


Debezium实现多数据源迁移(一)
背景:
某公司有三个数据库,分别为MySql、Oracle和PostgreSql。原有业务的数据都是来自于这三个DB,此处委托将原有的三个数据库整合成一个Mysql。
要求:
1.不影响原有系统的继续使用。
2.原有数据迁移至新的数据库。
3.新的Mysql中的同一张表的数据可能来自不同的数据库,举个例子:PostgreSql:User(name),Oracle:User(age)——》Mysql:User(name,age)。
架构:
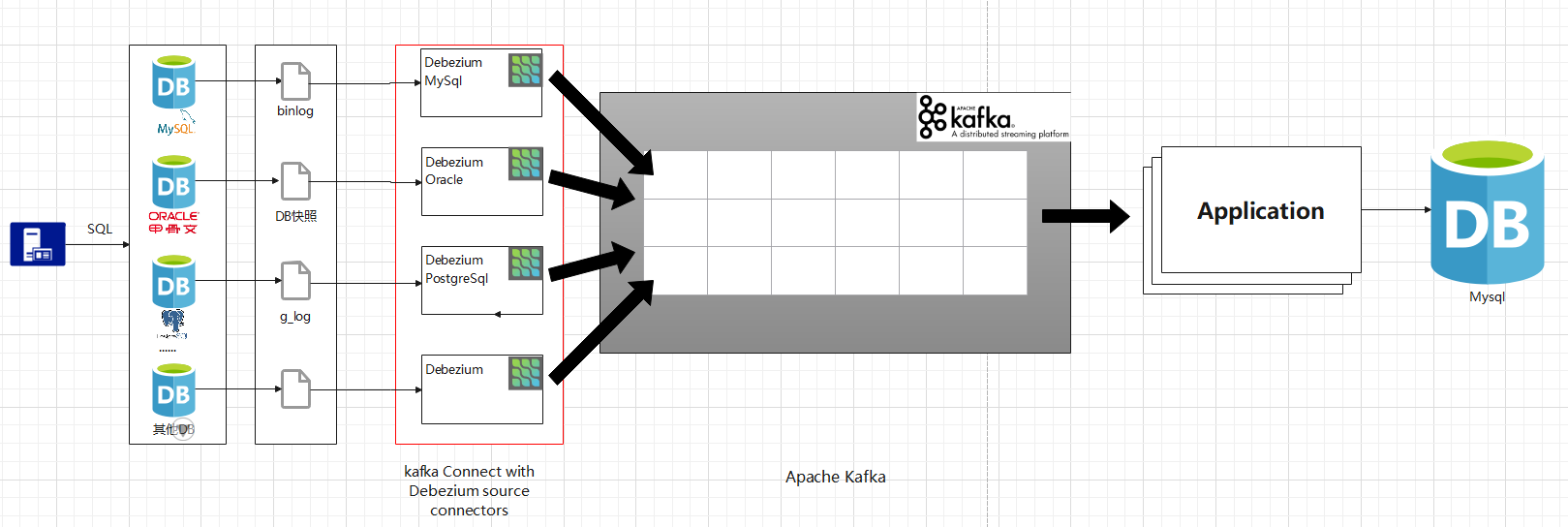
(涉及内部服务器,由本地简单搭建演示记录这一过程)
一、基于Docker搭建Debezium环境
(1).搭建zookeeper
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
(2).搭建kafka
docker run -d --name kafka -p 9092:9092 -p 8083:8083 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=<IP地址>:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT:// <IP地址>:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v C:\data_share:/home/data wurstmeister/kafka
tips:
<IP地址>全文对应同一个
1. 留8083端口为后续kafka-connect暴力Api使用。
2. -v 预留数据卷,共享kafka-connect扩展,方便上传扩展包。
3. <IP地址>保证Api可访问,zookeeper和kafka间有IP认证。如:zk和kafka用服务器内网IP,但当使用外网IP访问kafka时会认证不过,见zk官网。
(3).准备kafka-connect集群启动文件
修改/opt/kafka/config/connect-distributed.properties
#kafka集群
bootstrap.servers=<IP地址1>:9092,<IPd地址2>:9092
#Api的端口 rest.port=8083 #用于其他worker连接 rest.advertised.host.name=<IP地址> rest.advertised.port=8083
#消息只要payload,<选择性设置>
key.converter.schemas.enable=false
value.converter.schemas.enable=false
#kafka-connect的扩展路径,指向kafka预留的 -v C:\data_share:/home/data
plugin.path=/home/data
(4).添加kafka-connect的Debezium扩展包 (以Mysql为例)
MySql本地版本5.7+,下载MySQLConnector plug-in,解压缩到为kafka预留的数据卷映射地址 C:\data_share
https://debezium.io/releases/1.5/


(5). 启动connect集群
./opt/kafka/bin/connect-distributed.sh ../config/connect-distributed.properties
检测是否成功:
./kafka-topic.sh --bootstrap-server <IP地址>:9092 --list

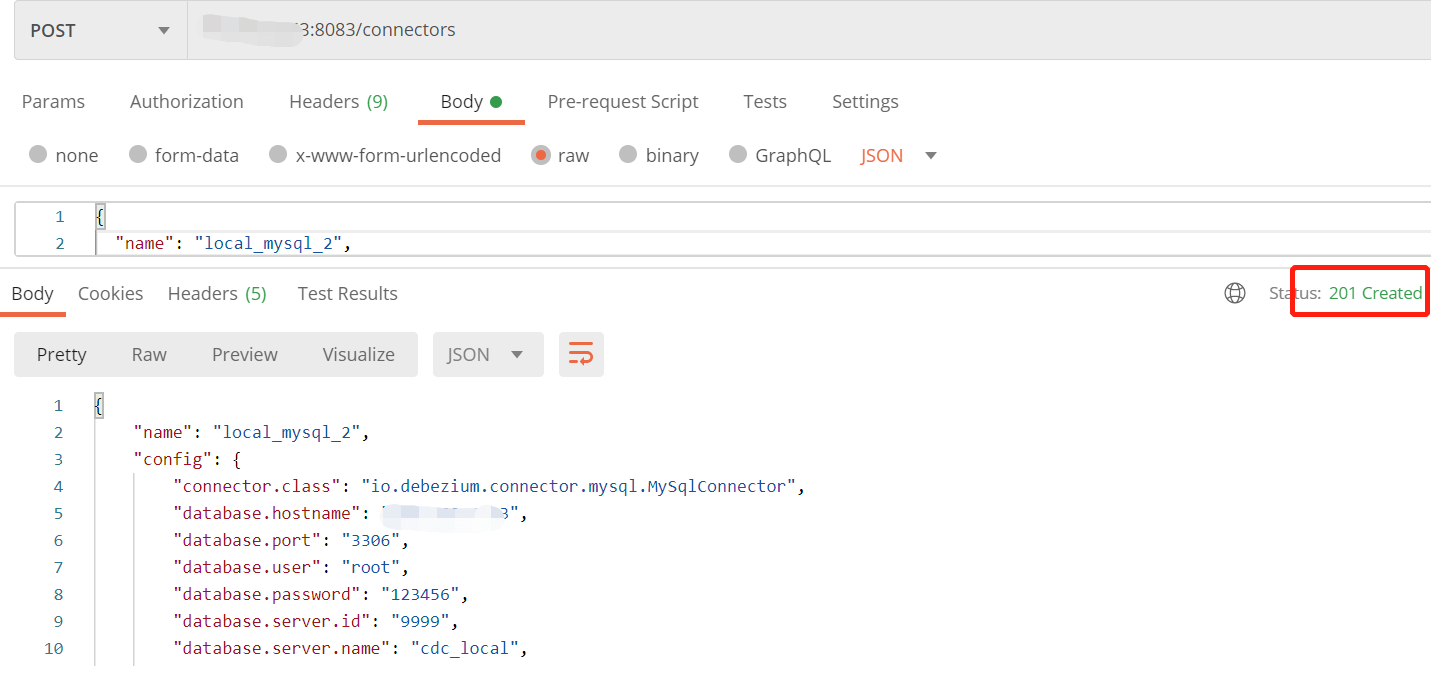
(6).调用Connect 配置连接属性
使用Postman 发送Post请求创建Connect 路径 <IP地址>:8083/connectors
(如有多个数据库源,创建多个Connect,保证name唯一)
请求体Json:
{ "name": "local_mysql", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.hostname": "127.0.0.1", "database.port": "3306", "database.user": "root", "database.password": "123456", "database.server.id": "9999", "database.server.name": "cdc_local", "database.whitelist": "inventory", "database.history.kafka.bootstrap.servers": "<IP地址>:9092", "database.history.kafka.topic": "history.local.inventory", "include.schema.changes": "true" }}
#name 创建的连接名
#config 配置信息
#connector.class 连接器类
#database.hostname 需要捕获的数据库地址
#database.port 数据库端口
#database.server.id 服务id(保证唯一)
#database.server.name 服务名,会加在topic前面 如下:cdc_local.inventory.orders
#database.whitelist 监听的数据库 ","分割
#database.history.kafka.bootstrap.servers kafka地址
#database.history.kafka.topic 连接器将使用此代理(向其发送事件的代理)和主题名称在Kafka中存储数据库架构的历史记录。重新启动后,连接器将恢复binlog连接器应开始读取的时间点上存在的数据库的架构
#include.schema.changes 是否包含表的改变
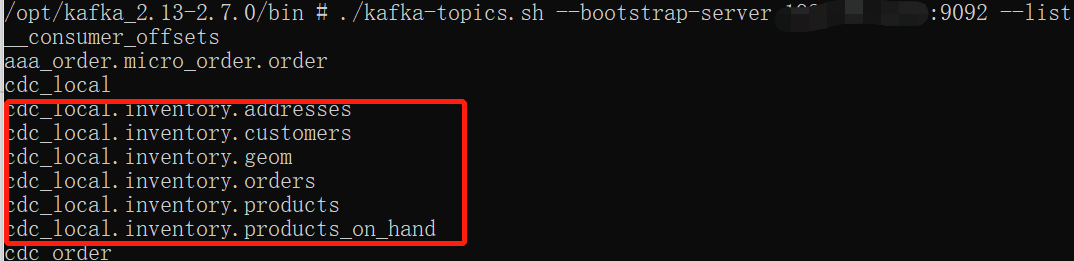
查看kafka-topic.sh
./kafka-topics.sh --bootstrap-server <IP地址>:9092 --list

 浙公网安备 33010602011771号
浙公网安备 33010602011771号