.makeRDD(arr,3) res15: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[18] at makeRDD at <console>:27
scala> sc.makeRDD(arr1,4) res16: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[19] at makeRDD at <console>:27
scala> res15 join res16 res17: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[22] at join at <console>:33
scala> res17.partitions.size res18: Int = 4 |
如果两个rdd都是普通的rdd,而且分区数量不一样,那么以数量多的rdd为主
如果一个含有分区器的,一个是普通的rdd,以含有分区器的为主
|
scala> res15.reduceByKey(_+_) res19: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:29
scala> res19 join res16 res20: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[26] at join at <console>:35
scala> res20.partitions.size res21: Int = 3 |
两个都是含有分区器的,以多的为主
|
scala> res16.reduceByKey(_+_) res23: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[27] at reduceByKey at <console>:29
scala> res23 join res19 res24: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[30] at join at <console>:37
scala> res24.partitions.size res25: Int = 4 |
依赖和stage
依赖会进行切分stage,宽依赖会切分stage,一旦产生了shuffle流程那么就会切分stage
一个job中存在多少个stage看shuffle算子的个数,shuffle算子的个数+1就是stage的个数
什么是stage呢?


shuffleMapStage是处理阶段,一个任务中存在多个shuffleMapStage,存在一个resultStage
一个任务中肯定存在一个resultStage,存在多个shuffleMapStage
依赖和容错
rdd的数据丢失后会从上一个rdd中进行数据的恢复
窄依赖会从上一个rdd对应的分区中找到相应的数据
宽依赖会从上一个rdd的所有分区中找到对应的数据,这些数据多个分区中的数据
rdd数据丢失以后会从哪个RDD找到?
Driver是任务运行的老大,这个driver相当于mr中的appMaster,属于整个任务的管理,driver端在任务提交以后会对任务进行解析,在解析的过程中会将任务的处理过程进行记录,失败的恢复的时候会在driver端找寻相应的业务逻辑。driver端是一次性的针对于每个应用都会产生一个新的driver,那么executors和driver也是一套,所以executor也是一次性的。
driver还会进行故障重试,如果任务在executor中运行失败,那么会重启3次,会将失败的任务转移到另外的executor中
DAG有向无环图
对于整个任务运行执行过程的一个优化
DAG有向无环图的开头 第一个rdd
DAG的终点:action
点(rdd) + 线(算子) 组成一个DAG图,切分阶段 按照shuffle流程切分阶段
可以清晰的体现出来缓存的概念
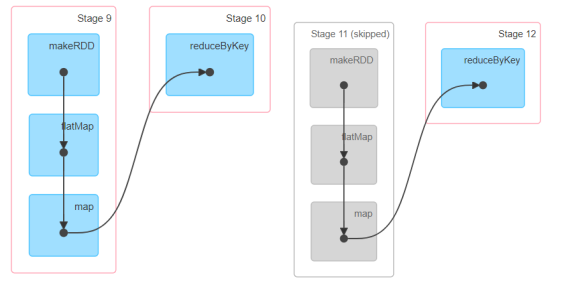
在一个任务中,如果运行两次一样的业务逻辑,数据会存在缓存,前面的部分业务逻辑会跳过,但是业务逻辑会执行两次。依赖关系和业务逻辑没有发生任何改变
spark任务的运行机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号