大数据分析与可视化 之 实验01 Python爬虫
实验01 Python爬虫
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 理解爬虫技术
- 掌握正则表达式、网络编程
- 掌握re、socket、urllib、requests、lxml模块及其函数的使用
二、实验要求
分析所需爬取信息网页的源代码,使用re、socket、urllib、requests、lxml模块及其函数爬取网页内容,并分析网页内容、提取所需要的数据 。
三、实验内容
任务1. 使用urllib抓取网页数据:
(1)确定网址字符串,如:‘http://www.baidu.com’
(2)向网站发出请求,把字符串传入request对象
(3)把请求返回的信息赋值到response对象
(4)写入txt文件
用Python编写程序实现。
参考代码如下:
#coding:utf-8
import urllib.request
def main():
#请求的头部,User-Agent为浏览器的类型
header={'User-Agent':'Mozilla/5.0(Windows NT 6.1;WOW64) AppleWebKit/537.36(KHTML,like Gecko)Chrome/58.0.3029.96 Safari/537.36'}
#request请求对象,请求某一网站的内容
request=urllib.request.Request('http://www.xmut.edu.cn',headers=header)
#网站的响应
response1=urllib.request.urlopen('http://www.xmut.edu.cn')
response2=urllib.request.urlopen(request)
#读取响应信息的字节流
html=response1.read()
#信息写入文件
f=open('./AL9-7.txt','wb')
f.write(html)
f.close()
if __name__=="__main__":
main()
任务2. 使用requests模块爬取百度首页文件的内容,输出响应对象的类型、状态码和头信息。用Python编写程序实现。
参考代码如下:
#coding:utf-8
import requests
def main():
url='http://www.baidu.com'
response=requests.get(url)
print(type(response))#输出响应对象的内容
print(response.status_code)#输出响应状态码
print(response.headers)#输出响应的头信息
print(response.text)#输出响应的内容
if __name__=="__main__":
main()
任务3. 使用requests和lxml模块爬取某网站的内容,转换成html对象,解析html结点内容,存入数据文件中。
参考代码如下:


课外练习:(特别强调:爬取的数据只能作为学习练习用,用完删除,不能作其他用途,否则涉及侵权违法行为,责任自负,与学校老师无关!)
任务4. 爬取百度贴吧的数据,用Python编写程序实现。
任务5. 爬取豆瓣电影网站的数据,用Python编写程序实现。
任务6. 用Python爬取网络相片。
http://c.biancheng.net/python_spider/crawl-photo.html
test1.py
# coding:utf-8
import urllib.request
import UA
import requests, time, csv
from lxml import etree
from chapter01 import baiDuTieBaHTML
import BaiduTieba
def test1():
# 请求的头部,User-Agent为浏览器的类型
header = {
'User-Agent': UA.get_ua()}
# request请求对象,请求某一网站的内容
request = urllib.request.Request('http://www.baidu.com', headers=header)
# 网站的响应
response1 = urllib.request.urlopen('http://www.baidu.com')
response2 = urllib.request.urlopen(request)
# 读取响应信息的字节流
html = response1.read()
# 信息写入文件
f = open('data/AL9-7.txt', 'wb')
f.write(html)
f.close()
def test2():
url = 'http://www.baidu.com'
response = requests.get(url)
print(type(response)) # 输出响应对象的内容
print(response.status_code) # 输出响应状态码
print(response.headers) # 输出响应的头信息
print(response.text) # 输出响应的内容
# 获取每一页的url
def Get_url(url):
all_url = []
for i in range(1, 10):
all_url.append(url + 'pg' + str(i) + '/')
return all_url
def Get_house_url(all_url, headers):
num = 0
for i in all_url:
r = requests.get(i, headers=headers)
html = etree.HTML(r.text)
url_ls = html.xpath("//ul[@class='listContent']/li/a/@href")
Analysis_html(url_ls, headers)
time.sleep(4)
print("第%s页爬完了" % i)
num += 1
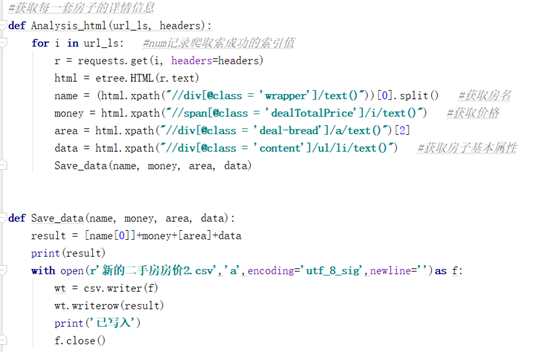
def Analysis_html(url_ls, headers):
for i in url_ls:
r = requests.get(i, headers=headers)
html = etree.HTML(r.text)
name = (html.xpath("//div[@class = 'wrapper']/text()"))[0].split()
money = html.xpath("//span[@class='dealTotalPrice']/i/text()")
area = html.xpath("//div[@class='deal-bread']/a/text()")[2]
data = html.xpath("//div[@class='content']/ul/li/text()")
Save_data(name, money, area, data)
def Save_data(name, money, area, data):
result = [name[0]] + money + [area] + data
print(result)
with open(r'data/新的二手房价2.csv', 'a', encoding='utf-8-sig', newline='')as f:
wt = csv.writer(f)
wt.writerow(result)
print('已写入')
f.close()
def test3():
url = 'https://xm.lianjia.com/chengjiao/'
headers = {
"Upgrade-Insecure-Requests": "1",
"User-Agent": UA.get_ua(),
"Cookie": '添加个人cookie'
}
all_url = Get_url(url)
with open(r"data/新的二手房价2.csv", 'a', encoding='utf_8_sig', newline='')as f:
table_label = ["小区名", "价格/万", "地区", "房屋户型", "所在楼层", "建筑面积", "户型结构", "套内面积", "建筑类型", "房屋朝向", "建成年代", "装修情况",
"建筑结构", "供暖方式", "梯户比例", "产权年限", "配备电梯", "链家编号", "交易权属", "挂牌时间", "房屋用途", "房屋年限", "房权所属"]
wt = csv.writer(f)
wt.writerow(table_label)
Get_house_url(all_url, headers)
# 百度贴吧
def test4():
start = time.time()
spider = BaiduTieba.TiebaSpider()
spider.run() # 调用入口函数
end = time.time()
# 查看程序执行时间
print('执行时间:%.2f' % (end - start)) # 爬虫执行时间
if __name__ == "__main__":
test1()
test2()
test3()
test4()
BaiduTieba.py
import csv
from urllib import request, parse
import time
import random
from lxml import etree
import requests
# 定义一个爬虫类
class TiebaSpider(object):
# 初始化url属性
def __init__(self):
self.url = 'http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self, url):
response = requests.get(url=url, headers={'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/95.0.4638.69 Safari/537.36"})
html = response.content.decode('utf-8').replace("<!--", "").replace("-->", "")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self, html):
eroot = etree.HTML(html)
# 提取行数据
li_list = eroot.xpath('//*[@id="thread_list"]/li/div/div[2]/div[1]/div[1]/a')
data = []
for li in li_list:
item = {}
item["title"] = li.xpath('./text()')[0]
item["link"] = 'https://tieba.baidu.com' + li.xpath('./@href')[0]
data.append(item)
return data
def save_csv(self, data, filename):
with open(filename, 'a', newline='', encoding='utf_8_sig') as csv_file:
# 指定CSV文件的列名
fieldnames = ['title', 'link']
# 创建CSV写入器
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# 写入列名
writer.writeheader()
# 写入数据
for row in data:
writer.writerow(row)
print(f'Data has been written to {filename}')
# 4.入口函数
def run(self):
# 构建文件名,精确到小时和分钟
name = input('输入贴吧名:')
begin = int(input('输入起始页:'))
stop = int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin, stop + 1):
pn = (page - 1) * 50
params = {
'kw': name,
'pn': str(pn)
}
# 拼接URL地址
params = parse.urlencode(params)
url = self.url.format(params)
# 发请求
html = self.get_html(url)
items = self.parse_html(html)
# self.save_items(items, filename)
filename = './data/{}-{}页.csv'.format(name, page)
self.save_csv(items, filename)
# 提示
print('第%d页抓取成功' % page)
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1, 2))
# 以脚本的形式启动爬虫
if __name__ == '__main__':
start = time.time()
spider = TiebaSpider() # 实例化一个对象spider
spider.run() # 调用入口函数
end = time.time()
# 查看程序执行时间
print('执行时间:%.2f' % (end - start)) # 爬虫执行时间
个人作业心得,请勿用于商业用途。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号