运维三剑客之grep、sed、awk
grep
Linux grep 命令用于查找文件里符合条件的字符串。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
| 参数 | 描述 |
|---|---|
| -a 或 --text | 不要忽略二进制的数据。 |
| -A<显示行数> 或 --after-context=<显示行数> | 除了显示符合范本样式的那一列之外,并显示该行之后的内容。 |
| -b 或 --byte-offset | 在显示符合样式的那一行之前,标示出该行第一个字符的编号。 |
| -B<显示行数> 或 --before-context=<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前的内容。 |
| -c 或 --count | 计算符合样式的列数。 |
| -C<显示行数> 或 --context=<显示行数>或-<显示行数> | 除了显示符合样式的那一行之外,并显示该行之前后的内容。 |
| -d <动作> 或 --directories=<动作> | 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。 |
| -e<范本样式> 或 --regexp=<范本样式> | 指定字符串做为查找文件内容的样式。 |
| -E 或 --extended-regexp | 将样式为延伸的正则表达式来使用。 |
| -f<规则文件> 或 --file=<规则文件> | 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。 |
| -F 或 --fixed-regexp | 将样式视为固定字符串的列表。 |
| -G 或 --basic-regexp | 将样式视为普通的表示法来使用。 |
| -h 或 --no-filename | 在显示符合样式的那一行之前,不标示该行所属的文件名称。 |
| -H 或 --with-filename | 在显示符合样式的那一行之前,表示该行所属的文件名称。 |
| -i 或 --ignore-case | 忽略字符大小写的差别。 |
| -l 或 --file-with-matches | 列出文件内容符合指定的样式的文件名称。 |
| -L 或 --files-without-match | 列出文件内容不符合指定的样式的文件名称。 |
| -n 或 --line-number | 在显示符合样式的那一行之前,标示出该行的列数编号。 |
| -o 或 --only-matching | 只显示匹配PATTERN 部分。 |
| -q 或 --quiet或--silent | 不显示任何信息。 |
| -r 或 --recursive | 此参数的效果和指定"-d recurse"参数相同。 |
| -s 或 --no-messages | 不显示错误信息。 |
| -v 或 --revert-match | 显示不包含匹配文本的所有行。 |
| -V 或 --version | 显示版本信息。 |
| -w 或 --word-regexp | 只显示全字符合的列。 |
| -x --line-regexp | 只显示全列符合的列。 |
| -y | 此参数的效果和指定"-i"参数相同。 |
实战
-
查找当前目录下所有txt为扩展名的文件,并在文件内容中查找包含
javascript的行

-i表示不区分大小写,-n显示行号

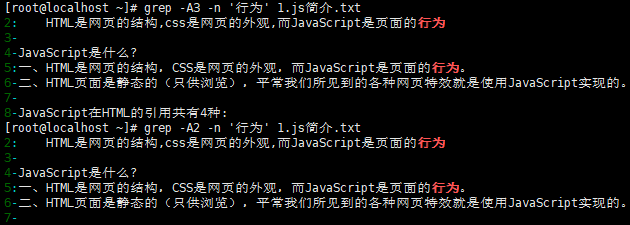
-
在文件内容中查找包含
行为的行,并显示该行之后的内容。(通过-A指定显示之后多少行,-B指定显示之前多少行,-C指定显示该行之前后的多少行)
-
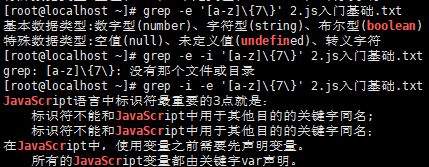
显示至少拥有7个小写字母的单词(-i不区分大小写)
-
以大小写字母开头的行(-e是正则表达式,-w精确查找)

简单举几个例子,更多的请man grep
sed
Linux sed 命令是利用脚本来处理文本文件。
sed 可依照脚本的指令来处理、编辑文本文件。
sed命令比较适用于大的文本文件,用普通文本编辑器难以胜任的情况。通常有打印、插入、删除、替换等编辑操作。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
| 参数 | 描述 |
|---|---|
| -e<script>或--expression=<script> | 以选项中指定的script来处理输入的文本文件。 |
| -f<script文件>或--file=<script文件> | 以选项中指定的script文件来处理输入的文本文件。 |
| -h或--help | 显示帮助。 |
| -n或--quiet或--silent | 仅显示script处理后的结果。 |
| -V或--version | 显示版本信息。 |
| 动作 | 描述 |
|---|---|
| a | 新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~ |
| c | 取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行! |
| d | 删除,因为是删除啊,所以 d 后面通常不接任何咚咚; |
| i | 插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行); |
| p | 打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~ |
| s | 取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦! |
实战
- 文件末尾追加内容
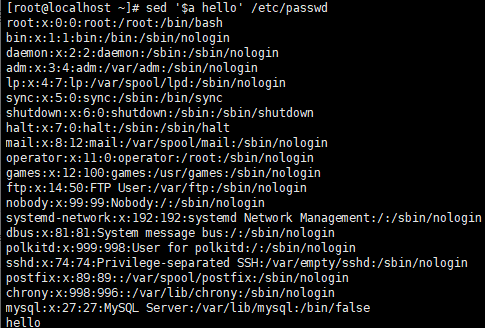
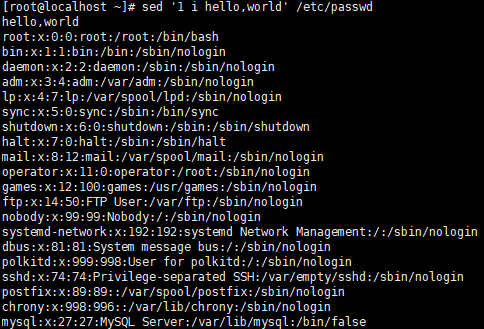
- 文件首行插入内容
- 删除1-3行

- 删除空白行
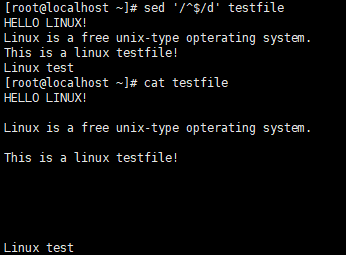
- 替换第一行内容
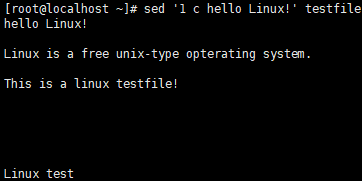
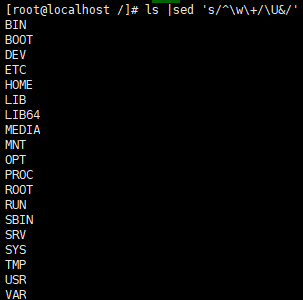
- 把当前目录名转换为大写(&表示替换前的全部内容)
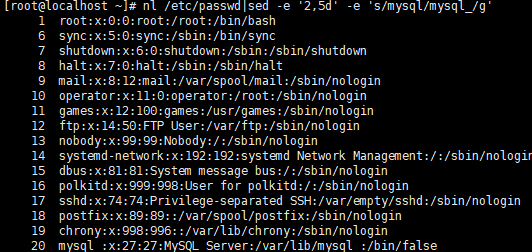
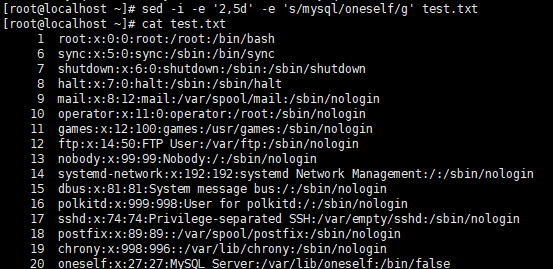
- 删除2-5行,将mysql替换成mysql(-e多点编辑)_
- 直接操作源文件(采用的测试文件)
总结:
- 打印时用-n 和p。
- 替换时用s 和g(全局)。
- \u \l:对首字母转大写、小写
- \U \L:对一串字符转大写、小写
- 替换语法:
sed 's/要替换的字符串/新的字符串/g'
awk
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。有读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等功能.
awk命令语法
awk '{pattern + action}' {filenames}
pattern就是要表示的正则表达式,用斜杠括起来; 随后紧接着action脚本,如果action有多句则用分号分隔;最后紧接着文件名称.
awk内置函数
$n 当前记录的第n个字段,字段间由FS分隔。
$0 完整的输入记录。
ARGC 命令行参数的数目。
ARGIND 命令行中当前文件的位置(从0开始算)。
ARGV 包含命令行参数的数组。
CONVFMT 数字转换格式(默认值为%.6g)
ENVIRON 环境变量关联数组。
ERRNO 最后一个系统错误的描述。
FIELDWIDTHS 字段宽度列表(用空格键分隔)。
FILENAME 当前文件名。
FNR 同NR,但相对于当前文件。
FS 字段分隔符(默认是任何空格)。
IGNORECASE 如果为真,则进行忽略大小写的匹配。
NF 当前记录中的字段数。(第几行)
NR 当前记录数。(当前行总列数)
OFMT 数字的输出格式(默认值是%.6g)。
OFS 输出字段分隔符(默认值是一个空格)。
ORS 输出记录分隔符(默认值是一个换行符)。
RLENGTH 由match函数所匹配的字符串的长度。
RS 记录分隔符(默认是一个换行符)。
RSTART 由match函数所匹配的字符串的第一个位置。
SUBSEP 数组下标分隔符(默认值是\034)。
实战
-
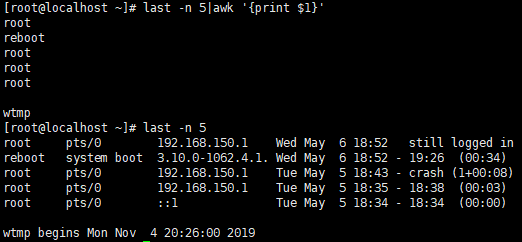
默认分隔符
默认分隔符为空格,$0则表示所有列,\(1表示第一个列,\)n表示第n个列。默认列分隔符是“空白键” 或 “[tab]键”,所以以下例子中:$1表示登录用户.
-
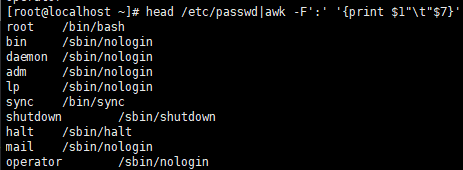
指定分隔符
使用-F参数指定分隔符.
-
BEGIN和END
任何在BEGIN之后列出的操作(在{}内)将在Unix awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号