
YOLO-World 论文核心内容阅读与注解
摘要
YOLO(You Only Look Once)系列检测器已成为高效实用的工具,但其依赖预定义训练类别的特性限制了在开放场景中的应用。为突破这一局限,我们提出了 YOLO-World ——通过视觉-语言建模和大规模数据集预训练赋予 YOLO 开放词汇检测能力的创新方案。具体而言,我们提出了一种新的可重参数化的视觉语言路径聚合网络(RepVL-PAN)和区域文本对比损失函数,以强化视觉与语言信息之间的交互。我们的方法能以零样本方式高效检测各类物体。在具有挑战性的 LVIS 数据集上,YOLO-World 在 V100 显卡上以 52.0 FPS 实现 35.4 AP 的精度,在准确率与速度上均超越现有先进方法。经微调后,YOLO-World在目标检测、开放词汇实例分割等下游任务中均展现出卓越性能。
1. 介绍
目标检测作为计算机视觉领域长期存在的基础性挑战,在图像理解、机器人技术和自动驾驶等众多应用中具有重要价值。随着深度神经网络的发展,大量研究 [Mask R-CNN,FPN,YOLOv1,Faster R-CNN] 在目标检测领域取得了重大突破。尽管这些方法取得了成功,但仍然存在固有局限,因为它们仅能处理固定词汇(如COCO数据集的 80 个类别)的目标检测任务。当物体类别被预先定义并标注后,训练完成的检测器只能识别这些特定类别,这种特性限制了检测模型在开放场景中的适应能力与应用范围。
近期的研究工作尝试利用主流视觉-语言模型,通过从语言编码器(如 BERT)中蒸馏词汇知识来实现开放词汇检测。但这类基于蒸馏的方法受限于训练数据稀缺和词汇多样性不足(如 OV-COCO 仅含 48 个基础类别),存在明显局限性。一些研究将目标检测训练重构为区域级视觉-语言预训练,实现了大规模开放词汇目标检测器的训练。然而这些方法在实际场景应用中仍面临双重挑战:(1) 沉重的计算负担;(2) 边缘设备部署复杂度高。先前的工作已证明预训练大型检测器的优势性能,但对小型检测器进行预训练以赋予其开放识别能力的研究仍属空白。
本文提出 YOLO-World 模型,致力于实现高效的开放词汇目标检测,并探索通过大规模预训练方案将传统 YOLO 检测器性能提升至开放词汇的新境界。相较于现有方法,YOLO-World 非常高效,其具有很高的推理速度,且下游任务部署便捷。具体来说,YOLO-World 采用标准 YOLO 架构作为基础框架,并引入预训练 CLIP 文本编码器处理输入文本。我们进一步提出了可重参数化的视觉-语言路径聚合网络(RepVL-PAN)联接文本与图像特征,实现了视觉-语义表征的优化升级。在实际部署时,该设计允许移除文本编码器,并将文本向量重参数化为 RepVL-PAN 的网络权重,以提升运行效率。我们通过在大规模数据集上进行区域-文本对比学习,进一步研究了 YOLO 检测器的开发词汇预训练方案,过程中我们将检测数据、Grounding 数据和图像-文本数据统一转化为区域-文本对进行训练。实验表明:基于海量区域-文本对预训练的 YOLO-World 展现出强大的开放词汇检测能力,且模型性能随训练数据规模扩大持续提升。
此外,我们探索了一种“先提示后检测”(prompt-then-detect)的范式,以进一步提升现实场景中开放词汇目标检测的效率。如图 2 所示,传统目标检测器专注于使用预定义和训练好的类别进行固定词汇(闭集)检测。而先前的开放词汇检测器(GLIP、Grounding DINO、DetCLIP、GLIPv2)通过文本编码器对用户的提示进行编码以构建在线词汇表并检测物体。值得注意的是,这些方法倾向于采用具有重型主干网络的大型检测器(如Swin-L[32])来提高开放词汇能力。相比之下,“先提示后检测”范式(图 2 (c))首先对用户提示进行编码以构建离线词汇表,该词汇表会根据不同需求而变化。随后,高效的检测器可以即时推断离线词汇表而无需重新编码提示。在实际应用中,一旦我们训练好检测器(即YOLO-World),就可以预先编码提示或类别以构建离线词汇表,然后将其无缝集成到检测器中。
我们的主要贡献可归纳为以下三个方面:
-
我们提出了 YOLO-World,这是一种面向实际应用的高效开放词汇目标检测前沿方法;
-
我们设计了一种可重参数化的视觉语言路径聚合网络(Re-parameterizable Vision-Language PAN)来实现视觉与语言特征的融合,并为 YOLO-World 开发了开放词汇区域文本对比预训练方案;
-
在大规模数据集上预训练的 YOLO-World 展现出强大的零样本性能,在 LVIS 数据集上以 52.0 FPS 的速度达到 35.4 AP。预训练的 YOLO-World 可轻松适配下游任务,如开放词汇实例分割和指代目标检测。此外,我们将开源 YOLO-World 的预训练权重和代码,以促进更多实际应用。
2. 相关工作
3. 方法
3.1. 预训练规划:区域-文本对(Region-Text Pairs)
传统的目标检测方法,包括YOLO系列,都使用实例注释 \(\Omega=\{B_i,c_i\}^N_{i=1}\) 进行训练,其由边界框 \({B_i}\) 和类别标签 \({c_i}\) 组成。在本文中,我们将实例注释重新表述为区域-文本对 \(\Omega={B_i,t_i}^N_{i=1}\),其中 \(t_i\) 是区域 \(B_i\) 对应的文本。具体来说,文本 \(t_i\) 可以是类别名称、名词短语或对象描述。此外,YOLO-World同时采用图像 \(I\) 和文本 \(T\)(一组名词)作为输入,并输出预测框 \(\{\hat{B}_k\}\) 及相应的对象向量 \(\{e_k\}\;(e \in \mathbb{R}^D)\)。
“区域-文本对”是为了便于描述通过伪标记生成的区域-文本对提出的,下文提到通过伪标记方法从图像-文本数据中,分别提取名词短语并生成伪框,来构造训练数据。相比如 Obj365 这样的Detection数据集,伪标记的数据相对粗糙,对于 Obj365,“区域-文本对”即实例注释
3.2. 模型架构
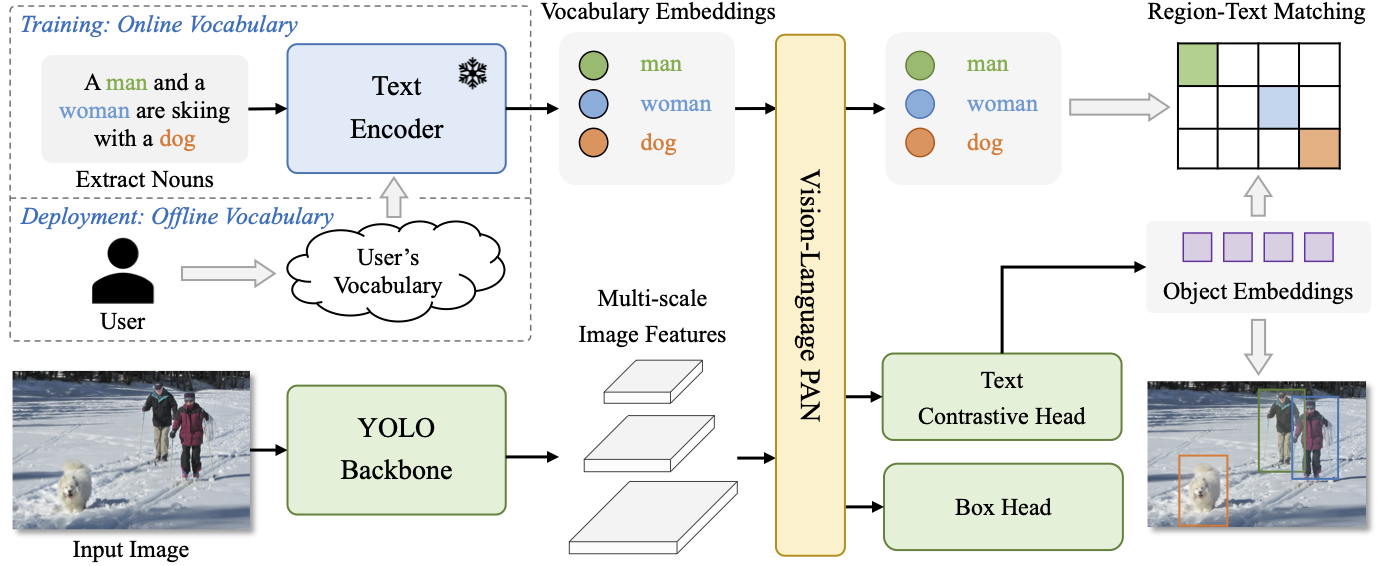
Figure 3. YOLO-World的整体架构。与传统的YOLO检测器相比,YOLO-World作为一个开放词汇检测器,额外采用了文本作为输入。文本编码器首先将输入的文本编码为文本向量。然后,图像编码器将输入的图像编码为多尺度图像特征。所提出的RepVL-PAN再对图像和文本特征进行多层次交叉模态融合。最后,YOLO-World预测回归的边界框和对象向量,来匹配出现在输入文本中的类别或名词。
所提出的YOLO-World的整体架构如 Fig.3 所示,它由一个 YOLO 检测器、一个文本编码器和一个可重新参数化的视觉-语言路径聚合网络(RepVL-PAN)组成。给定输入文本,YOLO-World 中的文本编码器将文本编码为文本向量。YOLO 检测器中的图像编码器则从输入的图像中提取多尺度特征。然后,我们利用 RepVL-PAN,通过图像特征和文本向量之间的交叉模态融合,来增强文本和图像表示。
YOLOW架构按“Backbone-Neck-Head”模式进行组织,Backbone部分含YOLOv8图像编码器+CLIP文本编码器,Neck部分为本文提出的RepVL-PAN,Head部分基于YOLOv8并引入了文本对比头
YOLO 检测器:YOLO-World 主要是基于 YOLOv8 开发的,包含一个 Darknet backbone 作为图像编码器,一个用于多尺度特征金字塔的路径聚合网络(PAN),以及一个用于边界框回归和Object Embeddings 的 Head。
Object Embeddings 是指将特征映射到与文本对齐的语义空间,思想上和CLIP的图像编码器类似,目的是为了后续进一步进行对比学习,即计算区域-文本相似度。具体的,YOLOv8s 的分类检测头 “cls_pred” 输出的是特征图各空间位置属于不同类别的概率,而YOLOW的分类检测头输出的是和文本向量对齐的特征向量表示,用于与文本向量进行相似度计算
文本编码器:对于给定的文本 \(T\),我们采用预训练的 CLIP Transformer 文本编码器来提取相应的文本向量 \(W=\text{TextEncoder}(T)\in\mathbb{R}^{C\times D}\),其中 \(C\) 是名词的数量, \(D\) 是向量的维度。与纯文本的语言编码器相比,CLIP 文本编码器提供了更好的视觉-语义功能,来连接视觉对象和文本。当输入文本为标题或指称表达时,我们采用简单的 n-gram 算法提取名词短语,然后将其输入文本编码器。
“n-gram 算法提取名词短语”的步骤主要体现在下文的使用伪标记生成数据的过程中,模型网络传播过程没有体现
文本对比头:根据之前的工作(YOLOv8),我们采用具有两个 \(3\times 3\) 卷积的解耦合头来回归边界框 \(\{b_k\}^K_{k=1}\) 和 Object Embeddings \(\{e_k\}^K_{k=1}\),其中 \(K\) 表示对象的数量。我们提出了一个文本对比头,以获取对象-文本相似度 \(s_{k,j}\):
其中 \(\text{L2Norm()}\) 为 L2 归一化,\(w_j\in W\) 为第 \(j\) 个文本向量。此外,我们还添加了具有可学习缩放因子 \(\alpha\) 和移位因子 \(\beta\) 的仿射变换。L2 规范和仿射变换对于稳定区域-文本训练十分重要。
在新的 YOLOW v2 版本中,\(e_k\) 改用 BatchNorm 进行归一化,以实现更高效的部署,和提高模型零样本性能
使用Online Vocabulary训练:在训练过程中,我们为每个包含 4 张图像的 Mosaic 样本构建一个在线词汇表 \(T\)。具体来说,我们取 Mosaic 图像中涉及的所有正名词作为样本,并从相应的数据集中随机抽取一些负名词。每个 Mosaic 样本的词汇表最多包含 \(M\) 个名词,并且 \(M\) 被默认设置为 80。
Mosaic 样本由 4 个图像组成,假设 4 个图像包含的类别(正名词)有 50 个,那么再从同数据集总类别中随机另取30个类别作为负名词,用这 80(M)个类别为当前 Mosaic 样本生成类别向量表(Online Vocabulary)进行目标检测训练。
对于非 Detection 类的数据集,没有直接提供总的类别信息,每个Mosaic样本的所含类别即为该样本的总类别。
每个 Mosaic 样本的词汇数不足 M 时,使用 ' ' 填充;超过 M 时,则随机采样至 M。
使用Offline Vocabulary推理:在推理阶段,我们提出了一个使用离线词汇表的 prompt-then-detect 策略,以进一步提高效率。如 Fig.3 所示,用户可以定义一系列自定义提示,其中可能包括标题或类别。然后,我们利用文本编码器对这些提示进行编码,并获得离线词汇向量。使用离线词汇表可以避免对每个输入进行计算,并为根据需求调整词汇表的提供了灵活性。
Online Vocabulary 是指模型根据用户实际提供的文本,使用文本编码器编码获取类别向量,意味着用户可以随时更改或定义文本;Offline Vocabulary 则是指用户可以定义一个词汇表,该词汇表将被预先编码为向量并嵌入为模型的参数,使模型不再依赖文本编码器,实现高效的部署。
3.3. Re-parameterizable Vision-Language PAN
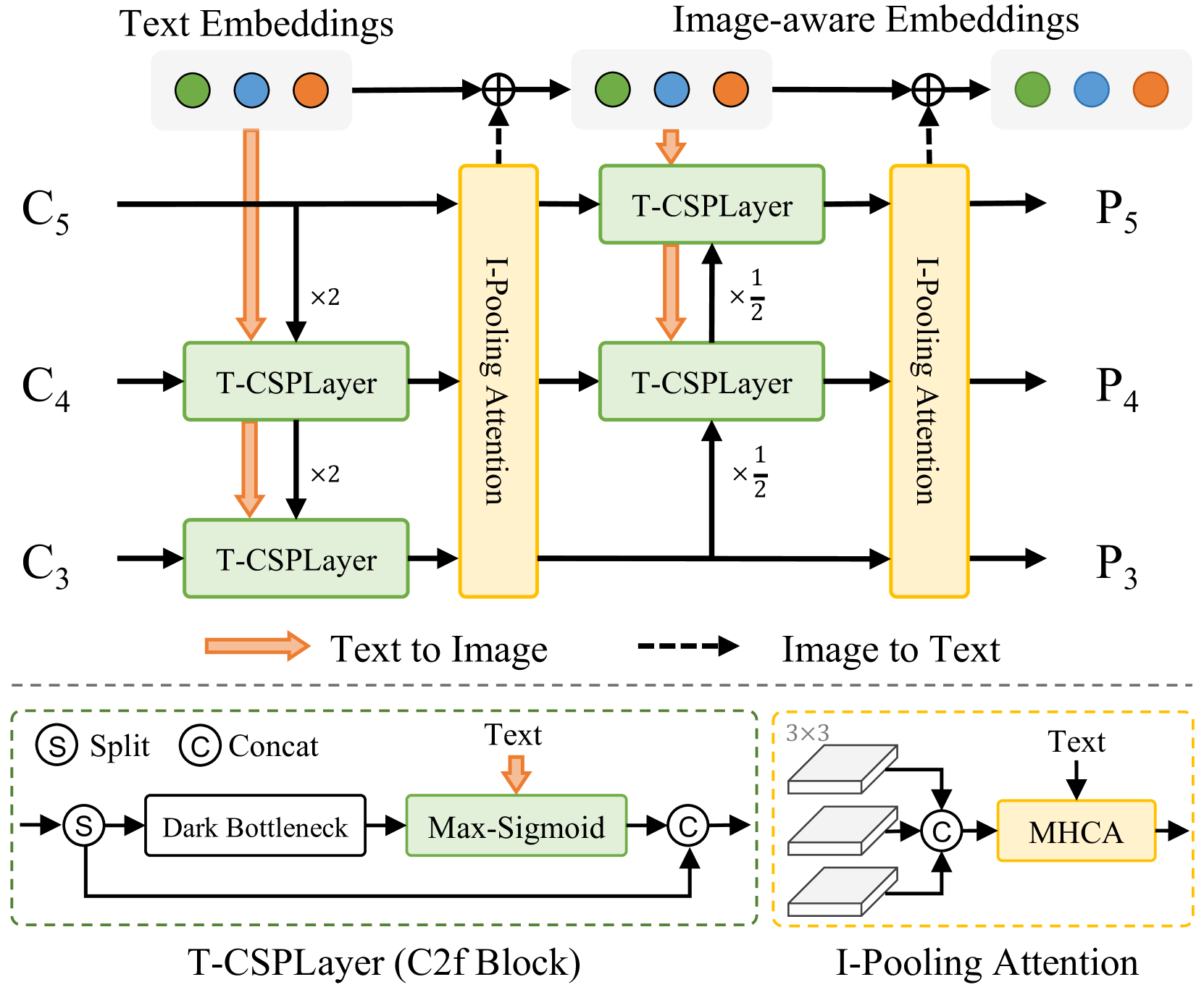
[^Figure 4. RepVL-PAN示意图]: 提出的RepVL-PAN采用 Text-guided CSPLayer(T-CSPLayer)为图像特征添加语义信息,采用 Image Pooling Attention(I-Pooling Attention)增强图像感知的文本向量。
Fig.4 展示了提出的 RepVL-PAN 的结构,它遵循 YOLOv8 和 PAN 中 top-down 和 bottom-up 的路径,建立了具有多尺度图像特征 \(\{C3,C4,C5\}\) 的特征金字塔 \(\{P3,P4,P5\}\)。此外,我们提出了 Text-guided CSPLayer(T-CSPLayer)和 Image-Pooling Attention(I-Pooling Attention)来进一步增强图像特征与文本特征之间的交互,从而为开放词汇能力增强视觉-语义表示。在推理过程中,可以将离线词汇表向量重新参数化为卷积层或线性层的权重,以进行部署。
RepVL-PAN 可拆解为三大要素: PAN + Visual-Language + Rep
PAN 即遵循的 YOLOv8 的路径聚合网络结构,通过 top-down 和 bottom-up 实现深层、浅层网络特征的相互融合,提高模型对不同尺度目标的检测能力
在 PAN 中引入 Visual-Language 信息的交叉融合,便是 VL-PAN。YOLOW中通过 T-CSPLayer 将文本信息融入图像信息,I-Pooling Attention 将图像信息融入文本信息
RepVL-PAN 是在将文本信息参数化为卷积层(或线性层),通过卷积代替图像特征和文本特征的矩阵乘法计算,提高推理速度
Text-guided CSPLayer:如 Fig.4 所示,在自上而下或自下而上的融合后,使用了 CSPLayer。我们通过将文本引导纳入多尺度图像特征并组成 Text-guided CSPLayer,实现对 YOLOv8 中 CSPLayer(也称为C2f)的扩展。具体来说,对于给定的文本向量 \(W\) 和图像特征 \(X_l\in\mathbb{R}^{H\times W \times D}\;(l\in\{3,4,5\})\),我们在最后一个 dark bottleneck block 之后采用了 max-sigmoid attention,将文本特征聚合到图像特征中:
其中更新的 \(X'_l\) 与跨阶段特征进行 Concat 连接后得到输出,\(\delta\) 则表示 sigmoid 函数。
Image-Pooling Attention:为了增强具有图像感知信息的文本向量,我们提出通过 Image-Pooling Attention 聚合图像特征来更新文本向量。我们没有直接在图像特征上使用 cross-attention,而是在多尺度特征上的利用最大池化获取 \(3\times 3\) 的区域,总共得到 27 个patch tokens \(\hat{X}\in\mathbb{R}^{27\times D}\)。然后再对文本向量进行更新:
在新的 YOLOW v2 版本中,为了提高模型导出为ONNX等格式后的推理速度,移除了Image-Pooling Attention操作。此外,在原来的模型结构下,只在 top-down 特征融合后使用Image-Pooling Attention,而非图示的两次 Image-Pooling Attention

 浙公网安备 33010602011771号
浙公网安备 33010602011771号