MySQL逻辑架构和SQL执行流程
1. MySQL逻辑架构
# 1. 逻辑架构剖析图解 #1.1 服务器处理客户端请求 #首先MySQL是典型的C/S 架构,即 Client/Server 架构,服务器端程序使用的mysqld。 #不论客户端进程和服务器进程是采用哪种方式进行通信,最后实现的效果都是: #客户端进程向服务器进程发送一段文本(SQL语句),服务器进程处理后再向客户端进程发送一段文本(处理结果); #服务器进程对客户端进程发送的请求做了什么处理,才能产生最后的处理结果呢?这里以查询请求为例展示:
简图

经典图

具体说明:
#① Connectors
#指的是不同语言中与SQL的交互,MySQL首先是一个网络程序,在TCP之上定义了自己的应用层协议。
#所以要使用MySQL,我们可以编写代码,跟MySQL Server建立TCP连接,之后按照其定义好的协议进行交互。
#或者比较方便的办法是调用SDK,比如:Native C API、JDBC、PHP等各语言MySQL Connector,或者通过ODBC。
#但通过SDK来访问MySQL,本质上还是在TCP连接上通过MySQL协议跟MySQL进行交互。
#② MySQL Server结构可以分为如下的三层:
![]()

#②.1 连接层 #系统(客户端)访问MySQL服务器前,做的第一件事局势建立TCP连接。 #经过三次握手建立连接成功后,MySQL服务器对TCP传输过来的账号密码做身份认证、权限获取。 #用户名或密码不正确,会收到一个Access denied for user 错误,客户端程序结束执行 #用户名密码认证通过,会从权限表查出账号拥有的权限 与连接关联,之后的权限判断逻辑,都将依赖于此时读到的权限 #接着我们来思考一个问题 #一个系统只会和MySQL服务器建立一个连接吗?只能有一个系统和MySQL服务器建立连接吗? #当然不是,多个系统都可以和MySQL服务器建立连接,每个系统建立的连接肯定不止一个。 #所以,为了解决TCF无限创建与TCP频繁创建销毁带来的资源耗尽、性能下降问题。 #MySOL服务器里有专门的 TCP连接池 限制连接数采用 长连接模式 复用TCP连接,来解决上述问题。
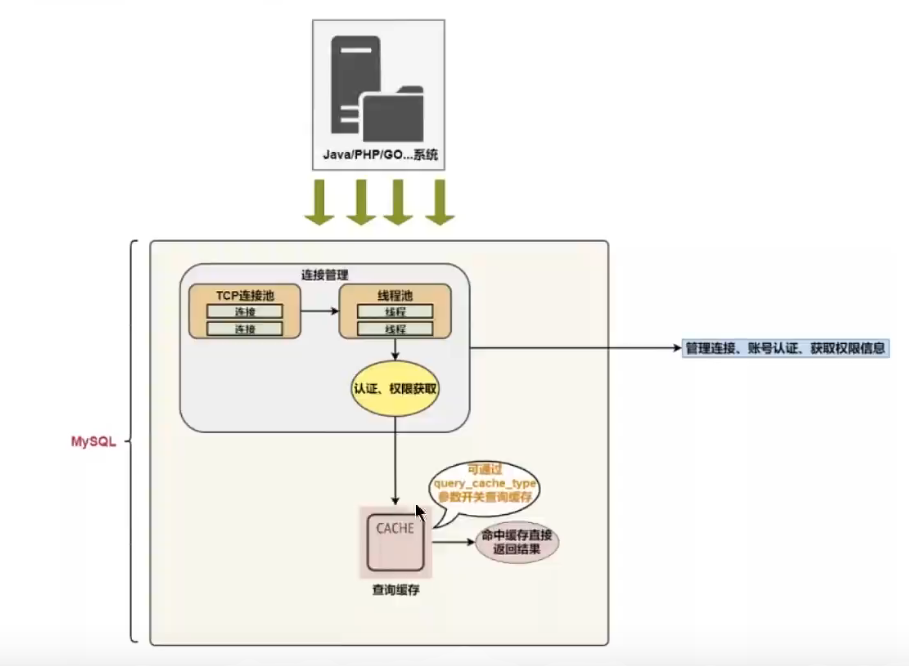
#TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后面的流程。 #每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。 #这些内容我们都归纳到 MySQL 的连接管理组件中。 #所以连接管理的职责是负责认证、管理连接、获取权限信息。 #②.2 服务层 #SQL Interface: SQL接囗 #接收用户的SQL命令,并且返回用户需要查询的结果。比如SELECT..FROM就是调用SQLInterface #MySQL支持DML(数据操作语言)、DDL(数据定义语言)、存储过程、视图、触发器、自定义函数等多种SQL语言接口 #Parser: 解析器 #在解析器中对 SOL语句进行语法分析、语义分析。将SOL语句分解成数据结构,并将这个结构传递到后续步骤, #以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个SQL语句是不合理的。 #在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建 语法树,并根据数据字典丰富查询语D法树, #会验证该客户端是否具有执行该查询的权限。创建好语法树后,MySQL还会对SQI查询进行语法上的优化,进行查询重写。

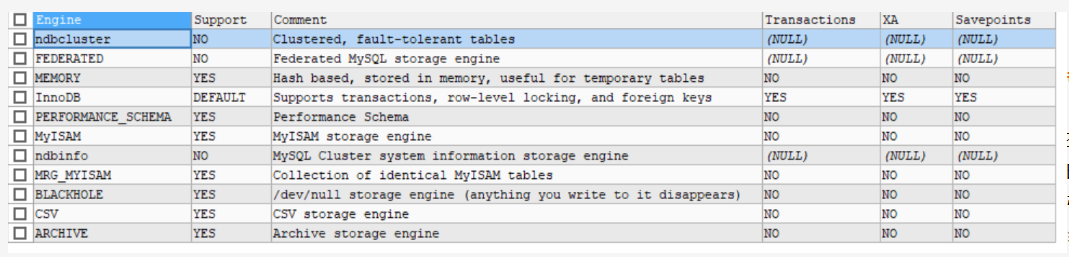
#Optimizer: 查询优化器 #SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL语句的执行路径,生成一个 执行计划。 #这个执行计划表明应该 使用哪些索引 进行査询(全表检索还是使用索引检索),表之间的连接顺序如何 #最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。 #它使用“ 选取-投影-连接”策略进行查询。例如: SELECT id,NAME FROM student WHERE gender ='女'; #这个SELECT查询先根据WHERE语句进行 选取,而不是将表全部查询出来以后再进行gender过滤。 #这个SELECT查询先根据id和name进行属性 投影,而不是将属性全部取出以后再进行过滤,将这两个查询 #条件 连接 起来生成最终查询结果。 #Caches & Buffers: 查询缓存组件 #MySQL内部维持着一些cache和Bufer,比如Query Cache用来缓存一条SELECT语句的执行结果, #如果能够在其中找到对应的查询结果,那么就不必再进行查询解析、 #优化和执行的整个过程了,直接将结果反馈给客户端。 #这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等 #这个查询缓存可以在 不同客户端之间共享 #从MySQL5.7.20开始,不推荐使用查询缓存,并在MySQL8.8中删除, #②.3 引擎层 #和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用, #主要体现在存储引擎的架构上,插件式的存储引擎 架构将査询处理和其它的系统任务以及数据的存储提取相分离。 #这种架构可以根据业务的需求和实际需要选择合适的存储引擎。 同时开源的 MSOL 还允许 开发人员设置自己的存储引擎。 #这种高效的模块化架构为那些希望专门针对特定应用程序需求(例如数据仓库、事务处理或高可用性情况)的人提供了巨大的好处, #同时享受使用一组独立于任何接口和服务的优势存储引擎。 #插件式存储引擎层(Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作, #服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取。 #查看MySQL支持的存储引擎有哪些 SHOW ENGINES;
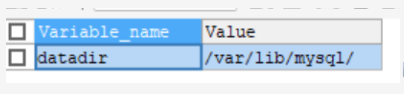
#③ 存储层 #所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在文件系统上,以文件的方法存在的,并完成与存储引擎的交互。 #当然有些存储引擎比如InnoDB, 也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。 #在文件系统之下,可以使用本地磁盘,可以使用DAS、NAS、SAN等各种存储系统。 #查询文件系统保存位置 SHOW VARIABLES LIKE '%datadir%';
2. SQL执行流程
了解次内容,对于后期索引和优化器很重要。
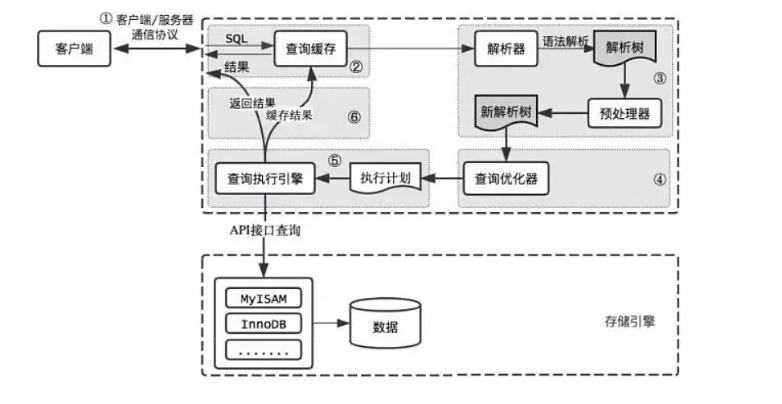
#① 查询缓存 #Server 如果在查询缓存中发现了这条SQL语句,就会直接将结果(key-value结构)返回给客户端;如果没有,就进入到解析器阶段。 #需要说明的是,因为查询缓存往往效率不高,所以在MySQL8.0之后就抛弃了这个功能。
#② 解析器
#在解析器中对SQL语句进行语法分析、语义分析
![]()

#③ 优化器
#在优化器中会确定SQL语句的执行路径,比如是根据 全表检索,还是根据 索引检索等。
![]()

#经过了解析器,MySQL就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
#一条查询可以有很多执行方式,最后都会返回相同的结果。
#优化器的作用就是找到这其中最好的执行计划。
![]()

#④ 执行器
#在执行之前需要判断该用户是否具备权限。如果没有,就会返回权限错误。如果具备权限,就执行SQL
#查询并返回结果。在MySQL8.0以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
![]()

#如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,调用存储引擎API对表进行
#读写。存储引擎API只是抽象接口,下面还有个存储引擎层,具体实现还是要看表选择的存储引擎。
![]()
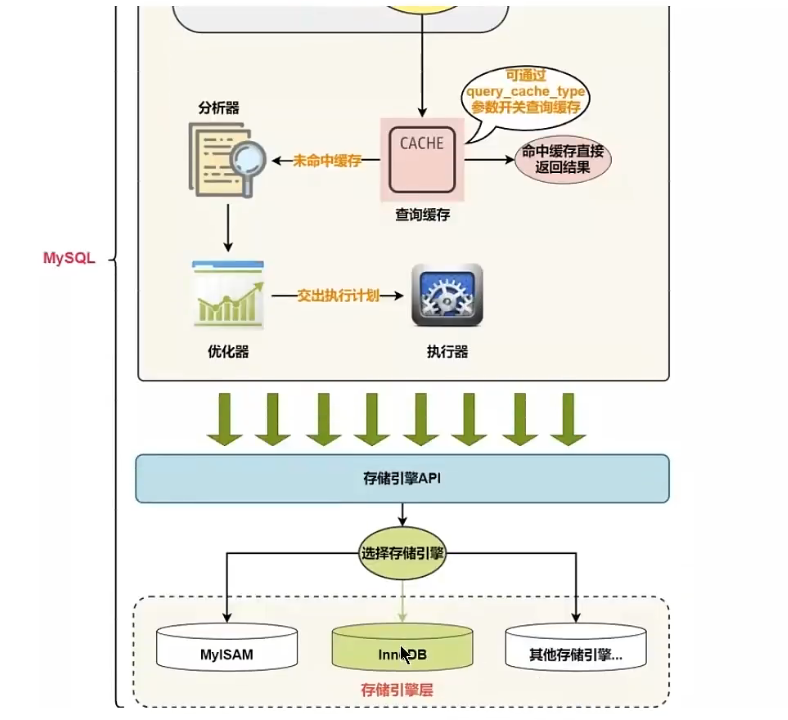
SQL执行流程

3. MySQL8.0 中SQL 执行原理(执行时间进行分析)
#SQL的执行原理,不同的DBMS的SQL的执行原理是想通的,只是在不同的软件中,各有各的实现路径
#既然一条SQL语句会经历不同的模块,那我们就来看下,在不同的模块中,SQL执行所使用的资源(时间)
#是怎么样的。如何在MySQL中对一条SQL语句的执行时间进行分析。
#3.1 开启profiling 是否开启
SELECT @@profiling;
![]()

#或者
SHOW VARIABLES LIKE '%profiling%';

#3.2 相关查询语句
SHOW PROFILES;
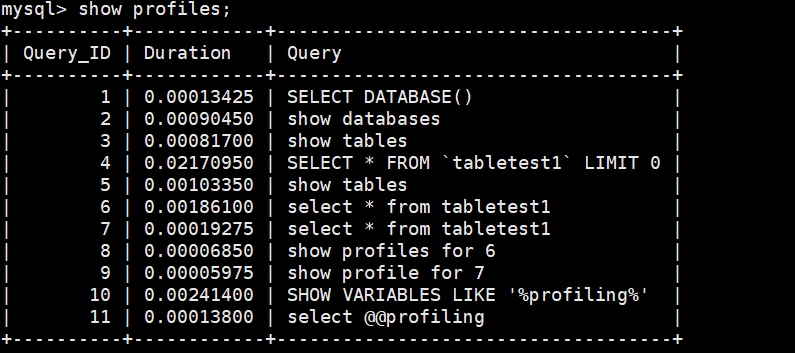
SHOW PROFILE FOR QUERY 7;
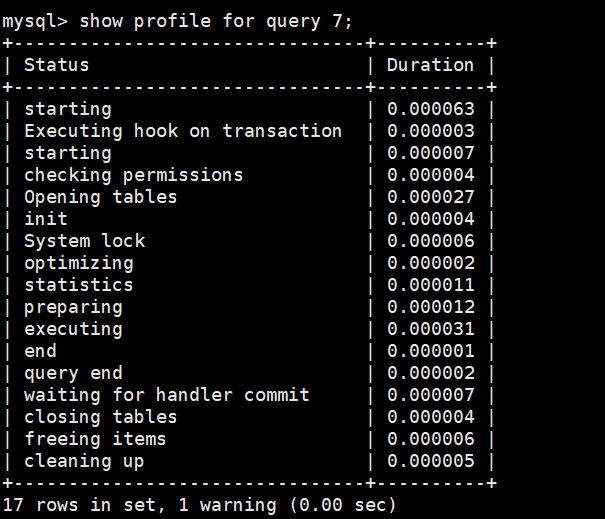
-----------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号