TensorRT学习日志
定义
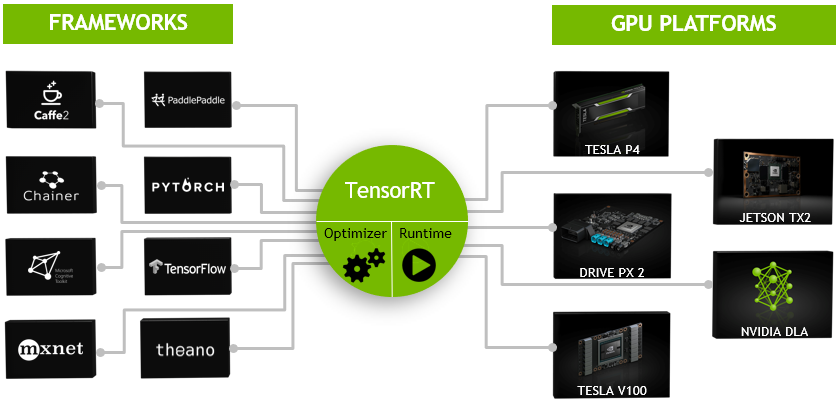
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
- 训练(training) 包含了前向传播和后向传播两个阶段,针对的是训练集。训练时通过误差反向传播来不断修改网络权值(weights)
- 推理(inference) 只包含前向传播一个阶段,针对的是除了训练集之外的新数据。可以是测试集,但不完全是,更多的是整个数据集之外的数据。其实就是针对新数据进行预测,预测时,速度是一个很重要的因素。
优化
- tensorRT中有一个 Plugin 层,这个层提供了 API 可以由用户自己定义tensorRT不支持的层。
- 层间融合或张量融合
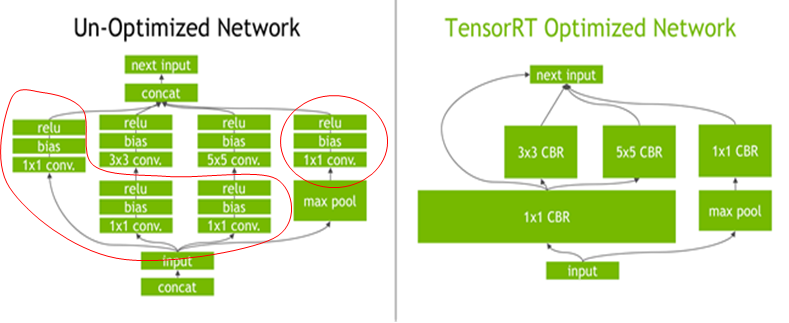
- 降低精度 可以适当降低数据精度,比如FP32降为FP16或INT8的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。int8需要校准Calibration来最小化性能损失
- Kernel Auto-Tuning 显卡转换
- Dynamic Tensor Memory tensor显存指定
- Multi-Stream Execution 底层优化
使用流程
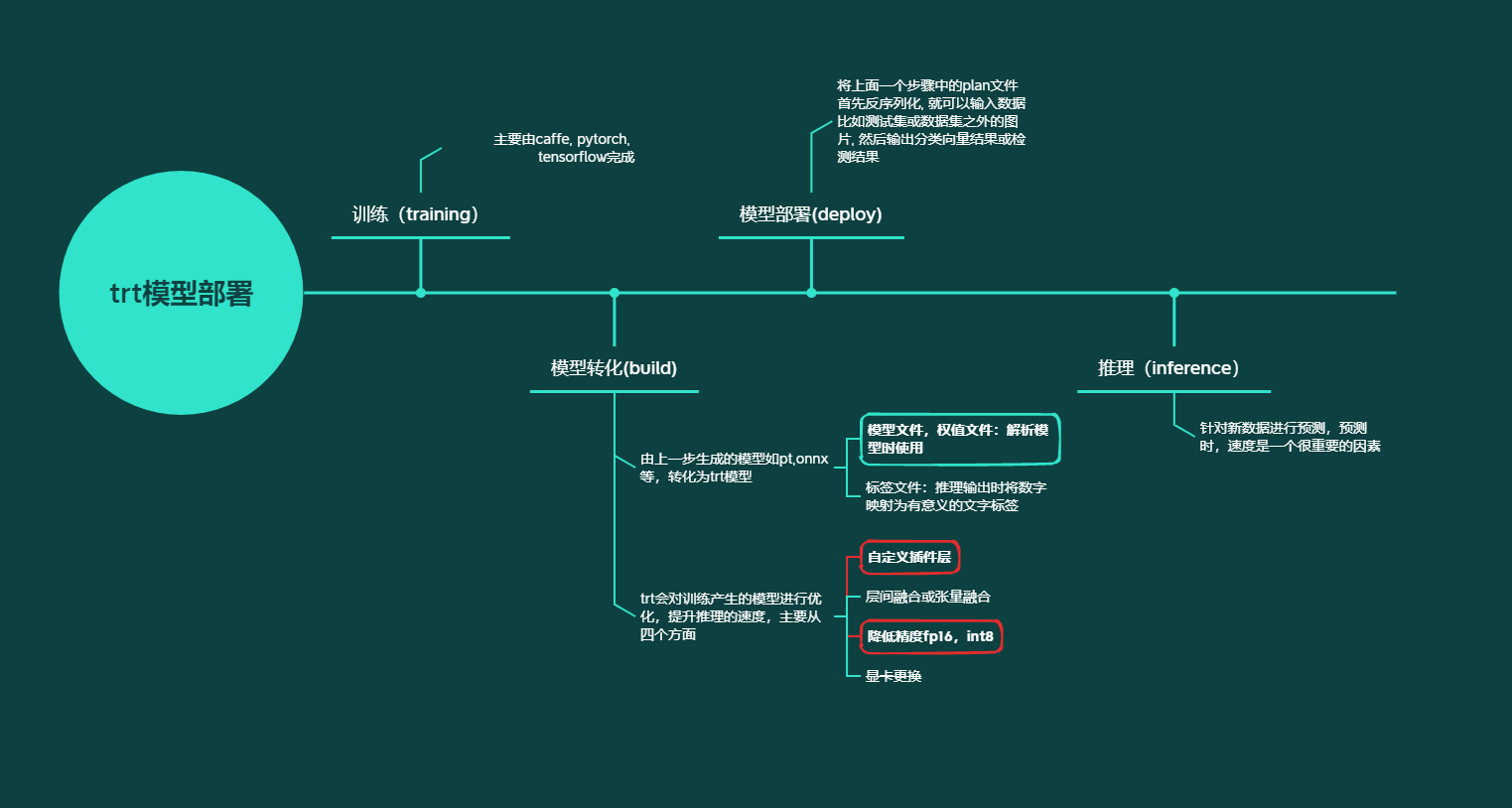
在使用tensorRT的过程中需要提供以下文件(以caffe为例):
- 模型文件
- 权值文件
- 标签文件
前两个是为了解析模型时使用,最后一个是推理输出时将数字映射为有意义的文字标签。
tensorRT的使用包括两个阶段, build and deployment
- build build阶段主要完成模型转换 , 从导入的onnx, matlab, caffe, tensorflow模型转化为TensorRT的trt模型
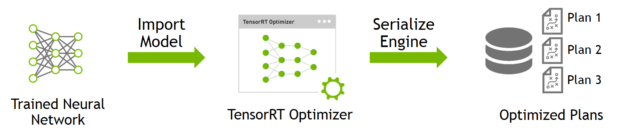
简单build demo
//创建一个builder
IBuilder* builder = createInferBuilder(gLogger);
// parse the caffe model to populate the network, then set the outputs
// 创建一个network对象,不过这时network对象只是一个空架子
INetworkDefinition* network = builder->createNetwork();
//tensorRT提供一个高级别的API:CaffeParser,用于解析Caffe模型
//parser.parse函数接受的参数就是上面提到的文件,和network对象
//这一步之后network对象里面的参数才被填充,才具有实际的意义
CaffeParser parser;
auto blob_name_to_tensor = parser.parse(“deploy.prototxt”,
trained_file.c_str(),
*network,
DataType::kFLOAT);
// 标记输出 tensors
// specify which tensors are outputs
network->markOutput(*blob_name_to_tensor->find("prob"));
// Build the engine
// 设置batchsize和工作空间,然后创建inference engine
builder->setMaxBatchSize(1);
builder->setMaxWorkspaceSize(1 << 30);
//调用buildCudaEngine时才会进行前述的层间融合或精度校准优化方式
ICudaEngine* engine = builder->buildCudaEngine(*network);
- deploy deploy阶段主要完成推理过程, 将上面一个步骤中的plan文件首先反序列化, 就可以输入数据(比如测试集或数据集之外的图片, 然后输出分类向量结果或检测结果。

简单build demo
// The execution context is responsible for launching the
// compute kernels 创建上下文环境 context,用于启动kernel
IExecutionContext *context = engine->createExecutionContext();
// In order to bind the buffers, we need to know the names of the
// input and output tensors. //获取输入,输出tensor索引
int inputIndex = engine->getBindingIndex(INPUT_LAYER_NAME),
int outputIndex = engine->getBindingIndex(OUTPUT_LAYER_NAME);
//申请GPU显存
// Allocate GPU memory for Input / Output data
void* buffers = malloc(engine->getNbBindings() * sizeof(void*));
cudaMalloc(&buffers[inputIndex], batchSize * size_of_single_input);
cudaMalloc(&buffers[outputIndex], batchSize * size_of_single_output);
//使用cuda 流来管理并行计算
// Use CUDA streams to manage the concurrency of copying and executing
cudaStream_t stream;
cudaStreamCreate(&stream);
//从内存到显存,input是读入内存中的数据;buffers[inputIndex]是显存上的存储区域,用于存放输入数据
// Copy Input Data to the GPU
cudaMemcpyAsync(buffers[inputIndex], input,
batchSize * size_of_single_input,
cudaMemcpyHostToDevice, stream);
//启动cuda核计算
// Launch an instance of the GIE compute kernel
context.enqueue(batchSize, buffers, stream, nullptr);
//从显存到内存,buffers[outputIndex]是显存中的存储区,存放模型输出;output是内存中的数据
// Copy Output Data to the Host
cudaMemcpyAsync(output, buffers[outputIndex],
batchSize * size_of_single_output,
cudaMemcpyDeviceToHost, stream));
//如果使用了多个cuda流,需要同步
// It is possible to have multiple instances of the code above
// in flight on the GPU in different streams.
// The host can then sync on a given stream and use the results
cudaStreamSynchronize(stream);
模型转化相关代码
- pytorch到onnx模型转换
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def model_converter():
model = torch.load('resnet50.pth').to(device) # 这里保存的是完整模型
model.eval()
dummy_input = torch.randn(1, 3, 96, 96, device=device)
input_names = ['data']
output_names = ['fc']
torch.onnx.export(model, dummy_input, 'resnet50.onnx',
export_params=True,
verbose=True,
input_names=input_names,
output_names=output_names)
- onnx模型转TensorRT模型
这里直接使用我们安装的TensorRT-7.0.0.11自带的工具进行转换,进入TensorRT-7.0.0.11/bin 目录,执行:
./trtexec --onnx=resnet50.onnx --saveEngine=resnet50.trt
或
/usr/src/tensorrt/bin/trtexec --onnx=*.onnx --fp16 --saveEngine=*.trt
简单模型推理
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import time
import cv2
TRT_LOGGER = trt.Logger()
def get_img_np_nchw(image):
image_cv = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_cv = cv2.resize(image_cv, (112, 112))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
img_np = np.array(image_cv, dtype=float) / 255.
img_np = (img_np - mean) / std
img_np = img_np.transpose((2, 0, 1))
img_np_nchw = np.expand_dims(img_np, axis=0)
return img_np_nchw
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
super(HostDeviceMem, self).__init__()
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream() # pycuda 操作缓冲区
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes) # 分配内存
bindings.append(int(device_mem))
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
def get_engine(engine_file_path=""):
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs] # 将输入放入device
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle) # 执行模型推理
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs] # 将预测结果从缓冲区取出
stream.synchronize() # 线程同步
return [out.host for out in outputs]
def postprocess_the_outputs(h_outputs, shape_of_output):
h_outputs = h_outputs.reshape(*shape_of_output)
return h_outputs
def landmark_detection(image_path):
trt_engine_path = './models/landmark_detect_106.trt'
engine = get_engine(trt_engine_path)
context = engine.create_execution_context()
inputs, outputs, bindings, stream = allocate_buffers(engine)
image = cv2.imread(image_path)
image = cv2.resize(image, (112, 112))
img_np_nchw = get_img_np_nchw(image)
img_np_nchw = img_np_nchw.astype(dtype=np.float32)
inputs[0].host = img_np_nchw.reshape(-1)
t1 = time.time()
trt_outputs = do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
t2 = time.time()
print('used time: ', t2-t1)
shape_of_output = (1, 212)
landmarks = postprocess_the_outputs(trt_outputs[1], shape_of_output)
landmarks = landmarks.reshape(landmarks.shape[0], -1, 2)
height, width = image.shape[:2]
pred_landmark = landmarks[0] * [height, width]
for (x, y) in pred_landmark.astype(np.int32):
cv2.circle(image, (x, y), 1, (0, 255, 255), -1)
cv2.imshow('landmarks', image)
cv2.waitKey(0)
return pred_landmark
if __name__ == '__main__':
image_path = './images/3766_20190805_12_10.png'
landmarks = landmark_detection(image_path)
pytorch转tensorRT步骤
- 转换流程
- 使用pytorch训练得到pt文件;
- 将pt文件转换为onnx中间件;
- 使用onnxsim.simplify对转换后的onnx进行简化;
- 解析onnx文件构建trt推理引擎;
- 加载引擎执行推理,为引擎输入、输出、模型分配空间;
- 将待推理的数据(预处理后的img数据)赋值给inputs(引擎输入);
- 执行推理,拿到outputs;
- 对outputs后处理,根据构建引擎时的格式取出输出,reshape到指定格式(和torch推理后的格式一样);
- 然后知道该怎么做了吧。
- 部署整体流程
- 导出网络定义以及相关权重;
- 解析网络定义以及相关权重;
- 根据显卡算子构造出最优执行计划;
- 将执行计划序列化存储;
- 反序列化执行计划;
- 进行推理
转化例子
import sys
sys.path.append('yolov5')
from models.common import *
from utils.torch_utils import *
from utils.datasets import *
from yolo import *
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import time
import copy
import numpy as np
import os
from onnxsim import simplify
import onnx
import struct
import yaml
import torchvision
device = select_device('0') # cuda
weights = 'yolov5s.pt' # 权重
model_config = 'yolov5s.yaml' # 模型yaml
TRT_LOGGER = trt.Logger(trt.Logger.INFO) # 需要这个记录器来构建一个引擎
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
image_loader = LoadImages('yolov5/inference/images', img_size=640) # 推理文件夹
image_loader.__iter__()
_, input_img, _, _ = image_loader.__next__() # 迭代图片输入
input_img = input_img.astype(np.float) # 输入图片
input_img /= 255.0
input_img = np.expand_dims(input_img, axis=0)
with open(model_config) as f:
cfg = yaml.load(f, Loader=yaml.FullLoader) # model dict 模型加载
num_classes = cfg['nc']
# nms config
conf_thres = 0.4
iou_thres = 0.5
max_det = 300
# nms GPU
topK = 512 # max supported is 4096, if conf_thres is low, such as 0.001, use larger number.
keepTopK = max_det
def GiB(val):
return val * 1 << 30
# different from yolov5/utils/non_max_suppression, xywh2xyxy(x[:, :4]) is no longer needed (contained in Detect())
def non_max_suppression(prediction, conf_thres=0.1, iou_thres=0.6, merge=False, classes=None, agnostic=False):
"""Performs Non-Maximum Suppression (NMS) on inference results
这个是yolov5的nms处理部分,不是trt处理的,可以不用理
Returns:
detections with shape: nx6 (x1, y1, x2, y2, conf, cls)
"""
if prediction.dtype is torch.float16:
prediction = prediction.float() # to FP32
nc = prediction[0].shape[1] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height
max_det = 300 # maximum number of detections per image
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label = nc > 1 # multiple labels per box (adds 0.5ms/img)
t = time.time()
output = [None] * prediction.shape[0]
for xi, x in enumerate(prediction): # image index, image inference
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
x = x[xc[xi]] # confidence
# If none remain process next image
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = x[:, :4] #xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero().t()
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True)
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres]
# Filter by class
if classes:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# If none remain process next image
n = x.shape[0] # number of boxes
if not n:
continue
# Sort by confidence
# x = x[x[:, 4].argsort(descending=True)]
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores
i = torchvision.ops.boxes.nms(boxes, scores, iou_thres)
if i.shape[0] > max_det: # limit detections
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
try: # update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
except: # possible CUDA error https://github.com/ultralytics/yolov3/issues/1139
print(x, i, x.shape, i.shape)
pass
output[xi] = x[i]
if (time.time() - t) > time_limit:
break # time limit exceeded
return output
def load_model(): # 模型加载
# Load model
model = Model(model_config)
ckpt = torch.load(weights, map_location=torch.device('cpu'))
ckpt['model'] = \
{k: v for k, v in ckpt['model'].state_dict().items() if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(ckpt['model'], strict=False)
model.eval()
return model
def export_onnx(model, batch_size): # 模型转onnx
_,_,x,y = input_img.shape
img = torch.zeros((batch_size, 3, x, y))
torch.onnx.export(model, (img), 'yolov5_{}.onnx'.format(batch_size),
input_names=["data"], output_names=["prediction"], verbose=True, opset_version=11, operator_export_type=torch.onnx.OperatorExportTypes.ONNX
)
def simplify_onnx(onnx_path): # onnx模型简化
model = onnx.load(onnx_path)
model_simp, check = simplify(model)
assert check, "Simplified ONNX model could not be validated"
onnx.save(model_simp, onnx_path)
def build_engine(onnx_path, using_half):
"""
ONNX模型转换为trt序列化模型
Args:
onnx_path:
using_half:
Returns:
"""
trt.init_libnvinfer_plugins(None, '')
engine_file = onnx_path.replace(".onnx", ".engine")
if os.path.exists(engine_file): # 存在序列化文件直接加载返回,否则构建引擎
with open(engine_file, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_batch_size = 1 # always 1 for explicit batch
config = builder.create_builder_config()
config.max_workspace_size = GiB(1)
if using_half:
config.set_flag(trt.BuilderFlag.FP16)
# Load the Onnx model and parse it in order to populate the TensorRT network.
with open(onnx_path, 'rb') as model:
if not parser.parse(model.read()):
print ('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print (parser.get_error(error))
return None
previous_output = network.get_output(0)
network.unmark_output(previous_output)
# slice boxes, obj_score, class_scores
strides = trt.Dims([1,1,1])
starts = trt.Dims([0,0,0])
bs, num_boxes, _ = previous_output.shape
shapes = trt.Dims([bs, num_boxes, 4])
boxes = network.add_slice(previous_output, starts, shapes, strides)
starts[2] = 4
shapes[2] = 1
obj_score = network.add_slice(previous_output, starts, shapes, strides)
starts[2] = 5
shapes[2] = num_classes
scores = network.add_slice(previous_output, starts, shapes, strides)
indices = network.add_constant(trt.Dims([num_classes]), trt.Weights(np.zeros(num_classes, np.int32)))
gather_layer = network.add_gather(obj_score.get_output(0), indices.get_output(0), 2)
# scores = obj_score * class_scores => [bs, num_boxes, nc]
updated_scores = network.add_elementwise(gather_layer.get_output(0), scores.get_output(0), trt.ElementWiseOperation.PROD)
# reshape box to [bs, num_boxes, 1, 4]
reshaped_boxes = network.add_shuffle(boxes.get_output(0))
reshaped_boxes.reshape_dims = trt.Dims([0,0,1,4])
# add batchedNMSPlugin, inputs:[boxes:(bs, num, 1, 4), scores:(bs, num, 1)]
trt.init_libnvinfer_plugins(TRT_LOGGER, "")
registry = trt.get_plugin_registry()
assert(registry)
creator = registry.get_plugin_creator("BatchedNMS_TRT", "1")
assert(creator)
fc = []
fc.append(trt.PluginField("shareLocation", np.array([1], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("backgroundLabelId", np.array([-1], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("numClasses", np.array([num_classes], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("topK", np.array([topK], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("keepTopK", np.array([keepTopK], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("scoreThreshold", np.array([conf_thres], dtype=np.float32), trt.PluginFieldType.FLOAT32))
fc.append(trt.PluginField("iouThreshold", np.array([iou_thres], dtype=np.float32), trt.PluginFieldType.FLOAT32))
fc.append(trt.PluginField("isNormalized", np.array([0], dtype=np.int), trt.PluginFieldType.INT32))
fc.append(trt.PluginField("clipBoxes", np.array([0], dtype=np.int), trt.PluginFieldType.INT32))
fc = trt.PluginFieldCollection(fc)
nms_layer = creator.create_plugin("nms_layer", fc)
layer = network.add_plugin_v2([reshaped_boxes.get_output(0), updated_scores.get_output(0)], nms_layer)
layer.get_output(0).name = "num_detections"
layer.get_output(1).name = "nmsed_boxes"
layer.get_output(2).name = "nmsed_scores"
layer.get_output(3).name = "nmsed_classes"
for i in range(4):
network.mark_output(layer.get_output(i))
return builder.build_engine(network, config)
def allocate_buffers(engine, is_explicit_batch=False, dynamic_shapes=[]):
# 分配缓冲区,这一步是通用的
inputs = []
outputs = []
bindings = []
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
for binding in engine:
dims = engine.get_binding_shape(binding)
print(dims)
if dims[0] == -1:
assert(len(dynamic_shapes) > 0)
dims[0] = dynamic_shapes[0]
size = trt.volume(dims) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings
def profile_trt(engine, batch_size, num_warmups=10, num_iters=100): # trt推理
assert(engine is not None)
input_img_array = np.array([input_img] * batch_size) # 输入
yolo_inputs, yolo_outputs, yolo_bindings = allocate_buffers(engine, True) # 内存分配
stream = cuda.Stream() # pycuda 操作缓冲区
with engine.create_execution_context() as context:
total_duration = 0.
total_compute_duration = 0.
total_pre_duration = 0.
total_post_duration = 0.
for iteration in range(num_iters):
pre_t = time.time()
# set host data
img = torch.from_numpy(input_img_array).float().numpy()
yolo_inputs[0].host = img # 输入赋值到inputs
# Transfer data from CPU to the GPU. 将数据从CPU转移到GPU。
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in yolo_inputs]
# 线程同步
stream.synchronize()
start_t = time.time()
# 执行模型推理
context.execute_async_v2(bindings=yolo_bindings, stream_handle=stream.handle)
stream.synchronize()
end_t = time.time()
# Transfer predictions back from the GPU.从GPU传回的传输预测。
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in yolo_outputs]
stream.synchronize()
post_t = time.time()
duration = post_t - pre_t
compute_duration = end_t - start_t
pre_duration = start_t - pre_t
post_duration = post_t - end_t
if iteration >= num_warmups:
total_duration += duration
total_compute_duration += compute_duration
total_post_duration += post_duration
total_pre_duration += pre_duration
print("avg GPU time: {}".format(total_duration/(num_iters - num_warmups)))
print("avg GPU compute time: {}".format(total_compute_duration/(num_iters - num_warmups)))
print("avg pre time: {}".format(total_pre_duration/(num_iters - num_warmups)))
print("avg post time: {}".format(total_post_duration/(num_iters - num_warmups)))
# 取出outputs,reshape成输出格式
num_det = int(yolo_outputs[0].host[0, ...])
boxes = np.array(yolo_outputs[1].host).reshape(batch_size, -1, 4)[0, 0:num_det, 0:4]
scores = np.array(yolo_outputs[2].host).reshape(batch_size, -1, 1)[0, 0:num_det, 0:1]
classes = np.array(yolo_outputs[3].host).reshape(batch_size, -1, 1)[0, 0:num_det, 0:1]
return [np.concatenate([boxes, scores, classes], -1)]
def profile_torch(model, using_half, batch_size, num_warmups=10, num_iters=100): # 正常的torch推理,这一步主要是和trt推理做个对比
model.to(device)
total_duration = 0.
total_compute_duration = 0.
total_pre_duration = 0.
total_post_duration = 0.
if using_half:
model.half()
for iteration in range(num_iters):
pre_t = time.time()
# set host data
img = torch.from_numpy(input_img).float().to(device)
if using_half:
img = img.half()
start_t = time.time()
_ = model(img)
output = non_max_suppression(_[0], conf_thres, iou_thres)
end_t = time.time()
[i.cpu() for i in _]
post_t = time.time()
duration = post_t - pre_t
compute_duration = end_t - start_t
pre_duration = start_t - pre_t
post_duration = post_t - end_t
if iteration >= num_warmups:
total_duration += duration
total_compute_duration += compute_duration
total_post_duration += post_duration
total_pre_duration += pre_duration
print("avg GPU time: {}".format(total_duration/(num_iters - num_warmups)))
print("avg GPU compute time: {}".format(total_compute_duration/(num_iters - num_warmups)))
print("avg pre time: {}".format(total_pre_duration/(num_iters - num_warmups)))
print("avg post time: {}".format(total_post_duration/(num_iters - num_warmups)))
return [output[0].cpu().numpy()]
if __name__ == '__main__':
batch_size = 1 # only works for TRT. perf reported by torch is working on non-batched data.
using_half = False
onnx_path = 'yolov5_{}.onnx'.format(batch_size)
with torch.no_grad():
model = load_model() # 模型加载
export_onnx(model, batch_size) # 转onnx
simplify_onnx(onnx_path) # onnx简化
trt_result = profile_trt(build_engine(onnx_path, using_half), batch_size, 10, 100) # trt推理
if using_half:
model.half()
torch_result = profile_torch(model, using_half, batch_size, 10, 100) # torch推理
print(trt_result)
print(torch_result)
本文来自博客园,作者:InsiApple,转载请注明原文链接:https://www.cnblogs.com/InsiApple/p/16624517.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号