从小白到小黑 python学习之旅 日常总结 12(文件处理2)
文件处理2
控制文件操作的模式 补充:x模式
x模式 :只写模式【不可读;不存在则创建,存在则报错】 #了解
#当 文件(D:\cool\user)时 with open(r'D:\cool\user',mode='xt',encoding='utf-8') as f: pass #报错
# 当 文件(D:\cool\user1)不存在时 with open(r'D:\cool\user1',mode='xt',encoding='utf-8') as f: f.read() #读 # 报错
#当 文件(D:\cool\user2) 不存在时 with open(r'D:\cool\user2', mode='x', encoding='utf-8') as f: f.write('哈哈哈\n')
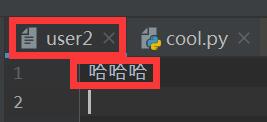
控制文件读写内容的模式
t(默认):文本模式
1、读写都是以字符串(unicode)为单位
2、只能针对文本文件
3、必须指定字符编码,即必须指定encoding参数
b:binary模式(二进制模式)
1、读写都是以bytes(二进制)为单位
2、可以针对所有文件
3、一定不能指定字符编码,即一定不能指定encoding参数
重点
1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便
2、针对非文本文件(如图片、视频、音频等)只能使用b模式
b模式
b模式取文本要指定编码不然就是 二进制
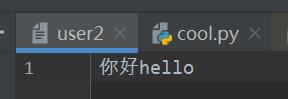
with open(r'D:\cool\user2',mode='rb') as f: res=f.read() # utf-8的二进制 print(res,type(res)) #b'\xe5\x93\x88\xe5\x93\x88\xe5\x93\x88\r\n' <class 'bytes'> print(res.decode('utf-8')) #指定编码 utf-8 #哈哈哈
b模式存 文字、字符 也要指定编码 不指定直接报错with open(r'D:\cool\user2.txt',mode='wb') as f: f.write('你好hello'.encode('utf-8'))
错误示范 :读图片、视频 等用b模式,t模式只能读文本文件
with open(r'C:\Users\Administrator\Desktop\小白鼠1号.jpg',mode='rt') as f: #C:\Users\Administrator\Desktop\小白鼠1号.jpg(图片) f.read() # 硬盘的二进制读入内存-》t模式会将读入内存的内容进行decode解码操作 #报错
b模式的应用案例
文件拷贝工具
方式一
with open(r'C:\Users\Administrator\Desktop\小白鼠1号.jpg',mode='rb') as f1,\ open(r'C:\Users\Administrator\Desktop\小白鼠2号.jpg',mode='wb') as f2: res=f1.read() # 内存占用过大 f2.write(res)

方式二
with open(r'C:\Users\Administrator\Desktop\小白鼠1号.jpg',mode='rb') as f1,\ open(r'C:\Users\Administrator\Desktop\小白鼠3号.jpg',mode='wb') as f2: for line in f1: #循环取出减小内存压力 f2.write(line)

循环读取文件
# 方式一:自己控制每次读取的数据的数据量 with open(r'C:\Users\Administrator\Desktop\小白鼠1号.jpg',mode='rb') as f: while True: res=f.read(1024) # 1024 if len(res) == 0: break print(len(res))
# 方式二:以行为单位读,当一行内容过长时会导致一次性读入内容的数据量过大 with open(r'C:\Users\Administrator\Desktop\小白鼠1号.jpg',mode='rt',encoding='utf-8') as f: for line in f: print(len(line),line)
以上需再确认
一:读相关操作
1、readline:一次读一行
2、readlines:
强调:
f.read()与f.readlines()都是将内容一次性读入内存,如果内容过大会导致内存溢出,若还想将内容全读入内存,
二:写相关操作
f.writelines():
补充1:如果是纯英文字符,可以直接加前缀b得到bytes类型
补充2:'上'.encode('utf-8') 等同于bytes('上',encoding='utf-8')
3、flush:
4、了解
指针移动的单位都是以bytes/字节为单位
只有一种情况特殊:
t模式下的read(n),n代表的是字符个数
f.seek(n,模式):n指的是移动的字节个数
强调:只有0模式可以在t下使用,1、2必须在b模式下用
f.tell() # 获取文件指针当前位置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号