hadoop跑自带的wordcount程序
首先查看hadoop进程。
jps

说明只有一个进程,hadoop没启动
启动hadoop进程
start-dfs.sh
start-yarn.sh
出现如下进程说明hadoop启动成功

在如下目录创建一个data.txt文件
里面随便输入一些英文字符。就像我刚才输入的一样
进入hadoop目录

.在云端创建一个/data/input的文件夹结构
bin/hdfs dfs -mkdir -p /data/input
把data.txt文件上传到云端,
bin/hdfs dfs -put data.txt /data/input
查看云端的/data/input文件夹下面有哪些文件
bin/hdfs dfs -ls /data/input

这个就是我们上传的data.txt文件
运行share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar这个java程序,调用wordcount方法
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input/data.txt /data/out/data
后面出现这些说明成功
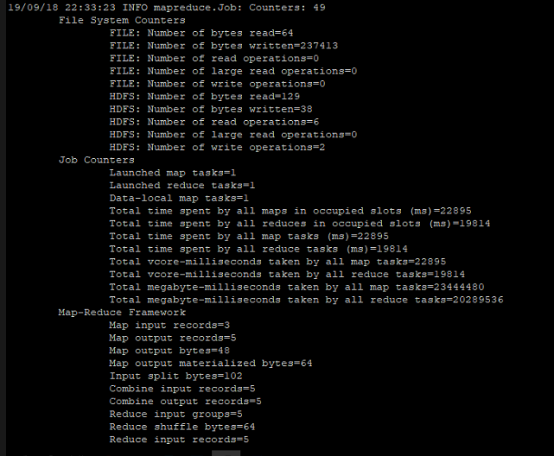
查看结果
bin/hdfs dfs -cat /data/out/data/part-r-00000

成功
解决问题=
态度(珍惜,无我(找不到我),空船)
+归因(并不是所有的问题都需要解决,并不是所有问题都需要现在解决,并不是所有的问题都需要自己解决)
+解决方法
(金字塔原理
(背景,结论,阐述支撑观点,对于观点(背景,结论,观点。。。)二叉树)
+系统循环方法)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号